연구 설계
Research designs
‘연구 설계’라는 문구가 언급될 때, 교육 연구 환경에서 자라온 많은 사람들은 자동적으로 실험 설계, 준실험 설계, 그리고 Cook과 Campbell을 떠올립니다.(13) 반면 임상 연구에 더 가까운 사람들은 사례-대조 연구, 코호트 연구, 그리고 무작위 임상 시험이라는 역학적 분류를 생각하는 경향이 있습니다. 그러나 이들 분류는 모두 불충분한 체계입니다. 의학교육에서, 특히 심리측정학적 연구와 상관관계 연구 방법론을 사용하는 양적 연구는 이러한 분류 체계에 명확하게 맞지 않습니다. 또한, 어떤 연구 전통을 채택할지는 연구자가 다루려는 특정 연구 질문에 맞추어져야 합니다.
더불어, 서로 다른 연구 설계 전통은 서로 다른 질문 유형에서 발생합니다. 이 장의 나머지 부분에서는 특정 연구 설계를 선택할 때 관련된 여러 가지 문제들을 살펴볼 것입니다.
- 다음 섹션에서는 실험 전통을 다루며, 주로 인과관계를 테스트하는 질문(예: '테스트 빈도의 증가가 학습한 자료의 더 나은 유지에 기여하는가?')에 초점을 맞춘 방법론을 탐구할 것입니다.
- 그 다음으로 잠시 다룰 전통은 역학적 접근입니다. 많은 방법론적 검토에서 연구 설계를 사례-대조 연구, 코호트 연구, 그리고 무작위 시험이라는 연속선으로 다루기 때문에, 이러한 용어들을 정의하고 의학교육에서의 제한된 적용 사례들을 보여줄 것입니다.
- 이후 섹션에서는 심리측정학 전통에 초점을 맞출 것입니다. 이 방법론은 (적어도 교육계 내에서는) 교육 과정의 다양한 측면이나 결과에 대한 더 나은 측정 도구를 개발하는 데 주로 사용됩니다. 이 연구들은 중재, 대조군, 결과 등과 같은 용어를 사용하지 않습니다. 대신, 연구의 주된 관심사는 신뢰도와 타당도와 같은 지표들로, 이는 측정 도구가 개인 간 차이를 방어할 수 있는 방식으로 구별하는 능력에 대한 지표입니다.
- 마지막으로 상관 연구 설계를 살펴볼 것입니다. 이는 측정된 변수 간의 관계를 조사함으로써 이해를 추구할 때 주로 사용됩니다. 이러한 측정은 종종 설문 조사나 평가 양식에서 수집되기 때문에, 우리는 또한 설문지 설계의 기본 원칙들에 대해 살펴볼 것입니다.
이 서론만 봐도 알 수 있듯이, 각각의 전통은 서로 다른 목표를 가지고 있으며, 하나의 설계 조건이 다른 설계와 상충될 수 있습니다. 예를 들어, 상관 연구는 관계를 보기 위해 개인의 변이가 필요하지만, 실험 연구는 개인 차이를 제거하려 노력하여 처리 효과를 탐지합니다. 다른 차이점도 있습니다. 실험 연구는 거의 정의상 전향적(prospective)인 반면, 상관 연구는 종종 기존 데이터베이스를 기반으로 수행됩니다. 기존 데이터를 사용하는 것은 종종 필요하지만, 사용할 수 있는 데이터가 질문을 주도하게 하여 이해 발전에 기여하지 않는 태도를 유발할 수 있습니다. 이러한 위험에도 불구하고, 특정 연구 접근법에만 독점적인 질문은 없습니다. 반대로, 가장 흥미로운 연구 중 일부는 대규모 기관 데이터베이스의 회고적 분석에서 발생했습니다.(14,15)
1 실험 전통
The experimental tradition
발견의 행위는, 앞서 논의한 바와 같이, 과학에서 중심적인 개념이며, 이는 종종 인과 관계를 식별하는 데 중점을 둡니다(변수들 간의 관계). 실험 전통은 이러한 의제를 대표합니다. 실험의 기본 개념은 독립 변수(일반적으로 실험자가 통제하는 변수)와 종속 변수(중재의 결과로 변화가 관찰되는 변수) 사이에 관계가 있다는 것입니다. 많은 방법론적 논의는 실험자가 통제하는 독립 변수와 관찰된 종속 변수 간의 인과 관계를 명확하게 추론할 수 있는 연구를 설계하는 데 중점을 둡니다. 다음과 같은 문장은 이러한 인과 관계의 목표를 보여줍니다:
• P32 핵이 중성자를 흡수하면 안정성이 감소하여 방사성 물질이 되며, β 입자를 방출하여 S32로 붕괴된다.
• 식단에서 나트륨 염분의 과잉 섭취는 고혈압을 유발하며, 이는 뇌졸중 위험을 증가시킨다.
• 일시적 허혈 발작을 겪은 환자들에게 제공된 반일 영양 워크숍은 제한된 염분 식단 준수율을 증가시켰다.
이러한 문장들은 모두 인과 관계를 암시하지만, 그중 어떤 것도 ‘원인(cause)’이라는 단어를 언급하지 않았습니다. 더욱이, 인과 관계의 의미는 상단에서 하단으로 갈수록 매우 다르며, 그 추론을 테스트하기 위해 필요한 단계들도 점점 더 복잡해집니다.
- 중성자의 경우 모호함이 없습니다. 원자 물리학자들은 중성자가 무엇인지, 중성자를 어떻게 만들고, 인(P) 핵이 그것을 흡수하도록 하는 방법을 잘 알고 있습니다. 중성자 표적을 100% 인으로 만드는 것은 비교적 간단합니다. β 입자를 감지하는 방법도 명확하고 잘 이해되어 있습니다. 게다가 그 관계는 절대적으로 인과적입니다. 만약 P 핵이 중성자를 흡수하면, 결국 β 입자를 방출하게 됩니다(반감기 14.28일이 알려져 있음); 흡수하지 않으면 방출하지 않습니다. 중성자를 받지 않은 다른 인 원자들의 대조군은 필요하지 않습니다. 과학 철학자들은 중성자나 β 입자의 실체를 의문시할 수 있지만, 물리학자들은 그들의 우려에 동의하지 않을 가능성이 큽니다.
- 마지막 인과 관계의 진술은 훨씬 더 모호합니다. 식단 준수를 명확하게 정의하는 것은 어렵고, ‘준수한’ 환자와 ‘준수하지 않은’ 환자를 명확하게 구분할 수 있는 기준점을 정의하려는 시도는 더욱 어렵습니다. 또한, 워크숍의 어떤 부분이 변화를 유도하는 인과 변수였는지 확인하는 것은 거의 불가능하며, 사실 워크숍에 참석한 모든 사람에게 단일 변수가 인과적 역할을 했을 가능성도 낮습니다. 만약 ‘인과’ 관계가 확인된다면, 이는 그저 변화를 유도한 ‘활성 성분’(또는 성분의 조합)을 규명하기 위한 추가 연구의 자극이 될 수 있습니다.
물론, 교육 연구의 대부분은 첫 번째 예시보다는 마지막 예시와 닮아 있습니다. 이는 교육에서 실험 연구의 역할을 이해하는 데 있어 두 가지 중요한 함의를 가집니다.
- 첫째, 물리 과학과는 달리, 우리가 찾는 관계는 필연적으로 확률적이며, 인과 관계의 신호는 거의 항상 잡음 속에서 움직입니다. 이러한 이유로 우리는 대조군, 무작위화, 그리고 포함 기준과 같은 전략을 적용해야 합니다.
- 둘째, 관계의 복잡성은 프로세스와 메커니즘을 이해하려는 진지한 시도를 방해할 수 있습니다. 실험이 법칙적인 인과 관계를 발견하는 데 목적을 두고 있으며 유용하다면, 교육에서 교육과정 수준의 개입에 초점을 맞추는 무작위 대조 시험(RCT)과 같은 실험 방법이 과용되고 있을 가능성이 있습니다.(17)
즉, 많은 최근의 리뷰에서 교육 내 좋은 무작위 시험의 부족을 비판하고 있지만,(8,18) 재현이 불가능할 정도로 개별성이 강한 개입에 대해 정교한 연구를 수행하는 것은 큰 의미가 없습니다.(19) 그럼에도 불구하고, 적절한 환경에서의 좋은 실험에서 배울 점은 많습니다.
연구 설계
Study designs
실험적 접근의 본질은 개입을 받은 한 집단과 개입을 받지 않은 다른 집단 간의 비교입니다. 이상적인 상황에서는 두 집단의 참여자들이 개입 전에는 가능한 한 동일하게 설정되며(이는 무작위화가 동등성을 달성하려는 노력으로 사용되는 이유입니다), 그렇게 해서 이후에 관찰된 차이는 개입 외에는 아무것도 원인으로 간주되지 않도록 합니다.
그러나, 비록 두 집단, 개입-대조 연구 설계가 널리 퍼져 있지만, 그것이 유일한 설계 방식은 아닙니다. 수십 년 전으로 거슬러 올라가는 연구 설계에 관한 책들은 점점 더 복잡해지는 많은 설계 방식을 설명해 왔으며,(20) 여기서는 그 중 일부 일반적인 변형을 논의할 것입니다.
단일 집단: 사전-사후 검사 및 사후 검사만
One group: Pre-test–post-test and post-test only
최근 의학교육에 대한 리뷰에서는 단일 집단 사전-사후 검사 설계가 가장 일반적으로 보고된 실험 방법론이었으며(105개의 연구 중 32%), 그 다음으로는 단일 집단 사후 검사만 설계(26%)가 뒤를 이었습니다.(8) 왜 이러한 설계가 일반적으로 사용되는지 쉽게 알 수 있습니다. 이 설계는 기존의 교육과정 또는 강의 변화에 쉽게 통합될 수 있습니다. 수업을 듣는 학생들에게 무언가를 가르치고, 그들의 능력을 시작과 끝에서 측정하는 것만 하면 됩니다. 반면에, 대조군과의 비교는 유사한 대조군을 자원자로 식별해야 하며, 이들은 가짜 개입을 받거나 아무 개입도 받지 않게 됩니다. 유감스럽게도, 단일 집단 설계는 Campbell과 Stanley에 의해 ‘사전 실험’으로 불리며(20) 과학적 가치는 매우 제한적입니다. 문제는 매우 많습니다. 논리적으로, 시작과 끝 사이에 관찰된 어떤 변화도 성숙, 공동 개입, 또는 다른 여러 타당한 설명과 같은 경쟁 가설에 의한 것이 아니라 개입에 의한 것이라고 주장할 수 있는 방법이 없습니다.
