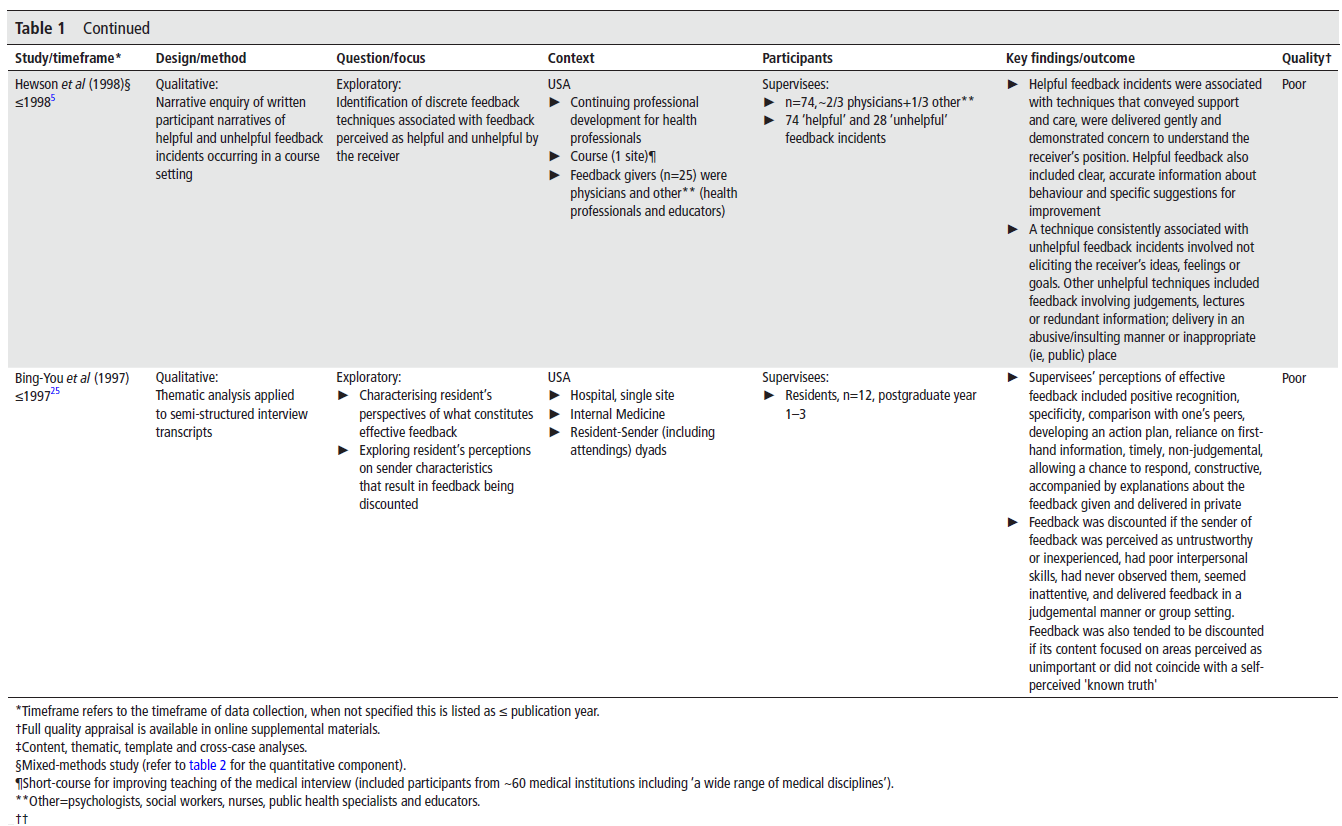
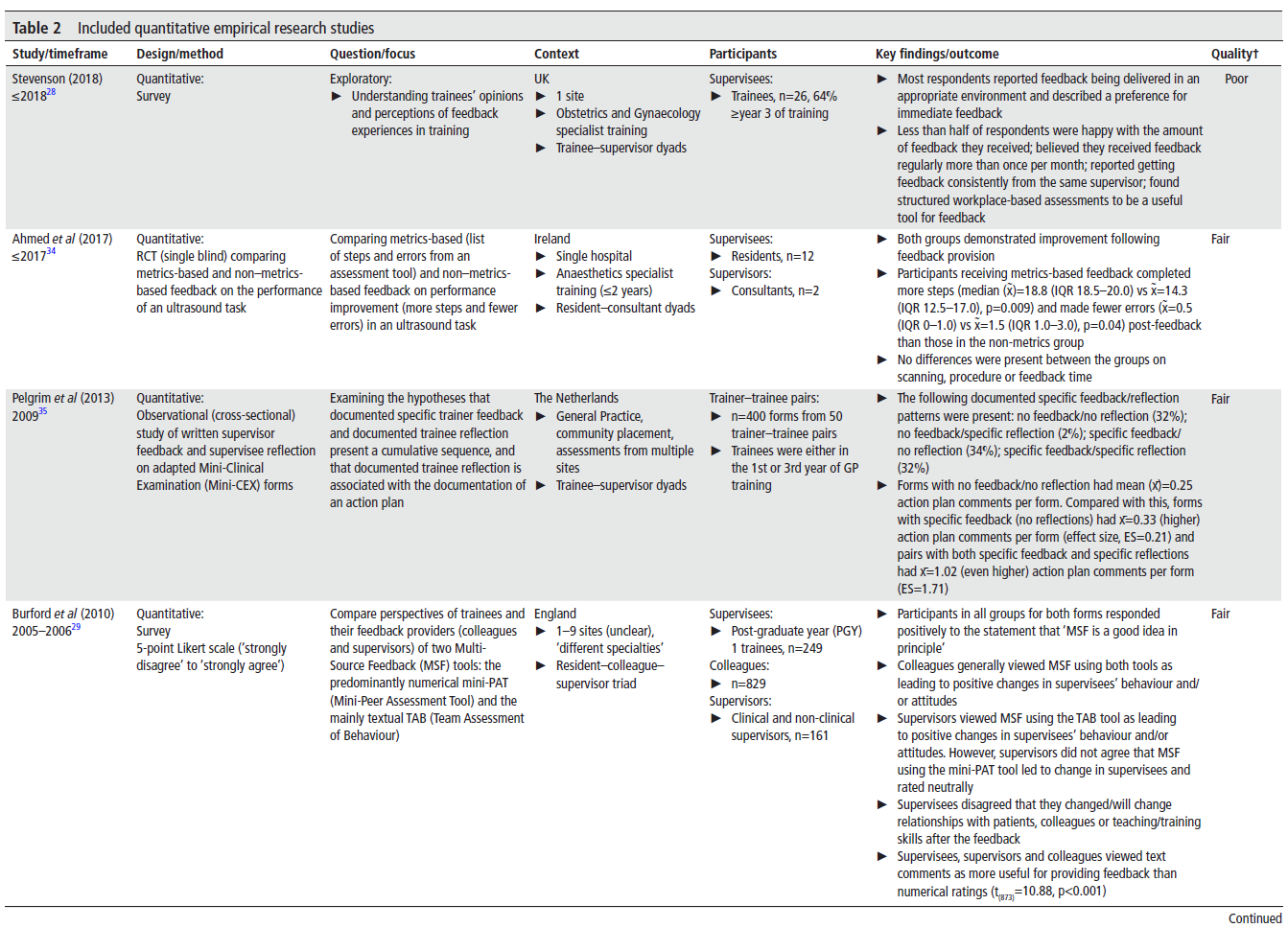
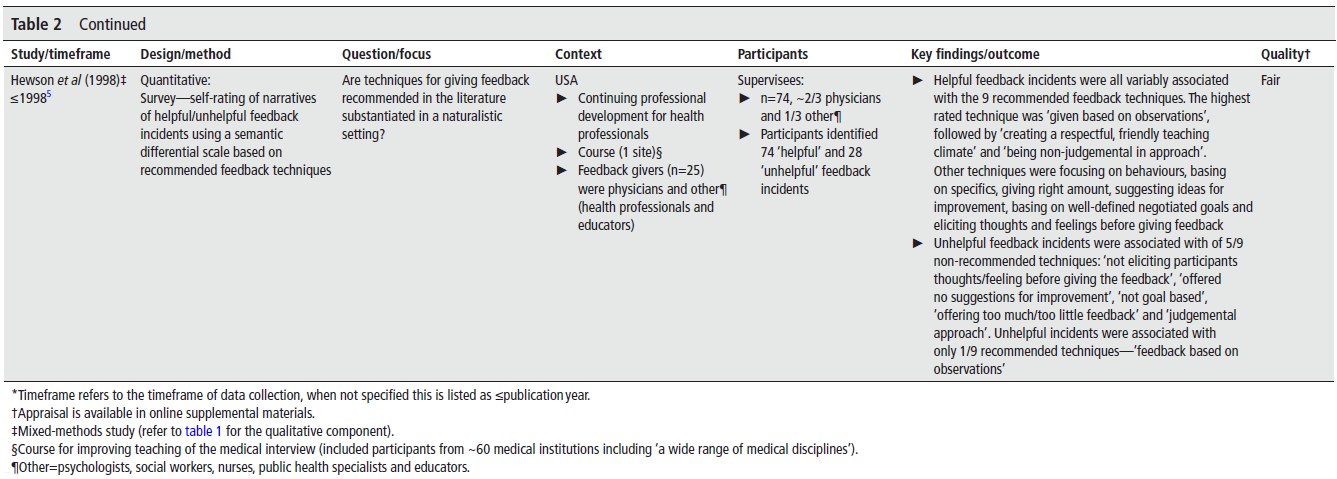