게다가, 이러한 논리적 결함이 국소적으로 보일 수 있지만, 더 근본적인 교육적 문제가 있습니다. 만약 개입 전후의 성과 변화를 보여준다면, 그 비교는 아무런 변화가 없는 것과 비교하는 것이며, 이는 전혀 교육이 이루어지지 않은 상태와 비교하는 것을 의미합니다. 예를 들어, 동종 요법이 어떠한 효과라도 있는지 확인하는 것은 유용할 수 있지만,(21) 한두 시간의 교육이 아무 교육도 받지 않은 경우보다 더 많은 학습 결과를 초래할 것이라고 가정할 수 있습니다. 그러나 항상 그렇지는 않습니다.(22) 결국, 학생들이 수업 후 무언가를 배웠다는 것을 보여주는 것은 수업의 특정한 측면이 얼마나 기여했는지를 아무것도 밝히지 않습니다.
두 집단: 무작위 대조 시험과 코호트 연구
Two groups: Randomised controlled trials and cohort studies
단일 집단 설계에서 인과 요인을 식별하는 어려움은 자연스럽게 무작위 대조 시험(RCT)으로 이어집니다. 표준 RCT는 참여자를 두 집단으로 무작위 배정하여 연구가 끝날 때 두 집단 간의 유일한 차이점이 하나의 집단은 개입을 받았고 다른 집단은 받지 않았거나, 두 번째 개입을 받았다는 점이어야 합니다(단, 우연한 변동은 예외). 무작위 배정은 시작 시 동등성을 보장하려는 것이며, 개입의 표준화는 해석을 용이하게 하고, 눈가림(blinding)은 편향을 피하며, 완전한 추적 관찰도 마찬가지로 편향을 방지합니다. 이런 방식으로 차이가 관찰되면, 이는 개입 자체로 인한 결과라고 확실히 말할 수 있습니다.
Box 25.3에 나와 있는 기준은 이해하기 쉽지만 실제로 적용하기는 훨씬 더 어렵습니다.
- 예를 들어, 무작위 배정과 같은 일부 측면은 비교적 쉽게 이루어질 수 있지만, 참가자들이 자신이 받은 교육 개입을 모르게 하는 눈가림은 사실상 불가능합니다.
- 예를 들어, 학생이 자신이 문제 기반 학습(PBL)을 받았는지 강의를 들었는지 모른다면, 우리는 그 학생 또는 그 개입, 혹은 둘 다에 대해 의심해볼 수 있습니다.
- 표준화는 약물에서는 쉽지만 교육과정에서는 어렵습니다. 예를 들어, 하루 세 번 300mg의 PBL은 어떻게 생겼을까요? 일반적으로 교사의 차이가 교육 과정의 차이보다 학습 결과에 두 배 정도의 영향을 미친다는 사실을 상기하면, 교사를 어떻게 표준화할 것인지는 명확하지 않습니다.(23)
BOX 25.3: 무작위 대조 시험(Randomised Controlled Trial, RCT)에 초점
무작위 대조 시험(RCT)의 핵심 요소는 다음과 같습니다:
- 두 개 이상의 그룹을 포함합니다(보통 두 개, 때로는 그 이상).
- 참가자는 무작위로 각 그룹에 배정됩니다.
- 연구는 전향적으로 수행됩니다.
- 모든 참가자는 자신이 속한 그룹을 알지 못하게 눈가림(blinding) 처리됩니다.
- **개입(intervention)**은 표준화되고 실험자의 통제 하에 있습니다.
- 결과 평가는 모든 참가자에 대해 눈가림(blind) 처리된 상태에서 수행됩니다(즉, 데이터를 수집하는 사람은 참가자가 어느 그룹에 배정되었는지 모릅니다).
- 참가자들의 완전한 추적 관찰이 이루어집니다.
이제 이 측면들을 더 자세히 비판적으로 검토하고, 가능성의 범위를 파악해 보겠습니다.
무작위화, 준무작위화 및 기존 집단
Randomisation, quasi-randomisation and intact groups
실험적 접근의 필수 조건 중 하나는 무작위화, 즉 무작위 과정을 통해 그룹에 배정하는 것입니다. 그러나 무작위화는 때때로 달성하기 어렵습니다. 예를 들어, 한 학생이 월요일에 피아노를 연주하기 때문에 화요일 튜토리얼을 신청했다면, 무작위 번호로 월요일 튜토리얼에 배정되는 것을 받아들이지 않을 수도 있습니다. 우리는 무작위화가 목표를 위한 수단이라는 사실을 종종 잊습니다. 만약 학생들이 궁극적인 성과에 영향을 미칠 가능성이 거의 없는 방식으로 튜토리얼이나 병원 실습을 선택한다면, 이를 '준무작위화'라고 부를 수 있으며, 이는 충분히 타당할 수 있습니다. 또한, 편향을 방지하는 장치는 치료 효과의 크기에 맞추어야 합니다. 만약 치료 효과가 크다면, 편향에 대한 우려는 줄일 수 있습니다. Lipsey와 Wilson(24)은 319개의 교육 및 심리적 개입에 대한 체계적인 리뷰를 분석하여 (a) 평균 효과 크기는 0.45였으며(임상 개입의 효과 크기는 훨씬 작습니다. 아스피린의 심근경색 예방에 대한 연구에서 계산된 효과 크기는 0.02였습니다)(25), (b) 무작위화가 효과 크기에 미치는 영향은 없었음을 보여주었습니다. 무작위화가 이루어졌든 그렇지 않든, 효과의 크기는 동일했습니다. 이러한 상황에서는 '준무작위화'에서 발생할 수 있는 잠재적 편향은 무시할 수 있습니다.
때때로 개인의 무작위화가 불가능할 때도 있습니다. 학생들이 코스의 한 섹션 또는 다른 섹션에 속해 있을 수도 있고, 그들은 한 병원 또는 다른 병원에 배정될 수 있습니다. 이 상황을 해결하기 위한 무작위화의 변형이 ‘군집 무작위화’입니다. 즉, 집단(예: 클래스)이 한 개입 또는 다른 개입에 배정되는 것입니다. 단, 분석 시 군집을 고려해야 하며, 이는 표본 크기에 영향을 미칠 수 있습니다.
반면, 많은 연구가 기존의 집단을 사용하며, 이는 역학자들이 말하는 코호트 연구로 전환됩니다(이후에 논의할 것입니다). 한 예로, 많은 연구가 PBL과 강의 기반 교육과정을 비교했습니다. 대부분의 연구는 학교 간 비교를 포함했으며, 1970년대의 일부 연구는 학교 내 비교를 포함했으며, 학교가 평행 트랙을 운영했습니다. 학생들을 두 트랙으로 무작위 배정한 연구는 더욱 적었습니다. 관찰된 차이를 고려할 때, 학교 간 비교는 신중하게 해석해야 합니다. 왜냐하면 입학 기준에서 수업료까지 여러 가지 변수가 학교마다 다르기 때문입니다. 학교 내 비교는 더 나을 수 있지만, 종종 두 트랙의 학생들은 다른 기준으로 선발되었거나, 한 트랙을 자발적으로 선택했을 가능성이 큽니다. 따라서 PBL 학생들이 더 나은 대인관계 기술을 가진다는 발견(26,27)은 PBL 학교가 대인관계 기술을 가진 학생들을 선발했거나, 대인관계 기술이 좋은 학생들이 소그룹 중심의 PBL 트랙을 선호했을 가능성을 고려해야 합니다.(28) 최근 Schmidt 등은 PBL 개입이 중도 탈락률에 영향을 미칠 수 있음을 시사하는 실증적 데이터를 제시하여, 프로그램 종료 시 그룹이 더 이상 비교 가능하지 않게 되었다는 점을 보여주었습니다. 이는 시작 시 무작위화가 완벽히 효과적이었더라도 마찬가지입니다.(29)
할당에 대한 결론은 조건부입니다. 어떤 상황에서는 비무작위 할당이 동등하게 간주될 가능성이 높습니다. 다른 상황에서는 심각한 혼란을 초래할 수 있습니다. 연구자들은 양 집단의 관심 질문과 관련된 차원에서 가능한 한 많은 정보를 수집하고, 결과에서 관찰된 차이를 설명할 만큼 강력한 차이가 있는지 여부를 판단하여 가장 적합한 결정을 내려야 합니다.
플라시보 또는 일반적인 관리
Placebo or usual care
교육 연구에서 대조군 선택은 충분한 주의를 기울이지 않는 경우가 많습니다. 이는 그리 놀라운 일이 아닙니다. 프로그램 평가는 종종 새로운 교육과정, 강의 또는 학습 모듈에 시간과 에너지를 투입한 누군가에 의해 시작됩니다. 이제 단지 비교를 위해 두 번째 개입에 동일한 시간을 투자하는 것은 큰 노력이 되지 않을 것처럼 보입니다. 그 결과, 종종 혁신을 받은 학생들은 예를 들어, 다른 병원에서 정규 수업을 받은 학생들과 비교되며, 역학자들이 '일반적인 관리'라고 부르는 경우가 발생합니다. 변형된 형태로, 일부 학생들은 개입을 받지만 다른 학생들은 받지 않는 경우도 있습니다.
이러한 비교는 다른 방법론적 기준을 잘 준수하더라도 제한된 가치가 있을 수 있습니다. 예를 들어, 일반적인 관리가 동일한 내용을 다루도록 검사된 강의로 구성된다면 이는 공정합니다. 그러나 개입이 대조군에 비해 학습할 자료에 더 많은 시간을 할애하는 것이라면(예: 고정밀 시뮬레이션을 치료군의 교육과정에 추가하는 상황), 우리는 단지 "더 많이 공부할수록 더 많이 배운다"는 결론을 내리는 어색한 상황에 처할 수 있습니다. 과학적 관점에서 '일반적인 관리' 그룹은 대조군 개입의 특정 측면을 실험군만큼 정확하게 설명할 수 없는 한, 전혀 없는 것과 마찬가지로 유용하지 않습니다. 마찬가지로, 추가적인 자원을 사용할 수 있는 그룹과 그렇지 않은 그룹을 비교하는 것은 결국 (A + B)를 A와 비교하는 것과 같으며, 이는 '비개입' 비교에 불과합니다.