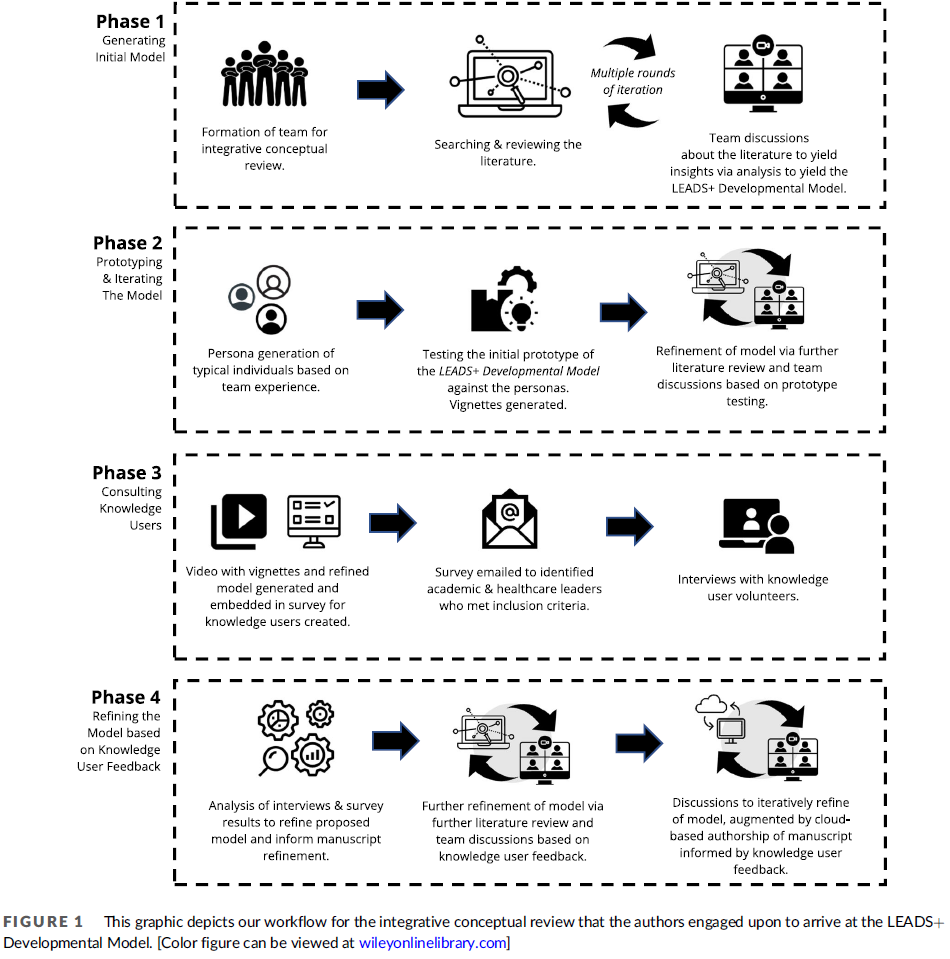
FUTURE-AI: international consensus guideline for trustworthy and deployable artificial intelligence in healthcare

🧠 의료 AI, 이제는 '신뢰'가 핵심입니다: FUTURE-AI 가이드라인이란?