보다 유용한 방법은 총 교육 시간, 교육의 질 또는 기타 혼란 요인을 표준화할 수 있는 두 개의 실험 개입을 비교하는 것입니다. 이 전략이 어떻게 작동하는지 보여주는 훌륭한 예로, Cook(30)은 e-러닝에 대한 여러 연구를 논의하며, 매체 내에서 비교(예: 연구의 두 그룹 모두 컴퓨터를 사용하는 경우)를 통해 교육적 변수를 체계적으로 조작(즉, 통제)하고 특정 매체가 혼란되지 않도록 하는 연구의 필요성을 제안했습니다. 비교를 결정할 때, 두 그룹을 너무 통제하여 차이를 유발할 가능성이 높은 변수를 동일하게 만드는 실수를 피해야 합니다. 수업 규모에 대한 연구에서 단순히 규모의 영향을 테스트하려는 시도가 그 예입니다. 많은 연구에서 소규모 수업 토론의 특징(예: 교수와 상호작용할 기회)을 통제했는데, 이는 실제로 이점이 될 수 있는 요소입니다.(31)
눈가림(Blinding)
앞서 언급했듯이, 좋은 RCT의 기준 중 하나는 모든 참가자(교사, 학생 및 연구자)가 누가 어느 그룹에 속해 있는지 '모른다'는 것입니다. 결과 측정을 눈가림된 평가자가 수행하거나 객관적인 시험을 통해 수행하는 것이 가능할 수 있지만, 학생과 교사가 눈가림되는 것은 매우 어려울 가능성이 큽니다. 그러나 문제는 이것보다 더 광범위합니다. 실험 방법에는 참가자가 실험자의 통제 하에 있는 '객체'라는 암묵적인 전제가 포함되어 있습니다. 다행히도 오웰의 1984년의 비전은 실현되지 않았고, 우리는 연구자의 변덕에 쉽게 굴복하지 않는 학생들을 남기게 되었습니다. 이것이 실험 계획의 의도를 부정하는 것일까요? 그렇지는 않습니다. 그러나 이는 주의할 필요가 있다는 신호입니다. 연구의 타당성을 보장하기 위해 우리는 필연적으로 발생하는 눈가림 해제의 영향을 추정해야 합니다. 그렇지 않으면 잘못된 해석으로 이어질 수 있습니다. 예를 들어, 북미의 모든 의대생은 의사 면허 시험에 합격해야 한다는 강한 동기를 가지고 있습니다. 따라서 면허 시험을 PBL 교육과정을 평가하는 기준으로 사용하는 것은 큰 의미가 없습니다. 면허 시험에 대한 학생들의 성과는 교육과정과 무관한 많은 학습 활동을 반영할 가능성이 높기 때문입니다. 결과가 차이를 보여준다면 흥미로울 수 있지만, 차이가 없다는 것을 보여주는 수많은 연구는 우리의 이해에 거의 기여하지 않으며, 동등한 교육과정을 주장하는 근거가 될 수 없습니다.
사전 테스트의 위험성
The perils of pre-tests
RCT의 변형 중 하나는 두 그룹, 사전 테스트-사후 테스트 설계입니다. 사전 테스트를 고려하는 일반적인 이유는 기초 차이를 보정하기 위함이지만, 이는 논리적으로 방어할 수 없는 경우가 많고 사전 테스트의 잠재적 부작용은 종종 인식되지 않습니다. 변화 점수의 사용과 관련된 문제는 매우 복잡하며, 우리는 일부만 강조할 수 있습니다.(32)
기초 차이와 관련된 문제는 다음과 같습니다. 만약 두 그룹이 무작위 배정에 의해 생성되었다면, 그룹 간 차이는 우연에 의해 발생하며, 어느 정도는 관찰된 차이에서 우연의 역할을 명시적으로 조사하는 통계적 절차로 적절히 처리될 수 있습니다. 사전 테스트는 기초 차이가 존재하는지 여부를 확인하는 데 유용할 수 있지만, 만약 이것이 비무작위 배정의 결과라면, 어떤 사전 테스트 보정도 이러한 차이를 통제할 수 없습니다. 왜냐하면 모든 보정은 사전 테스트와 사후 테스트 간의 관계에 대한 강력한 가정을 필요로 하기 때문입니다. 교육에서 사전 테스트는 또 다른 심각한 문제를 가지고 있습니다. 사전 테스트는 학생들에게 최종 테스트가 어떻게 생겼는지 알리는 가장 좋은 방법이며, 이는 교육과정의 차이를 완전히 없앨 가능성이 있습니다. 실제로, 시험의 교육적 가치는 최근 몇 년간 의학교육에서 상당한 연구 주제가 되었습니다. 동일한 시험을 사전-사후 개입에서 사용하는 것은 문제를 더욱 확대시킵니다. Larsen 등의 연구 결과는(33) 시험을 본 자료가 특히 기억에 남는다는 것을 시사하며(이 현상은 시험 강화 학습 또는 시험 효과로 알려짐), 이는 사전 테스트가 교육과정의 차이를 완전히 제거할 가능성이 있음을 보여줍니다. 이를 명확하게 인식한 해결책 중 하나는 Solomon Four Group Design입니다. 이 설계에서는 네 가지 그룹이 있습니다:
- 사전 테스트, 개입, 사후 테스트
- 사전 테스트-사후 테스트
- 개입-사후 테스트
- 사후 테스트
이 설계를 통해 사전 테스트의 효과를 개입 자체와 분리하는 것이 이론적으로 가능합니다.
결과: 자기 평가와 성과 기반 평가, 그리고 단기와 장기
Outcomes: Self-assessed versus performance-based, and short term versus long term
적절한 결과를 선택하는 것은 아마도 연구 설계에서 가장 어려운 부분일 것입니다. 이는 이상적인 상황에서 평가해야 할 것과 현실적인 제약(시간, 비용, 수용 가능성) 하에서 평가할 수 있는 것 사이에서 거의 항상 타협을 나타냅니다. 더욱이, 교육에서 많은 관심을 받는 결과들(예: 널리 채택된 CanMEDS 역할들)은 절대적인 객관적 실체가 아니라 이론적 구성물이라는 단순한 사실이 있습니다.(34) 물론 우리는 궁극적으로 우리가 연구하는 교육적 혁신이 환자 결과에 영향을 미친다는 것을 보여주고 싶어하며, 이 분야의 네 개의 저널 편집자들도 이 목표를 진지하게 고려해야 한다고 주장한 바 있습니다.(35-38) 그러나 현실적으로, 드문 예외를 제외하고(14), 대부분의 연구는 환자 결과를 평가할 만큼 오래 지속되지 않습니다. 어쨌든 Gruppen(39)의 의견에 동의하는데, 교육적 처치와 환자 결과 사이에 너무 많은 개입 변수가 있어, 어떤 교육적 개입이 감지 가능한 차이를 만들어낼 가능성은 매우 낮기 때문에 그러한 탐구는 근본적인 이유로 권장되지 않습니다.
하지만 더 즉각적인 측정을 추구해야 하는 또 다른 이유가 있으며, 이는 이론 기반, 프로그램적 연구에 대한 철학적 헌신과 일치합니다. 예를 들어, 개입이 최종 시험이나 면허 시험에서 성과를 조금이라도 향상시킨다는 것을 보여주는 것은 어느 정도 실질적인 가치를 가질 수 있지만, 이러한 결과는 너무 많은 혼란 요인에 영향을 받아 개입과의 인과 관계를 밝혀내기 어렵습니다. 인과적 사슬을 생각해보면, 각 단계에서 개입이 근접한 결과에 최대의 영향을 미치며, 사슬이 길어질수록 영향은 줄어듭니다. (효과가 추가적이거나 심지어 곱셈적으로 증가할 수 있지만, 우리가 조사한 상황에서는 그럴 가능성이 낮아 보입니다.) 예를 들어, 의대 1학년에서 지식 수준을 향상시키는 개입이 입증되고, 1학년 성과가 임상 실습 성과를 예측하며, 임상 실습 성과가 국가 면허 시험 점수와 관련이 있다고 하면, 우리는 각 단계에서 어떤 변수가 영향을 미치는지 더 잘 파악할 수 있으며, 교육 활동을 결정하는 데 더 많은 정보를 제공받을 수 있습니다. 최근에 진행된 다양한 입학 절차의 타당성을 검증하는 연구가 이러한 접근 방식을 보여주는 사례입니다.(40) 참고로, 교육과정의 지속적인 효과를 입증하는 것은 어렵지만, 일부 최근 연구는 학생들의 성과나 윤리적 행동에서 나타나는 개인차가 장기적인 영향을 미칠 수 있음을 보여주고 있습니다.(14,41)
결과 측정을 결정할 때 고려해야 할 두 번째 문제는 결과의 출처입니다. 학습자들이 작성하는 만족도 척도는 프로그램의 효과성을 측정하는 데 널리 사용되며, 이는 아마도 관리하기 쉽기 때문일 것입니다. 그러나 시간이 없고 돈을 써서 수업을 들은 사람이 아무것도 배우지 못했고 모두 헛수고였다고 인식하는 것은 상상하기 어려우며, 일부 크게 홍보된 과정이 실제로 그럴 수 있음에도 불구하고 그렇습니다.(42) 교육에 대한 만족도는 성과 향상과 어느 정도 관련이 있지만,(43) 이는 학생들이 자신의 점수를 알았을 때 더 강한 상관관계를 보이는 ‘닭이 먼저냐 달걀이 먼저냐’의 문제일 수 있습니다. 더 나쁜 것은, 자신이 느끼는 능력에 대한 자가 평가가 실제 관찰된 능력과 최소한의 관계밖에 없다는 것이 반복적으로 입증되어 왔으며,(44-46) 이에 따라 자기 평가는 개인의 성과에 대한 대리 지표로 사용해서는 안 된다는 점이 중요합니다. 그렇긴 하지만, 최근 데이터는 집합적 관점에서 자기 평가를 고려할 경우(즉, 많은 개인에 대한 평균을 구할 경우), 교육 개입(즉, 교육과정)의 어느 측면이 성과 향상에 특히 효과적이었는지를 제공하는 신뢰할 수 있는 정보를 제공할 수 있음을 시사합니다.(47)
최적의 선택은 한편으로는 개입 효과에 민감하고 인과 관계를 허용할 수 있을 만큼 시간과 맥락이 충분히 가까우면서도, 절대적으로 타당하고 중요한 결과로 간주될 수 있을 만큼 충분히 관련성이 있는 측정을 선택하는 것입니다. 이 후자의 부분은 신중한 고려, 상담 및 파일럿 테스트를 통해서 실제로 발생할 수 있는 변화를 나타낼 가능성이 높은 결과를 평가하고 있는지 확인해야 합니다. 또한 이론과 경험을 사용하여 개입이 감정적(Affect), 행동적(Behavioural) 결과 또는 인지적(Cognitive) 능력 지표에 어떤 영향을 미칠 가능성이 있는지 해석해야 합니다. 마지막으로, 측정 도구는 신뢰성과 타당성이 입증된 심리측정학적으로 타당한 도구여야 한다는 점을 기억해야 합니다. 다음 섹션에서 이 주제에 대해 더 자세히 논의할 것입니다.
세 그룹 이상, 그리고 요인 설계(Factorial Designs)
Three or more groups, and factorial designs
실행 가능성을 제외하고는 연구를 두 그룹으로만 제한할 이유는 거의 없습니다. 플라시보나 일반적인 관리 그룹을 사용하는 단순한 접근 방식을 버리고, 여러 독립 변수를 체계적으로 조작하여 더 나은 설명을 추구할 때는 다수의 그룹을 고려할 만한 충분한 이유가 있습니다. 분석 방법은 간단합니다: 분산 분석(ANOVA)을 수행한 후 사후 분석 절차를 따르면 됩니다. 주된 단점은 추가된 그룹마다 추가적인 표본이 필요하다는 점입니다. 그러나 대안 설계 전략인 ‘요인 설계’를 사용하면 표본 크기에 거의 영향을 주지 않고 여러 가설을 다룰 수 있는 놀라운 특성을 갖게 됩니다.
한 예로, Levinson 등이 수행한 뇌 해부학 e-러닝 연구가 있습니다.(48) 이 연구에서는 두 가지 변수를 다루었습니다: 핵심 뷰(전면, 후면, 상단, 단면) 대 다중 뷰(시각화된 뇌가 여러 위치를 가질 수 있는 경우), 그리고 능동적 대 수동적 제어(한 그룹은 각 방향에서 컴퓨터 이미지가 표시되는 시간을 제어할 수 있었고, 다른 그룹은 그렇지 않았음)입니다. 이에 따라 네 개의 그룹이 생겼습니다:
- 능동–핵심 뷰
- 능동–다중 뷰
- 수동–핵심 뷰
- 수동–다중 뷰
이 네 개의 그룹은 2 × 2 표 안에 있는 것으로 생각할 수 있습니다(그림 25.2 참고).
이제 각 그룹에 25명의 학생이 있다고 가정해 봅시다. 데이터는 이원 분산 분석(two-way ANOVA)을 사용해 분석되며, 이를 통해 능동적 대 수동적 제어에 대한 유의성 검정은 두 그룹(각 50명)에 기반하여, 핵심 뷰 대 다중 뷰에 대한 검정은 두 그룹(각 50명)에 기반하여 수행됩니다. 또한, 두 변수의 상호작용(즉, 능동적 대 수동적 제어의 효과가 뷰 변수의 두 수준에서 동일한지 여부)을 네 개의 그룹(각 25명)에 기반하여 검정합니다. 두 가지 주요 가설과 관련하여, 이 비교는 각 그룹에 50명의 참가자가 있는 경우와 거의 동일한 힘을 가집니다.
더 나아가, 두 변수를 단일 연구에서 포함하지 않으면 상호작용을 평가할 수 없습니다. 흥미로운 결과는 종종 상호작용에서 발견됩니다. Levinson 연구에서도 마찬가지로, 가장 좋은 그룹은 수동–핵심 뷰 그룹이었으며, 가장 나쁜 그룹은 수동–다중 뷰 그룹이었고, 두 개의 능동적 그룹은 성과 면에서 중간 정도의 결과를 보였습니다.
이것은 요인 설계 중 가장 간단한 형태입니다. 이러한 설계는 여러 가설을 동시에 검토하고, 거의 표본 크기에 영향을 주지 않고 변수 간의 상호작용을 탐구할 수 있는 능력 덕분에, 교육 연구에서 과소 활용되고 있는 경향이 있습니다.
표본 및 효과 크기
Sample and effect sizes
이전 섹션에서는 다변량 설계의 가치를 설명하며, 이는 표본 크기에 거의 영향을 주지 않고 더 많은 정보를 얻을 수 있다는 점에서 특히 유용하다고 언급했습니다. 이제 교육 연구에서 흔히 제기되는 질문, 즉 "얼마나 많은 사람을 모집해야 합니까?"에 대해 답할 필요가 있습니다. 물론, 이러한 질문은 대부분 "상황에 따라 다릅니다"라는 대답을 필요로 할 때 흔히 발생합니다. 이와 관련하여 실험적 연구 패러다임에 참여할 때 고려해야 할 몇 가지 중요한 문제를 다뤄보겠습니다.
표본 크기를 결정할 때 고려해야 할 두 가지 주요 문제가 있습니다. 첫 번째는 통계적 문제로, 이전 섹션에서 언급한 ‘검정력(power)’의 개념과 관련이 있습니다. 교육 연구에서는 학습자 간의 차이로 인한 변동성이 항상 존재합니다. 어떤 학생들은 다른 학생들보다 더 많이 배웁니다. 큰 그룹의 강의나 소그룹 튜토리얼 등 비교 연구에서 학습량에 있어서 변동성이 존재하며, 한 그룹의 분포가 다른 그룹의 분포와 상당 부분 겹칠 가능성이 큽니다. 따라서 통계적 방법이 필요하며, 이는 두 그룹이 얻은 평균 점수의 차이가 단순히 우연히 발생했을 가능성이 적다는 것을 결정하는 역할을 합니다.
일반적으로 ‘p = 0.05’는 관찰된 차이가 우연에 의해 발생했을 가능성이 5% 미만임을 의미하며, 이는 개입이 그룹 간 차이를 일으킨 것으로 추정할 가능성이 높습니다. 그러나 이 결론은 확률에 기반하므로, 오류가 발생할 수 있으며, 차이가 없는데도 차이가 있다고 잘못 결론을 내릴 수 있습니다.
검정력(power)은 반대의 우려를 반영합니다. 즉, 실제로 개입의 효과가 있음에도 불구하고 차이가 없다고 결론 내리는 경우입니다. 검정력은 연구가 교육적으로 중요한 효과를 감지할 수 있을 만큼 충분히 큰 표본을 가지고 있는지를 나타냅니다. 표본 크기를 계산하는 특정 공식은 이 장에서 다루지 않으며, 필요한 통계 검정에 따라 공식이 달라집니다. 하지만 모든 경우에 표본 크기 계산은 예상되는 차이의 크기와 표본 내 변동성에 대한 예측에 따라 달라진다는 점을 알아야 합니다. 이러한 예측은 가능한 한 최고의 정보를 기반으로 해야 하지만, 필연적으로 어느 정도는 추정치가 될 수밖에 없습니다. 만약 통계적으로 유의미한 차이를 발견할 수 있다면, 연구는 충분한 검정력을 가졌다고 정의할 수 있습니다(즉, 표본 크기가 충분히 큼). 표본이 대표성을 가지는지, 표본이 더 많아지면 효과가 사라질지에 대한 논쟁은 있을 수 있지만, 연구가 충분한 검정력을 가졌는지 여부는 논쟁의 여지가 없습니다. 검정력 계산은 연구가 끝나기 전이나 유의미한 결과가 나오지 않았을 때만 관련이 있습니다. 큰 차이는 작은 표본이 필요하고, 작은 차이는 더 큰 표본이 필요합니다.
두 번째로 고려해야 할 문제는 앞선 논의에서 내포된 효과 크기입니다. 아주 큰 표본은 작은 표본과 반대되는 문제를 초래할 수 있습니다. 표본 크기가 너무 크면 개입의 효과가 실질적인 중요성이 없더라도 통계적으로 유의미한 차이를 보일 수 있습니다. 따라서 통계적 유의성뿐만 아니라 효과 크기도 고려하는 것이 현명합니다. 효과 크기는 일반적으로 그룹 간 평균 차이를 표준 편차로 나눈 값으로 정의됩니다(더 자세한 내용은 통계 관련 서적을 참조하십시오). 효과 크기가 클수록 연구 결과가 '임상적으로 중요하다'고 주장하기 쉬워집니다. 통상적으로 0.2, 0.5, 0.8의 효과 크기(즉, 표준 편차의 20%, 50%, 80%에 해당하는 차이)는 각각 작음, 중간, 큼으로 간주됩니다.(49)
요약
많은 사람들은 실험적 연구를 모든 연구 질문을 해결하기 위한 최적의 방법으로 여기지만, 이는 단순한 생각입니다. 실험 설계는 적절하게 적용되었을 때 변수 간 인과 관계가 존재하는지를 이해하는 데 큰 영향을 미칠 수 있습니다(즉, 하나의 변수가 변할 때 다른 변수를 변화시키는지 여부). 하지만 이러한 추론은 교육과정 수준의 개입에서는 드물게 발생하며, 이는 많은 변수와 공변량을 포함하기 때문입니다. 종종 더 유용한 것은 일련의 소규모 실험을 설계하여 학습에 중요한 요소들을 구분해내고 지식을 축적하는 것입니다. 그러나 쉽게 조작할 수 없는 자연 발생 변수 간의 관계를 테스트하는 데 관심이 있다면, 이후 섹션에서 논의할 역학적 또는 상관 연구 방법론이 더 적합할 수 있습니다.
2 역학적 전통
The epidemiological tradition
이 장에서 무작위 대조 시험(RCT)이라는 용어는 반복적으로 사용되었으며, 이는 피험자를 무작위로 서로 다른 치료를 받는 그룹에 배정한 후 결과 측정에서 비교하는 최적의 실험으로 일반적으로 간주됩니다. RCT는 역학에서 비롯된 연구 설계 계층 구조의 최상위에 위치하고 있습니다. 이 계층 구조에서 다른 설계는 교육 연구에서 명시적으로 사용되는 경우가 드물지만, 때때로 매우 유용한 역할을 할 수 있습니다.