AI가 의료 분야에서 진단과 예측, 환자 분류까지 정말 많은 일을 할 수 있게 되면서,
이제는 “기술이 가능한가?”보다 “그 기술을 믿을 수 있나?”가 더 중요한 질문이 되었어요.
바로 이런 이유에서 국제 전문가들이 모여 만든 게 바로 👉 FUTURE-AI 프레임워크입니다.
AI가 기술적으로도 탄탄하고, 임상적으로도 안전하며, 윤리적·사회적으로도 책임감 있게 작동할 수 있는 기준을
전 세계 117명의 전문가가 모여 2년에 걸쳐 만든 거죠.
🔍 FUTURE-AI란?
FUTURE-AI는 6가지 핵심 원칙으로 구성돼 있어요:
- 공정성 (Fairness)
- 보편성 (Universality)
- 추적가능성 (Traceability)
- 사용가능성 (Usability)
- 견고성 (Robustness)
- 설명가능성 (Explainability)
"To increase adoption in the real world, it is essential that AI tools are trusted and accepted by patients, clinicians, health organisations, and authorities."
→ “현실 세계에서 AI 도구가 채택되기 위해서는 환자, 의사, 의료기관, 규제기관의 신뢰와 수용이 필수적이다.”
🌍 각 원칙이 말하는 건 뭘까?
✅ 공정성 (Fairness)
AI는 모든 사람에게 동등하게 작동해야 해요. 성별, 연령, 인종, 사회경제적 배경과 관계없이 말이죠.
예를 들어 “대표성 있는 데이터로 학습시키기”가 핵심 전략 중 하나예요.
✅ 보편성 (Universality)
한 병원에서만 잘 작동하면 안 되겠죠? 다양한 환경과 사용자에게도 일반화될 수 있어야 해요.
그래서 “외부 데이터로도 검증하고”, “다양한 기준에 맞춘 평가”가 필요해요.
✅ 추적가능성 (Traceability)
AI가 왜 그런 결정을 내렸는지, 어떻게 개발됐는지, 투명하게 추적할 수 있어야 해요.
"AI traceability will also enable continuous auditing of AI models..."
→ “AI 추적 체계는 모델의 **지속적인 감사(auditing)**를 가능하게 해준다.”
✅ 사용가능성 (Usability)
의사나 간호사, 환자들이 쉽게 쓸 수 있어야 의미가 있죠.
“사용자 교육”이나 “인간-AI 상호작용 설계” 같은 부분이 여기에 포함돼요.
✅ 견고성 (Robustness)
데이터가 살짝 달라져도 AI가 무너지지 않도록 만드는 게 핵심이에요.
"Healthcare AI tools should be designed and developed to be robust against real world variations..."
→ “의료 AI 도구는 현실 세계의 데이터 변이에 견딜 수 있도록 설계되어야 한다.”
✅ 설명가능성 (Explainability)
결과만 딱 보여주는 AI는 불안하죠?
왜 그런 판단을 내렸는지 설명해 줄 수 있어야 의사도, 환자도 신뢰할 수 있어요.
💬 여기에 더해지는 7가지 ‘일반 권고사항’
이 6가지 원칙을 뒷받침하기 위해 다음과 같은 7가지 공통 권고도 함께 제시되었어요.
- 지속적인 이해관계자 참여
- 철저한 데이터 보호
- AI 리스크 관리 전략 수립
- 적절한 평가 계획 수립
- 관련 규제 준수
- 분야별 윤리 쟁점 고려
- 사회·환경적 영향까지 고려 → 예: 탄소발자국 감소 전략 필요
“AI developers should consider strategies to reduce the carbon footprint of the AI tool.”
→ “AI 개발자는 해당 도구의 **탄소 발자국(carbon footprint)**을 줄일 수 있는 전략을 고려해야 한다.”
🛠 어떻게 적용할 수 있을까?
FUTURE-AI는 단지 이론만 말하지 않아요. 설계 → 개발 → 검증 → 배포까지 AI의 생애주기를 단계별로 정리해, 어떻게 실제로 적용할 수 있을지까지 안내해 줍니다. 이 부분은 Figure 3에서 시각적으로 아주 잘 설명되어 있어요. 👇
📌 마무리하며
의료 분야에서 AI는 이제 선택이 아닌 필수지만, ‘신뢰할 수 있는 AI’를 만드는 건 결코 자동으로 되지 않아요.