많은 역학적 연구는 이분법적 결과(예: 생사, 개선/악화, 질병/질병 없음) 및 연구 시작 시 이분법적 분류(예: 약물/플라시보, 위험 요인 있음/없음, 예: 흡연자/비흡연자)에 기반하고 있기 때문에, 이러한 설계를 생각하는 가장 쉬운 방법은 2 × 2 표로 보는 것입니다.
이미 논의한 RCT의 설계는 Box 25.4에 설명되어 있습니다. 응답자는 행(즉, 약물 그룹 또는 플라시보 그룹)으로 무작위 배정되며, 결과(열)가 도표화됩니다. 코호트 연구는 동일한 방식으로 보이지만, 참여자는 두 그룹에 무작위 배정되지 않습니다. 대신, 실험자의 통제를 벗어난 과정에 따라 각 코호트에 속해 있으며, 따라서 ‘개입’이라는 단어는 연구의 특정 초점에 맞는 ‘노출’ 또는 다른 설명어로 대체되어야 합니다.
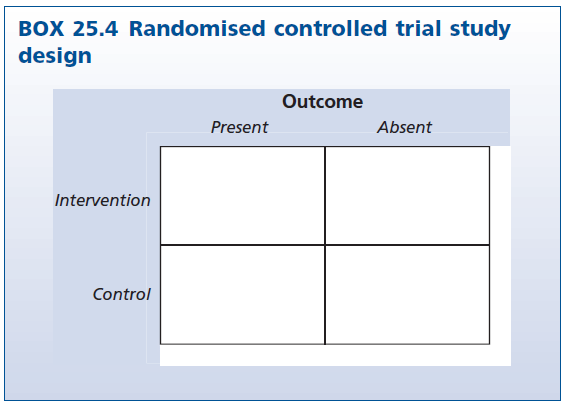
많은 PBL(문제 기반 학습)과 강의 기반 교육과정의 비교 연구는 코호트 연구로 분류될 수 있습니다. 왜냐하면 학생들이 자가 선택 또는 입학 정책의 차이와 같은 비실험적 요인으로 인해 각 코호트에 속하게 되기 때문입니다. 그런 다음 이들을 추적하여, 예를 들어, 면허 시험에서의 성공률 또는 기본 진료 레지던시 프로그램에 대한 수용률을 결정할 수 있습니다. 한 예로, Woodward et al.(26)의 연구는 맥마스터 졸업생과 온타리오의 다른 졸업생들의 청구 패턴을 비교한 코호트 연구입니다.
사례-대조 연구(case-control study)는 이와 같은 방식으로 설명할 수 있지만, 할당 방식은 반대 방향으로 진행됩니다. 사례는 결과에 따라 선택되며, 예를 들어 질병이 있거나 시험에 실패한 사람이 사례로 선정되고, 대조군은 그 결과를 가지지 않은 사람이 선택됩니다. 그런 다음 연구는 사례가 특정 위험에 더 많이 노출되었는지(예: 흡연 또는 PBL)를 확인하기 위해 과거를 추적합니다. 사례-대조 연구는 RCT와 유사하지만 다음과 같은 예외 사항이 있습니다:
- 행은 위험 요인(있음/없음)으로 더 잘 라벨링됩니다.
- 연구자는 열에서 위험 요인의 비율 차이를 찾기 때문에, 피험자는 행이 아니라 열에 배정됩니다.
Papadakis et al.(14)의 연구는 의사 면허 취소 조치를 예측하는 사례-대조 연구의 중요한 예입니다. 그들은 의사로서 어떤 형태의 징계 조치를 받은 3개 의대 출신 235명의 사례 집단을 식별하고, 징계 기록이 없는 469명의 대조군을 인구통계학적으로 일치시켰습니다(즉, 매칭됨). 그런 다음 두 그룹의 의대 시절 기록을 검토하여, 사례 집단 중 92명(39%)이 학생 시절에 비전문적 행동을 보였고, 대조군에서는 90명(19.2%)만이 유사한 문제를 보였음을 발견했습니다. 이러한 차이점에 대한 행동의 결과를 결정하기 위해서는 기본 비율을 고려해야 하지만,(50) 이 강력한 연구 결과는 전문직업성 맥락에서 고려해야 할 행동 유형에 적절한 관심을 불러일으켰습니다.
요약
역설적이지만, 이 계층 구조에서 가장 적용 가능한 연구 설계는 마지막에 위치한 사례-대조 연구입니다. 코호트 연구나 RCT와 유사한 연구는 많이 존재하며, 이를 새로운 용어로 구분하는 것은 크게 도움이 되지 않을 수 있습니다. 그러나 사례-대조 연구는 임상 의학에서의 적용과 유사한 상황에서 특히 유용합니다. 결과가 범주형(예: 징계 조치 여부)이고, 결과의 발생 빈도가 낮으며, 결과가 발생할 때까지 시간이 오래 걸리는 경우에 해당합니다. 주로 회고적이기 때문에, 사례-대조 연구는 교육적 개입을 환자 결과와 연결하려는 문제에 대한 유일한(또는 최소한 가장 효율적인) 대응일 수 있으며, 다른 대안은 규모가 너무 크거나 비용이 많이 들거나 비효율적일 가능성이 큽니다(Box 25.5).(41)
BOX 25.5: 준실험적Quasi-experimental 설계에 초점
준실험적 설계(코호트 연구 및 사례-대조 연구 포함)는 다음과 같은 특징을 가집니다:
- 보통 두 개 이상의 그룹을 포함합니다.
- 각 그룹에 배정된 참가자는 무작위 배정이 불가능한 특정 특성(예: 질병이나 위험 요인의 존재)에 기반하여 선택됩니다.
- 대부분 회고적으로 진행됩니다.
- 참가자들은 자신이 속한 그룹을 인지하고 있습니다.
- 참가자들의 완전한 추적 관찰이 드물게 이루어집니다.
3 심리측정학 전통
The psychometric tradition
이전 섹션에서 언급했듯이, 무작위 대조 시험(RCT)은 흔히 ‘최고의’ 연구 설계로 여겨지며, 의학교육 연구에서 RCT가 사용된 사례가 부족하다는 점에 대한 우려가 종종 제기됩니다. 그러나 이러한 태도는 우리의 관점에서 매우 편협한 시각입니다.(17) 양적 연구의 영역을 벗어나지 않더라도, 의학교육에서 가장 중요한 질문과 문제들 중 많은 부분은 RCT 또는 기타 실험적이나 준실험적 설계로 해결할 수 없으며, 또 해결해서는 안 됩니다.
우리 분야에서 가장 중요한 진전 중 하나는 평가의 영역에서 이루어졌으며, 의학교육은 객관적 구조화 임상시험(OSCE)과 같은 심리측정학적으로 타당한 평가 도구를 개발하여 전 세계를 선도해 왔습니다.(51, 52) 평가 방법은 진단 테스트와 유사하며, 관심 있는 특성을 많이 또는 적게 가진 사람들을 식별하고, 궁극적으로는 특정 질병, 즉 이 경우에는 ‘무능력’을 정의하는 기준선을 설정하는 데 목적이 있습니다. 예를 들어, 새로운 방사선 촬영 절차와 같은 진단 테스트를 개발하는 출발점은 환자 집단을 모아 테스트를 실시한 후 (a) 평가자 간의 일치도와 (b) 동일한 특성을 측정하는 다른 방법과의 관계를 살펴보는 것과 유사합니다. 마찬가지로, 새로운 평가 방법을 테스트할 때는 학생 집단을 모아 테스트를 시행한 후 신뢰도와 타당도를 평가하는 것이 필요합니다. 만약 방사선 전문의가 새로운 진단 절차를 도입하면서 먼저 평가자 간 일치도나 테스트 결과가 다른 질병 측정 방법과 일치하는지 확인하지 않고 다기관 시험을 통해 그 절차를 받은 환자가 더 오래 살았는지를 확인하려고 한다면, 그는 정신과적 검사를 받게 될 위험이 있습니다. 이와 유사하게, 궁극적으로 실험적 방법을 사용하여 새로운 평가 방법을 받은 학생들이 기존의 평가 방법을 받은 학생들보다 더 나은 성과를 보인다는 것을 입증하고 싶을 수도 있겠지만, 이것이 연구의 첫 번째 단계는 아닙니다.
의학교육 연구에서 많은 연구가 평가 방법의 개발 및 테스트에 초점을 맞추고 있기 때문에, 이 섹션에서는 심리측정학적 방법의 기본적인 문제들에 대해 논의할 것입니다. 이 논의는 필연적으로 간략하지만, 더 깊이 있는 설명을 원한다면 Streiner와 Norman의 저서를 참고하는 것이 좋습니다.(53)
기본 개념
Basic concepts
심리측정학적 방법은 데이터가 신뢰할 수 있을 만큼 충분히 정확하고 이를 바탕으로 적절한 해석과 정확한 의사 결정을 내릴 수 있도록 설계되었습니다. 의학교육자와 일반 대중은 매일같이 ‘데이터 기반’ 주장을 접하지만, 이러한 모든 주장이 동등하게 취급되어서는 안 됩니다. 대부분의 타당성 위협은 이러한 직관적 의심을 공식화하고, 우리의 측정 도구가 실제로 우리가 의도한 것을 측정하고 있는지 테스트할 방법을 마련하는 것을 필요로 합니다.
이러한 전략은 여러 영역에 적용될 수 있습니다. 예를 들어, 입학 결정의 질을 평가하는 연구,(54) 성격과 전문성 간의 관계를 연구하는 연구,(55) 또는 학습자가 자기 주도 학습을 얼마나 잘 수행하는지를 측정하기 위한 설문지 사용에 대한 연구 등이 있습니다.(56) 각 사례에서 정보를 수집하고 결정을 내리는 것은 쉽지만, 그 결론이 올바른 검증을 통과하는지 결정하는 것은 훨씬 더 복잡합니다. 이러한 진술을 이해하기 위해서는 ‘올바른 검증’이 무엇인지 정의할 필요가 있습니다.
어떤 측정 도구든 유용한 정보를 제공하기 위해서는, 그것이 물리적 상태의 객관적 지표(예: 온도계로 측정되는 것)든, 또는 더 추상적인 구성물(예: 자신의 능력에 대한 인식)과 관련된 주관적 주장에 대한 것이든, 다음 네 가지 ‘-성’을 충족해야 합니다:
- 실행 가능성(feasibility)
- 수용 가능성(acceptability)
- 신뢰도(reliability)
- 타당도(validity)
첫 번째와 두 번째는 별도의 설명이 필요 없을 만큼 비교적 자명합니다. 측정 도구는 사용할 수 있는 한도 내에서만 사용 가능해야 하고(실행 가능성), 사람들이 사용할 만큼만 수용 가능해야 합니다(수용 가능성). 이러한 ‘-성’을 평가하는 방법에는 약간의 고민이 필요합니다. 예를 들어, 수용 가능성에는 측정 도구가 특정 인구 하위 그룹에 대해 부적절한 편향을 보이지 않는다는 것을 증명하는 것이 포함될 수 있습니다.
그러나 신뢰도와 타당도는 더 많은 설명이 필요합니다. 여기에서 한 가지 사전 고지 사항을 언급하자면, 우리는 측정 도구의 심리측정학적 특성에 대해 논의할 것이지만, 이는 편리한 약어일 뿐이며, 특정 도구와 관련하여 맥락이 없는 특성에 대해 이야기하는 것은 부정확합니다. 즉, 도구의 유용성(18장 참조)은 전적으로 그 도구가 사용될 인구와 맥락에 따라 달라집니다. 예를 들어, 슬픈 얼굴과 웃는 얼굴을 기준으로 한 채점 시스템은 학령기 어린이에게는 적합할 수 있지만, 의학 국가 면허 시험에서는 받아들여지지 않을 가능성이 큽니다. 또한 성생활에 관한 질문을 묻는 설문지는 일부 응답자 그룹에서는 정확한 응답을 얻을 수 있을지 모르지만, 다른 그룹에서는 응답하지 않거나 불쾌감을 줄 수 있습니다. 혈압 측정이 포함된 임상 기술 시험은 초급 의대생 사이에서는 유의미한 차이를 보일 수 있지만, 의학 레지던트에게는 쓸모없을 수 있습니다. 이러한 맥락적 변수는 신뢰도와 타당성 평가에 중요한 영향을 미칠 수 있습니다.
신뢰도 Reliability
신뢰도는 의학교육에서 가장 오용되는 단어일 수 있습니다. 신뢰도는 합의(agreement)를 의미하지 않으며(비록 합의가 관련 있긴 하지만), 변동성(variability)을 의미하지도 않으며(비록 변동성도 관련 있긴 하지만), 집단의 평균 점수의 일관성에 의해 나타나지도 않습니다(비록 도구가 신뢰할 수 있다면 그런 일관성을 기대할 수 있습니다). 신뢰도는 측정 도구가 얼마나 일관되게 대상자들 간의 차이를 구분할 수 있는지를 나타내는 통계 용어입니다. 여기서 대상자는 학습자, 교사, 과정, 학교, 설문 응답자 또는 기타 개별 집단일 수 있습니다. 의학교육 커뮤니티 내에서는 주로 학생들 간의 차이를 구분하려는 시도가 많으므로, 이 분야를 예로 들어 설명하겠습니다.
예를 들어, 전문적 책임에 대한 지식을 평가하기 위한 도구를 개발하는 데 관심이 있다고 가정하면, 응답의 변동성을 유발하는 항목을 생성하는 것은 어렵지 않을 것입니다. 사실, 변동성을 유발하는 것이 주요 목표일 것입니다. 왜냐하면 모든 학생이 동일한 응답을 할 경우 시험을 시행할 이유가 거의 없기 때문입니다. 하지만 이러한 변동성은 여러 요인에 기인할 수 있습니다. 우리의 바람은, 학생들이 보여주는 시험 점수가 그들의 전문적 책임에 대한 지식의 진정한 또는 일관된 차이를 반영하는 것입니다. 그러나 변동성의 일부는 측정 오류로 인해 발생할 수 있으며, 이는 학생들에게 부여된 점수에 체계적인 편향이나 무작위적 요인들이 영향을 미칠 수 있다는 것을 의미합니다.
주된 질문은, 점수에서 나타난 변동성 중 얼마만큼이 학생들 간의 실제 차이와 관련된 것이고, 얼마만큼이 오류에 기인하는가입니다. 즉, 시험을 다시 시행하거나, 다른 평가자가 응답을 평가하거나, 유사한 시험을 사용했을 때, 개별 학생들의 점수가 얼마나 일관성 있게 유지될 것인가 하는 문제입니다. 수학적으로, 이 개념을 가장 간단하게 표현하는 방법은 다음과 같은 공식입니다:

여기서 (\sigma^2)는 분산을 나타내는 기호로, 분자는 학생들 간의 차이에 기인하는 분산의 양을, 분모는 점수에서 관찰된 총 변동성을 나타냅니다. 이 공식은 수학적 계산을 설명하기 위해서가 아니라 신뢰도와 심리측정학적 전통에 관한 몇 가지 기본적인 점을 설명하기 위해 제시되었습니다(자세한 내용은 Box 25.6 참조).
심리측정학 전통 내에서 일반화 가능성(generalisability)이라는 개념도 자주 등장합니다. 이는 신뢰도 개념의 가까운 친척입니다. 일반화 가능성 이론은 특정 상황에서 부여된 점수가 다른 맥락(예: 다른 평가자, 다른 시간 등)에서 부여된 점수로 얼마나 일반화될 수 있는지를 표현하는 방법입니다.(52) 이 개념이 친숙하게 느껴진다면, 이는 일반화 가능성 이론이 고전적인 신뢰도 이론의 확장판이기 때문입니다. 이 이론은 여러 오류 변동성의 출처를 동시에 고려할 수 있는 수학적 인프라를 제공합니다. 이러한 이론의 주요 이점은 여러 변인의 오류 기여도를 평가하기 위해 여러 연구를 수행할 필요가 없다는 것이며, 그 결과 특정 변인에 대한 관찰 횟수를 늘리는 것이 다른 변인에 대한 관찰 횟수를 늘리는 것에 비해 어떤 이점을 제공하는지 결정할 수 있다는 점입니다.
BOX 25.6: 신뢰도에 초점
- 신뢰도는 측정 도구의 고정된 속성이 아닙니다. 예를 들어, 특정 전문 지식 평가 도구가 2년차 레지던트를 평가하도록 설계되었다면, 해당 도구의 신뢰도는 2년차 레지던트를 대상으로 테스트해야 합니다. 더 이질적인 표본(예: 1학년 학부생 및 실무 윤리학자 포함)을 모집할 경우, 결과는 신뢰도를 인위적으로 높게 추정하게 됩니다. 연구자는 도구를 사용할 특정 맥락을 명확히 정의하고, 그 맥락에서 활동하는 사람들을 대표하는 표본을 모집하여 테스트해야 합니다.
- 변수의 반복 측정이 도구의 신뢰도를 추정하는 데 필요합니다. 만약 평가자들이 학생의 성과에 대한 평가에서 의견이 다를 수 있다면, 여러 평가자들에게 학생의 성과를 평가하도록 해야 합니다. 또한 학생의 성과가 사례별로 다르다면(즉, 내용 특이성), 여러 사례에서 평가해야 합니다. 단순히 시험을 시행하고 점수가 정규 분포를 보인다는 사실만으로는 도구가 학생들 간의 차이를 일관되게 구분하는 정도에 대해 아무것도 알려주지 않습니다. 왜냐하면 변동성은 학생들 간의 실제 차이 또는 측정 오류에서 비롯될 수 있기 때문입니다.
- 더 많은 관찰이 이루어질수록, 도구의 신뢰도는 더 높아집니다. 오류 항의 n은 수집된 관찰 수(여러 시험 문제, 여러 평가자, 여러 번의 시험 실시 등)를 나타냅니다. 여러 관찰의 평균은 임의의 긍정적 오류와 부정적 오류를 상쇄할 수 있기 때문에, 하나의 점수보다 더 나은 추정을 제공합니다. 특정 출처의 변동성이 특정 측정에 오류를 기여하지 않는다면, 해당 출처에서 수집된 여러 관찰을 평균해도 신뢰도에는 영향을 미치지 않습니다(0을 어떤 수로 나눠도 여전히 0입니다). 따라서 심리측정학 분석에서 중요한 측면은 합리적인 신뢰도를 얻기 위해 얼마나 많은 관찰이 필요한지 결정하는 것입니다. 만약 필요 관찰 횟수가 너무 많아 실행 불가능하다면, 도구를 수정하거나 포기해야 할 것입니다.
- 차별성을 가지지 않는 도구는 평가에 무용합니다. 특정 측정 도구가 학습 동기를 유도하는 등의 유용성이 있을 수 있지만, 일반적으로 유용성 주장claims of utility은 신뢰성에 대한 증거에 의존합니다. 만약 모든 참가자가 동일한 점수를 받는다면, 시험을 시행하지 않고 시간을 더 유용하게 사용하는 것이 좋을 것입니다.
- 그룹의 평균 점수가 시간이 지남에 따라(또는 평가자 간에) 변하지 않았다는 주장은 신뢰도에 대한 증거가 아닙니다. 예를 들어, 시험 점수가 완전히 뒤바뀌어도 평균 점수는 안정적으로 유지될 수 있습니다. 무작위 숫자 생성기 또한 여러 시점에서 동일한 평균을 제공할 수 있지만, 이는 신뢰할 수 있는 성과 측정이라고 주장할 수 없습니다.
- 때때로 신뢰도보다 타당성이 더 중요하다는 주장이 제기됩니다. 그러나 이는 비논리적입니다. 신뢰도는 반복된 경우에 도구가 자기 자신과의 상관관계를 나타내는 것이며, 타당성은 외부 기준(예: 골드 스탠다드)과의 상관관계를 나타냅니다. 도구가 자기 자신과의 상관관계보다 더 좋은 상관관계를 가질 수는 없기 때문에, 신뢰도는 타당성의 상한선을 설정합니다. 따라서 신뢰도는 타당성과 분리될 수 없으며, 현대 심리측정학 모델에서는 신뢰도를 타당성의 한 측면으로 간주합니다.(57)
타당도(Validity)
역사적으로, 타당도를 설명하는 많은 방식들은 평가지의 신뢰성을 다양한 방법으로 구분하는 분류법을 사용해 왔습니다.(58)
- 내용 타당도(Content validity)는 도구의 항목이 관심 영역을 충분히 포괄하고 있는지를 나타냅니다(즉, 질문이 충분하고 관련성이 있는가?).