FUTURE-AI는 그 신뢰의 기준을 마련해 주는 강력한 로드맵이에요.
"This paper addresses an important gap in the field of healthcare AI by delivering the first structured and holistic guideline for trustworthy and ethical AI in healthcare."
→ “이 논문은 의료 AI에서 신뢰 가능하고 윤리적인 개발을 위한 최초의 구조화된 가이드라인을 제시함으로써 중요한 공백을 메운다.”
서론 (Introduction)
보건의료 분야에서는 자기학습(self-learn) 능력을 가진 알고리즘, 즉 **인공지능(Artificial Intelligence, AI)**과 데이터 상호작용을 이용해 질병 진단, 예후, 치료 반응 또는 생존율 예측, 환자 분류(patient stratification) 등을 위한 컴퓨터 기반 모델이 점점 더 많이 개발되고 있다¹. 하지만 상당한 기술적 진보에도 불구하고, AI 기술의 실제 임상 현장 적용과 채택은 여전히 제한적이다. 최근 몇 년간, 보건의료 AI와 관련된 기술적, 임상적, 윤리적, 사회적 위험성에 대한 우려가 제기되었다² ³. 특히 기존 연구들은 보건의료 분야의 AI 도구들이 오류와 환자 위해(harm), 편향성 및 건강 형평성 악화, 투명성과 책임성 부족, 데이터 프라이버시 및 보안 침해 등의 문제에 취약하다는 점을 보여주었다⁴⁻⁸.
현실 세계에서의 채택을 높이기 위해서는 AI 도구가 환자, 임상의, 의료기관, 규제 당국 등에게 신뢰를 받아야 하며 수용되어야 한다. 그러나 보건의료 AI 도구가 신뢰받을 수 있도록 어떻게 설계, 개발, 평가, 배포되어야 하는지에 대한 명확하고 널리 수용되는 가이드라인은 부재한 상황이다. '신뢰할 수 있는(trustworthy)' AI란 기술적으로 견고하고, 임상적으로 안전하며, 윤리적으로 정당하고, 법적으로도 적합한 것을 의미한다(용어 정의는 부록 표 1 참고)⁹. 실질적인 영향을 전 세계적으로 미치기 위해서는, 이러한 책임 있는 AI를 위한 가이드라인이 국제적이고 학제 간 전문가들의 폭넓은 합의를 통해 도출되어야 한다.
다른 분야에서는 국제적 합의에 기반한 가이드라인이 지속적인 영향을 만들어낸 바 있다. 예를 들어, 데이터 관리를 위한 FAIR 원칙¹⁰은 연구자, 기관, 정부 당국 등에서 널리 채택되고 있다. 이 원칙은 데이터 수집, 정제, 조직화, 저장 등의 업무를 표준화하고 향상시키는 체계적 틀을 제공한다. 물론 FAIR 원칙이 프라이버시와 보안보다는 **데이터의 발견가능성(findability), 접근성(accessibility), 상호운용성(interoperability), 재사용성(reusability)**에 초점을 두기 때문에 데이터 관리의 모든 측면을 아우르지는 않는다는 비판도 있다. 그럼에도 불구하고 FAIR는 **이제 널리 수용되고 실제로 적용되는 실천 규범(code of practice)**을 제공하고 있다.
보건의료 분야의 AI는 다른 분야와는 독특한 속성을 지닌다. 대표적으로, 의사와 환자 사이의 신뢰(trust) 관계가 중요한데, 이는 대부분의 환자들이 의사의 진단이나 치료 결정을 객관적으로 평가할 수 있는 기회가 거의 없기 때문이다. 이러한 맥락에서, AI 시스템은 기술적으로 견고하고 임상적으로 안전할 뿐만 아니라, 윤리적으로 정당하고 투명해야 하며, 환자가 의료진에게 두는 신뢰를 해치지 않도록 해야 한다. 그러나 비-AI 도구와 달리, AI는 그 복잡한 데이터 처리 방식으로 인해 작동 원리에 대한 투명성이 부족한 경우가 많다. 기존 의료 장비와 달리, AI는 아직까지 보편적으로 수용되는 품질보증 지표가 존재하지 않는다. 대중과의 상호작용이 활발한 채팅 도우미나 이미지 생성기와는 달리, 보건의료는 작은 오류도 중대한 결과로 이어질 수 있는 민감한 영역이다. 따라서 보건의료에 특화된 신뢰할 수 있는 AI 개발을 위한 명확한 기준 마련이 시급하다.