- 준거 타당도(Criterion validity)는 측정 도구가 동일한 기저 구조의 다른 측정과 얼마나 잘 상관되는지를 의미합니다.
- 구성 타당도(Construct validity)는 도구에서 얻은 점수가 해당 도구가 측정하려는 기저 구조에 대한 이해에 따라 얼마나 일치하는지를 나타냅니다(예: 새로운 키 측정 도구가 농구 선수들이 조련사보다 더 높은 점수를 받게 한다면 그 타당도가 있다고 할 수 있습니다).
다른 분류법도 사용되어 왔으나, 결국 이것들은 모두 타당도를 설명하는 방식입니다. 즉, 측정 도구로 얻은 점수가 피험자의 기저 구조가 얼마나 변화했는지에 따라 일관되게 변동하는지 여부를 나타냅니다.
일부 학자들은 신뢰도를 별개의 개념이 아니라 타당도의 한 측면으로 간주해야 한다고 주장합니다. 그 이유는, 도구가 여러 번 시행되었을 때 기저 구조가 변하지 않았다고 기대된다면, 점수 또한 변하지 않아야 하기 때문입니다.(59) 다양한 타당도 분류법은 도구의 타당성을 테스트하는 방법에 대한 아이디어를 제공하는 데 유용할 수 있지만, 타당성 테스트는 다양한 방법론을 사용하여 체계적인 연구가 필요하다는 사실을 간과해서는 안 됩니다.
Messick가 말한 결과 타당도(Consequential validity)라는 개념 중 한 가지 중요한 측면을 강조할 필요가 있습니다.(58) 학생들을 평가하는 도구를 도입할 때는 그 도구가 행동에 미치는 영향을 반드시 고려해야 합니다. 평가가 학생들의 학습 활동에 지향 효과(steering effect)를 미친다는 사실은 오랫동안 알려져 있었습니다.(60) 결과적으로 평가 도구의 유용성을 보장하기 위해서는 도구가 촉진하는 학습 활동이 우리가 촉진하고자 하는 학습 활동과 일치해야 합니다. 도구의 유용성을 구성하는 측정의 다섯 가지 원칙(네 가지 ‘-성’과 교육적 영향)은 항상 일치하지 않으며, 종종 서로 상충됩니다. 따라서 상황의 특성에 따라 적절한 타협을 결정해야 할 필요가 있습니다.
연구자들은 일반적으로 위에서 설명한 대로 신뢰도를 테스트하는 것부터 도구의 타당성 연구를 시작합니다. 그 이유는 도구가 신뢰할 수 없다면, 그것은 타당할 수 없기 때문입니다. 예를 들어, Harasym 등(61)의 연구에서는 면접관 패널에서 의대 지원자에게 부여된 점수의 일관성을 연구한 결과, 점수의 50% 이상이 면접관에 의해 좌우된다는 사실을 발견했습니다. 이는 면접관의 엄격성에 따른 차이를 반영하는 것으로, 이는 패널 기반 면접 과정이 지원자의 자질을 평가하려는 것이지 면접관의 엄격성을 평가하려는 것이 아님에도 불구하고 신뢰도와 타당도를 근본적으로 의심하게 만듭니다.
그러나 신뢰도만으로는 충분하지 않습니다. 어떤 것을 일관되게 측정할 수 있다는 것만으로 그 측정이 타당하다는 것을 의미하지는 않습니다. 예를 들어, 한 사람의 머리 둘레를 일관되고 신뢰성 있게 측정할 수는 있지만, 이러한 데이터는 공감 능력을 평가하는 데는 전혀 유용하지 않습니다. 이는 골상학(Phrenology)이 이미 100년 전에 폐기된 학문이기 때문입니다.(62) 더 직접적인 예는 OSCE 형식에 관한 문헌에서 찾을 수 있습니다. 대부분의 독자가 OSCE에 익숙할 것이므로 OSCE는 ‘종 울리기’ 시험으로, 응시자가 여러 환자와 차례로 상호작용하며 임상 기술을 입증하는 시험이라는 점만 간단히 언급하겠습니다. OSCE의 ‘O’는 객관적(Objective)을 의미하며, 이는 적절한 행동 목록을 생성하고 수험자가 수행한 행동을 기록함으로써 성과를 평가할 수 있다는 초기 아이디어를 나타냅니다. 실제로 이러한 체크리스트는 개인의 성과를 매우 신뢰성 있게 측정할 수 있다는 것이 입증되었습니다.(63) 그러나 여러 연구에서, 이러한 체크리스트가 경험 수준과는 관련이 없다는 것이 드러났습니다. 경험 수준은 능력을 측정하려는 주장에 중요한 변수입니다. 반면, 종합적 평가(global ratings)는 경험 수준과 관련이 있는 경향이 있어, 체크리스트는 포괄성을 측정하는 데 유효할 수 있지만, 주관적 판단은 많은 영역에서 임상 전문성을 측정하는 데 더 유효한 측정 도구라는 점이 시사되었습니다.(64, 65)
타당성을 연구할 수 있는 방법론은 다양하며, 이를 끝없이 논의할 수 있습니다. 다음 등이 타당성을 연구하는 세 가지 주요 방법론으로 채택될 수 있습니다.
- 다양한 그룹이 기저 구조의 양에서 차이를 보일 것으로 예상되는 경우 평균 점수 비교를 하거나,
- 기저 구조와 관련이 있을 것으로 예상되는 연속 변수와의 상관관계를 확인하거나,
- 기저 구조의 수준을 변화시킬 것으로 예상되는 개입 후 점수 변화를 조사하는 것
흥미로운 예로는, Tamblyn et al.의 연구에서 캐나다 면허 시험에서의 성과와 의사로서의 전문 행동 사이의 관계를 밝혀냈습니다.(41) Ramsey et al.의 연구는(66) 전문가 자격증 시험이 10년 후 동료 평가와 관련이 있음을 보여주었으며, Davis et al.의 연구는(46) 자기 평가의 타당성에 의문을 제기하는 연구를 지속적으로 이어오고 있습니다. 실제로, 이 장의 다른 섹션에서 다룬 방법론들(또는 다루지 않은 방법론들) 중 많은 것들이 타당성을 테스트하는 전략으로 간주될 수 있습니다.
이 섹션을 마무리하면서 중요한 점은 절대적인 의미에서 타당성을 증명하는 것은 드물다는 사실입니다. 타당성 테스트는 중요합니다. 왜냐하면 측정 도구가 의사 결정에 활용될 수 있다는 주장은 증거의 균형에 의존하기 때문입니다. 본질적으로, 타당성 테스트는 이론 테스트입니다. 긍정적인 결과를 보여주는 각 테스트는 이론과 도구의 타당성을 지지하지만, 부정적인 결과를 보여주는 테스트는 이론이 잘못되었거나 도구가 기저 구조를 제대로 측정하지 못한다는 의문을 제기하게 만듭니다.
요약
심리측정학적 전통에서 수행되는 연구의 주요 주제는 연구자, 교육자, 임상의, 그리고 일반 대중까지도 우리의 사고와 의사 결정을 이끄는 데이터가 충분히 신뢰할 수 있는지 확인해야 한다는 것입니다. 이는 단순히 학문적 문제가 아닙니다. 왜냐하면, 종종 사람들의 삶은 불확실한 타당성을 지닌 ‘데이터’에 따라 변화되기 때문입니다(입학/불합격, 직업에서의 승진/좌절, 법적 시스템 내 의사 결정, 또는 개인 상담 및 결혼 상담에서). 연구 도구와 평가 전략의 타당성을 확보하는 것은 윤리적 책무입니다.(67) 쉽지 않으며, 심리측정학적 특성 외에도 고려해야 할 요소가 분명히 있지만, 여기서 설명한 방법과 개념들은 출발점으로 적합하며, 최소한 이러한 문제에 대한 논리적 사고의 기초를 제공합니다.
4 상관적 전통
The correlational tradition
의학교육 연구에서 상당한 비율의 연구는 설문조사에 의존합니다. 이러한 설문조사는 학습 스타일이나 감성 지능과 같은 개인 내적 문제에서부터 성취도 평가나 관찰 가능한 행동의 측면에 대한 관찰자 평가 또는 만족도 측정에 이르기까지 광범위한 주제를 다룰 수 있습니다. 이 방대한, 이질적이며 복잡한 분야를 모두 다루는 것은 현실적으로 어렵습니다. 대신, 이 섹션에서는 점수 산정, 연구 설계 및 분석과 관련된 몇 가지 공통적인 문제를 다룰 것입니다. 설문지 설계는 27장에서 Lovato와 Wall이 다루고 있지만, 여기서는 설문지 기반의 연구가 결코 쉬운 일이 아니며, 여전히 신뢰성과 타당성을 보장해야 한다는 점을 상기시킬 필요가 있습니다.
일반적으로 설문지는 특정 문제에 대해 대규모 집단의 인식과 태도를 체계적으로 파악하는 데 유용합니다. 그러나 사람들은 자신의 행동 원인이나 자신의 성과를 정확하게 판단하는 데 매우 서툴다는 한계가 항상 있음을 인지해야 합니다.(45,46,68)
점수 산정 Scoring
설문 조사에서 개별 항목에 대한 응답은 종종 합산되어 점수로 나타납니다. 각 항목에 얼마나 가중치를 부여할지 결정하는 데 많은 노력이 들어갈 때도 있습니다. 하지만 1976년까지 거슬러 올라가는 광범위한 문헌에 따르면, 모든 항목을 단순히 합산하는 동일 가중치 모델이 다른 대안만큼 신뢰할 수 있고 타당하다는 일관된 결과가 나왔습니다.(69) 여기서 주의해야 할 점은, 항목들의 평균과 표준 편차가 비슷할 때 단순 합산이 적합하다는 것입니다. 예를 들어, 일부 항목이 이분법적(0 또는 1)이고, 다른 항목이 7점 척도로 되어 있는 경우, 이를 단순히 합산하는 것은 적절하지 않습니다. 마찬가지로, 7점 척도로 매긴 면접 점수를 100점 만점의 학점과 합산하거나, 키로그램 단위의 몸무게를 미터 단위의 키와 합산하는 것도 부적절합니다. 개별 항목들이 다른 척도로 되어 있을 때는 Z 점수로 변환한 후에 합산해야 하지만, 합산 후에도 동일한 가중치를 유지해야 합니다.