초기 노력들은 주로 의료 분야 또는 특정 임상 과업에 대한 AI 연구 보고 방식에 대한 권고안(예: TRIPOD+AI¹¹, CLAIM¹², CONSORT-AI¹³, DECIDE-AI¹⁴, PROBAST-AI¹⁵, CLEAR¹⁶)에 집중되어 왔다. 하지만 이들 가이드라인은 AI 도구의 실제 개발과 배포를 위한 모범 사례를 제시하기보다는, 개발 및 평가 과정의 보고를 표준화하고 완전하게 만드는 데 초점을 맞춘 것이다. 최근에는 여러 연구자들이 **보건의료 AI를 위한 모범 사례(best practice)**에 대한 유망한 아이디어들을 제시한 바 있으나¹⁷⁻²⁴, 이러한 제안들은 국제적 합의에 기반하지 않았고, AI의 전체 생애주기(lifecycle)—즉 설계, 개발, 검증부터 배포, 사용, 모니터링에 이르기까지—를 모두 포괄하지 못한다.
다른 이니셔티브에서는 **세계보건기구(World Health Organization)**가 주요 윤리 및 법적 쟁점에 대한 보고서를 발행했으나, 이는 주로 보건부나 정부 기관을 위한 것으로 기술적·임상적 측면은 다루지 않았다²⁵. 마찬가지로, 유럽 인공지능 고위 전문가 그룹은 AI 개발자를 위한 **종합적인 자기 점검 체크리스트(self-assessment checklist)**를 제시했지만, 이는 전반적인 AI를 대상으로 하였을 뿐, 보건의료 분야의 특수한 위험성과 도전과제를 충분히 반영하지 못했다²⁶.
이 논문은 보건의료 AI 분야에서 신뢰할 수 있고 윤리적인 AI 개발을 위한, 구조화되고 포괄적인 첫 번째 가이드라인을 제시함으로써, 이 분야의 중대한 공백을 해소하고자 한다. 이 가이드라인은 전 세계의 폭넓은 전문가 합의에 기반하고 있으며, AI의 전체 생애주기를 포괄한다. FUTURE-AI 컨소시엄은 2021년에 시작되었으며, 현재 50개국에서 모인 117명의 국제적이고 학제 간 전문가들(그림 1)로 구성되어 있다. 이들은 유럽, 북미, 남미, 아시아, 아프리카, 오세아니아 등 전 대륙을 대표하며, 데이터 과학, 의학 연구, 임상 의학, 컴퓨터 공학, 의료 윤리, 사회과학 등 다양한 분야와 영상의학, 유전체학, 모바일 헬스, 전자의무기록(EHR), 외과, 병리학 등 다양한 데이터 도메인을 대표한다. FUTURE-AI 프레임워크를 개발함에 있어, 우리는 FAIR 원칙에서 영감을 받아, 다음의 여섯 가지 핵심 원칙에 따라 간결한 권고안을 정의하였다: 공정성(Fairness), 보편성(Universality), 추적가능성(Traceability), 사용가능성(Usability), 견고성(Robustness), 설명가능성(Explainability) (그림 2 참조).

방법 (Methods)
FUTURE-AI는 보건의료 분야에서 신뢰할 수 있고 윤리적인 인공지능(AI)을 실현하기 위한 지침 원칙과 단계별 권고사항을 제공하는 구조화된 프레임워크이다. 이 가이드라인은 수정된 델파이 기법(modified Delphi approach)²⁷ ²⁸을 통해 24개월간의 국제적 합의를 거쳐 수립되었다. 과정은 여섯 가지 핵심 원칙을 정의하는 것으로 시작하여, 초기 권고사항 세트를 마련한 후 총 8차례의 폭넓은 피드백 수렴 및 반복적인 논의를 통해 합의에 도달하는 방식으로 진행되었다. 결과 종합을 위해 두 가지 상호보완적인 방법이 사용되었다. 하나는 **정량적 접근법(quantitative approach)**으로, 전문가들의 투표 양상을 분석하여 합의와 이견의 영역을 식별하는 방식이며, 다른 하나는 **정성적 접근법(qualitative approach)**으로, 반복적으로 제기된 주제나 새로운 통찰에 기반해 피드백과 논의를 종합하는 방식이다.
FUTURE-AI 지침 원칙의 정의: 의료 분야에서 신뢰할 수 있는 AI에 대한 사용자 친화적인 지침을 개발하기 위해, 우리는 FAIR 원칙과 동일한 방식, 즉 최소한의 핵심 원칙 세트를 기반으로 접근하였다. 이러한 상위 원칙의 정의는 모범 사례의 구조화 및 간소화뿐 아니라, 향후 최종 사용자의 실제 적용을 용이하게 만든다.
이를 위해 우리는 우선 신뢰할 수 있는 AI 및 그와 관련된 개념(책임 있는 AI, 윤리적 AI, AI 배포 등)에 대한 보건의료 AI 분야의 기존 문헌을 검토하였다. 또한 AI 보고, 평가에 관한 가이드라인이나 EU, 미국 FDA, WHO 등 공공기관의 권고사항이나 입장문도 추가적으로 조사하였다. 이 검토를 통해 우리는 신뢰할 수 있는 AI를 위해 자주 언급되는 다양한 요건과 요소들을 폭넓게 파악할 수 있었다²⁹ ³⁰. 이후 라운드에서도 전문가 조언과 범위 확장을 반영하여 문헌 검토를 점차적으로 확대하였다(3라운드 참고).
표 1에 제시된 바와 같이, 이러한 요건들은 주제별로 그룹화되어 여섯 가지 핵심 원칙(즉, 공정성(fairness), 보편성(universality), 추적가능성(traceability), 사용가능성(usability), 견고성(robustness), 설명가능성(explainability))으로 정리되었고, 기억하기 쉬운 약어인 FUTURE-AI로 구성되었다.

1라운드: 초기 권고사항 정의
각 핵심 원칙을 개별적으로 탐색하기 위해, 전문가 3명씩 구성된 6개의 작업 그룹이 구성되었다(임상의, 데이터 과학자, 컴퓨터 공학자 포함). 이들은 EuCanImage, ProCAncer-I, CHAIMELEON, PRIMAGE, INCISIVE 등 5개 유럽 프로젝트에서 모집되었으며, 함께 **의료 영상 AI(AI for medical imaging)**라는 공통 사례를 중심으로 활동하였다. 각 작업 그룹은 문헌을 철저히 검토한 후, 해당 원칙의 정의와 함께 6~10개의 초기 모범 사례(best practices) 목록을 제안하였다.
이후 온라인 회의 및 이메일을 통해 반복적인 정제 과정이 진행되었으며, 이 과정에서 중복이나 내용 중첩이 발견되었다. 예컨대, 편향성 보고에 대한 권고사항은 원래 공정성과 추적가능성 두 원칙 모두에 제안되었고, 대표성 있는 데이터셋으로 모델 학습하라는 권고는 공정성과 견고성 모두에 포함되었다. 중복 항목을 제거하고 문구를 다듬은 결과, 총 55개의 초기 권고안이 도출되었으며, 이는 다음 라운드에서 보다 폭넓은 전문가 집단의 평가 및 논의를 위해 배포되었다.
2라운드: 온라인 설문조사
이 라운드에서는 FUTURE-AI 컨소시엄을 72명으로 확장하였다. 신규 참여자는 AI 과학자, 의료 실무자, 윤리학자, 사회과학자, 법률 전문가, 산업계 전문가 등으로 구성되었으며, 2~5라운드에 걸쳐 동일한 그룹이 참여하였다. 이들은 문헌, 전문가 네트워크, 온라인 검색을 통해 모집되었으며, 지리적 다양성과 보건의료 관련 분야의 대표성 확보를 중시하였다.
온라인 설문조사는 각 권고사항에 대해 다음의 5단계 평가 옵션으로 중요도를 평가하도록 구성되었다:
- 매우 필수적이다 (absolutely essential)
- 매우 중요하다 (very important)
- 평균적 수준의 중요성이다 (of average importance)
- 별로 중요하지 않다 (of little importance)
- 전혀 중요하지 않다 (not important at all)
또한 각 권고사항에 대해 문구 유지 또는 수정 제안, 권고 병합 또는 신규 추가 제안, 핵심 원칙과 전체 FUTURE-AI 가이드라인에 대한 자유 서술식 피드백도 포함되었다.