또 다른 논쟁은 이러한 척도에 할당된 점수를 평균 산출에 사용할 수 있는지에 관한 것입니다. 왜냐하면 순위 자료(ordinal data)이기 때문에 연속 간격이 동일하다는 보장이 없기 때문입니다.(70) 그러나 실무에서는 파라메트릭 통계 분석(interval-level data 요구)이 정규성에서 벗어난 데이터에도 비교적 강건하게 작용하며,(71-73) 그 적용의 용이성은 대부분의 상황에서 큰 장점을 제공합니다.
타당화(Validation)
심리측정학적 방법에서 설명된 타당화 방법은 설문 도구에도 적합하며, 설문 데이터가 의도된 목적에 적합하지 않을 수 있음을 방지하기 위해 신중하게 고려해야 합니다.
분석(Analysis)
상관적 접근은 변수 간의 관계를 탐구하는 데 기초하며, 분석은 일반적으로 모든 변수를 상관시키는 것에서 시작됩니다. 하지만 문제는 연구자들이 'p = 0.05'의 의미를 종종 잊어버린다는 데 있습니다. p = 0.05는 관찰된 관계가 실제로 관계가 없을 경우에도 우연히 발생할 확률이 5% 미만이라는 의미입니다. 즉, 20개의 상관관계를 계산할 때, 그 중 하나는 우연에 의해 유의미할 가능성이 높다는 뜻입니다(실제로는 64.2%의 확률로 적어도 하나가 유의미할 수 있습니다). 이러한 문제는 ANOVA, t-검정 및 기타 p-값에 의존하는 통계 분석에도 적용됩니다.
이 데이터 채굴(data dredging) 문제에 대한 명백한 해결책은 먼저 실질적인 이론을 세우고, 어떤 관계가 예상되는지에 대해 집중하는 것입니다. 또한, 연구자가 여전히 여러 상관관계에 관심이 있을 경우, Bonferroni 보정을 적용하여 p-값을 0.05/n으로 설정하는 것이 중요합니다. 여기서 'n'은 총 통계 테스트 수를 나타냅니다.(74)
요약
의학교육 연구에서 설문조사 기반의 연구는 중요한 비율을 차지하며, 상관관계 분석은 변수 간의 관계를 탐구하는 강력한 도구입니다. 그러나 연구자는 항상 p-값의 의미와 우연히 유의미한 상관관계가 발생할 가능성을 인지해야 하며, 이론 기반의 연구 설계를 통해 데이터의 의미를 더욱 명확하게 하고,불필요한 데이터 채굴을 방지해야 합니다.
상관적 방법을 넘어서는 다변량 분석
상관관계 분석보다 더 정교한 접근 방식은 다변량 방법을 사용하는 것입니다. 여기에는 다중 회귀분석, 요인 분석, 구조방정식 모델링 등이 포함됩니다. 엄밀히 말하자면, '다변량multi-variate'이라는 용어는 다수의 종속 변수가 있는 상황에만 적용됩니다. 따라서 다중 회귀분석은 단변량 절차에 속하고, 요인 분석과 구조방정식 모델링은 다변량 절차입니다. 다중 회귀분석Multiple regression은 여러 독립 변수를 사용해 단일 종속 변수를 예측하는 방식으로, 예를 들어 면허 시험 성과를 예측할 때 학부 성적, 성별, MCAT 점수와 같은 변수를 사용합니다. 요인 분석은 변수들 간의 근본적인 연관성을 탐색하며, 이를 요인(factors)이라고 합니다. 더 정교한 방식으로는 확인적 요인 분석, 계층적 선형 모델, 구조 방정식 모델 등이 있습니다. 이러한 방법들에서 연구자는 변수 간의 관계에 대한 이론을 가지고 시작하며, 데이터 세트에 맞는 다양한 인과 모델을 적용하여 적합도를 계산합니다.
이 접근법의 주요 도전 과제:
- 표본 집약적입니다. 규칙적으로, 표본 크기는 변수 수의 5-10배가 되어야 합니다.
- 모델이 복잡해질수록 '이 모델이 데이터를 더 잘 설명한다'는 것이 실제로 무슨 의미인지 점점 더 불분명해집니다.
- 각 연구에서 사용하는 변수의 조합이 다를 가능성이 높아, 이론이 해당 데이터 세트에만 고유한지 여부를 판단하기 어렵습니다.
그럼에도 불구하고, 이러한 방법들은 단순한 상관 계수 산출 방식보다 큰 발전을 나타냅니다. 상관 연구에서 p-값보다 상관 계수에 집중하는 것이 중요합니다. 큰 표본에서 작은 상관관계(r = 0.1)도 통계적으로 유의미할 수 있지만, r²는 상관계수 r = 0.1이 데이터 변동성의 단 1%만을 설명한다는 것을 보여줍니다. 따라서 상관관계의 '임상적 중요성'을 평가할 때는 항상 r²을 사용하는 것이 좋습니다.
BOX 25.7: 통계적 검정에 초점
통계적 검정은 크게 두 가지 범주로 나눌 수 있습니다.
모수 검정(Parametric tests)
이 검정은 평균과 표준 편차를 계산하는 것이 의미 있는 데이터에 적용됩니다.
평균 비교에 사용되는 검정:
- t-검정(t-test): 하나의 독립 변수가 두 그룹으로 나뉘어 있을 때 또는 두 개의 관련된 관찰(예: 전후 비교)이 있을 때 사용됩니다.
- 분산 분석(ANOVA): 하나 이상의 독립 변수가 두 개 이상의 그룹(‘수준’)을 포함하는 경우 사용됩니다.
- 반복 측정 분산 분석(Repeated measures ANOVA): 동일한 피험자에게서 독립 변수 내에서 반복적으로 관찰된 데이터를 분석하는 ANOVA의 특수 사례입니다. 또한 신뢰도 및 일반화 가능성 연구에 사용됩니다.
관계 분석에 사용되는 검정:
- 피어슨 상관관계(Pearson’s correlation): 두 개의 연속형 변인 간의 관계를 제공합니다.
- 다중 회귀 분석(Multiple regression): 여러 예측 변수와 단일 연속형 종속 변수 간의 관계를 제공합니다.
- 요인 분석(Factor analysis): 많은 관련 변인들 간의 관계(기저 요인)를 제공합니다.
비모수 검정(Non-parametric tests)
이 검정은 빈도 계산에 사용됩니다.
- 카이제곱(Chi-squared): 두 개 이상의 관련 범주(예: 2 × 2 테이블)의 비율을 비교합니다.
- 로지스틱 회귀(Logistic regression): 여러 예측 변수와 단일 이분형 독립 변수 간의 관계를 제공합니다.
Cronbach의 ‘두 가지 과학 심리학’
Cronbach’s ‘two disciplines’
이 장의 서두에서 설명했듯이, 많은 연구 질문은 실험 설계로 해결할 수 없으며, 해결해서도 안 됩니다. 연구자들이 다루고자 하는 질문에 따라 양적 연구와 질적 연구 또는 실험적 방법과 상관적 방법 중에서 가장 적절한 방법을 선택해야 합니다. 이론 기반의 프로그램적 연구를 촉진하기 위해서는 다양한 방법을 사용하여 문제를 다각적으로 탐구하고, 하나의 방법만으로는 얻을 수 없는 풍부한 이해를 도출해야 합니다.
그러나 이 선택은 단순한 가치 중립적인 결정이 아닙니다. Lee Cronbach는 1957년에 발표한 고전 논문 '과학 심리학의 두 가지 학문'에서 이 기본적인 이분법을 처음으로 인식했습니다.(75)
이분법의 본질은 다음과 같습니다:
- 상관적 방법(심리측정학 포함)은 개인 차이에 의존합니다. 신뢰도 계수는 모든 사람이 동일하다면 0이 되며(즉, 피험자 간 분산이 없을 경우), 지능지수나 학부 성적과 같은 개인 속성 및 면허 시험 성과와의 관계를 연구하려면, 각 측정에서 일부 학생이 높고 낮아야 상관관계가 발생할 수 있습니다.
- 반면, 실험에서는 모든 학생의 능력이 정확히 동일한 상태에서 시작하는 것이 이상적입니다. 만약 학생들 간에 이미 생물학, 물리학 등의 지식에서 차이가 난다면, 이러한 변동성은 실험 및 대조군의 점수에 노이즈를 추가하게 됩니다.
실험가에게 사람들 간의 변동성은 치료 효과를 희석시키는 요소입니다. 그러나 상관 연구자는 사람들 간의 차이를 이해하는 것이 목표입니다. 하나의 연구자의 신호는 다른 연구자에게는 노이즈가 되는 셈입니다.
따라서 어느 방법이 '더 나은' 방법인지 논쟁하는 것은 빨간색이 파란색보다 더 낫다고 주장하는 것과 같습니다. 어떤 방법이 더 낫거나 나쁘다는 것은 그 방법이 무엇을 달성하려는지에 따라 다를 뿐입니다. 최근 한 학자는 "무작위 대조 시험은 치료 효과를 찾는 데 가장 좋은 방법이지만, 누구에게 효과가 있는지를 찾는 데는 최악의 방법"이라고 요약했습니다.
'Wilson Centre' 카테고리의 다른 글
| [양적연구] 관찰 연구 방법 연구 설계 II: 코호트, 횡단면 및 사례 대조 연구 (0) | 2024.09.14 |
|---|---|
| [양적연구] 관찰 연구와 무작위 대조 임상시험 비교 (1) | 2024.09.14 |
| [양적연구] RCT = 혼란스럽고 사소한 결과: 대규모 교육 실험의 위험성 (1) | 2024.09.13 |
| [양적연구] 너무 먼 다리 (2) | 2024.09.13 |
| [연구] 과학 실험의 철학: 리뷰 (0) | 2024.09.13 |