설문 응답은 정량적으로 분석되어 합의 수준을 평가하였다. 90% 이상의 동의를 받은 권고사항은 다음 논의로 선정되었고, 부정적 피드백이 많았던 권고사항, 특히 특정 기법을 일반 원칙보다 우선시한 항목은 제외되었다. 서면 피드백은 일부 권고사항을 병합하거나 문구를 간결하게 다듬는 데 활용되었다. 이 결과, 22개의 수정된 권고사항 목록과 함께, 향후 논의가 필요한 16개의 쟁점 항목이 도출되었다.
설문에서는 또한, 이 여섯 가지 원칙이 신뢰할 수 있는 의료 AI에 요구되는 다양성을 충분히 포착하고 있는지에 대한 피드백도 수집하였다. 대체로 긍정적인 합의가 이루어졌으나, 프라이버시, 사회적 고려, 규제 준수 등 보다 포괄적 주제를 포함할 수 있는 제7의 ‘일반’ 카테고리(general category) 도입이 제안되었다. 이 범주의 모범 사례는 여섯 원칙 전체에 공통으로 적용되는 내용(예: 다중 이해관계자 참여, general 1)이 포함되며, 반복 제시를 줄이는 역할도 한다.
3라운드: 축소된 권고안에 대한 피드백
2라운드에서 정제된 가이드라인은 다시 전문가 전원에게 배포되어 추가 피드백을 받았다. 이 라운드는 권고사항의 적절성과 표현 방식에 대한 평가가 중심이었고, 이전 설문에서 제기된 쟁점 항목들에 대한 의견도 수렴하였다. 예를 들어, 다기관(multicentre) 평가 vs 지역(local) 평가의 우선순위, 또는 AI 도구의 적대적 공격(adversarial attacks)에 대한 체계적 평가의 필요성 등이 쟁점으로 제시되었다.
전문가 피드백은 문구를 더욱 명확하게 다듬는 데 큰 역할을 했으며, 특히 여러 쟁점 항목의 합의 도출에 기여했다. 또한 이 라운드에서는 범위를 ‘의료 영상 AI’에서 ‘보건의료 전반의 AI’로 확대하였으며, 이는 대부분의 권고사항이 의료 전반에 적용 가능함을 확인한 데 따른 것이다. 결과적으로, **‘일반’ 카테고리 내 6개의 신규 권고사항을 포함해 총 30개의 최종 권고사항(best practices)**이 도출되었다. 여전히 합의되지 않은 일부 항목은 향후 논의를 위해 문서화되어 정리되었다.
4라운드: 권고사항에 대한 추가 피드백 및 평가
수정된 권고사항은 전문가들에게 서면 형식으로 재배포되어, 각 권고사항의 명확성, 실행 가능성, 관련성을 평가하도록 요청되었다. 이 단계에서는 권고사항의 표현을 보다 정밀하게 다듬을 수 있었다. 예를 들어, 원래는 AI 모델을 “다양하고 이질적인 데이터(diverse, heterogeneous data)”로 학습시켜야 한다는 권고였지만, 다수의 전문가가 “이질적(heterogeneous)”이라는 용어가 모호하며, “대표성 있는 데이터(representative data)”가 인구집단의 본질적 특성을 더 효과적으로 포착한다고 주장함에 따라 해당 용어로 수정되었다.
또한, AI 프로젝트의 목적과 필요에 따라 각 모범 사례의 적용 정도를 구분할 수 있는 평가 체계가 도입되었다. 특히 우리는 연구 단계 또는 개념 입증(proof-of-concept) 단계의 AI 도구와 임상 적용을 목표로 하는 AI 도구 사이의 구분을 강조하였다. 전자는 실험적 특성을 가지며 유연성이 필요한 반면, 후자는 환자 진료에 직접적으로 영향을 미치기 때문에 윤리성, 안전성, 유효성 측면에서 더 높은 수준의 준수 기준이 요구된다. 이 시점에서, 컨소시엄 전문가들은 각 권고사항에 대해 연구용 AI 도구와 임상 적용 가능한 AI 도구에 대해 각각 평가하였으며, 각 항목을 **“권장(recommended)” 또는 “강력 권장(highly recommended)”**으로 분류하였다.
5라운드: 원고에 대한 피드백
30개의 권고사항이 잘 정리된 상태에서, 제1저자와 마지막 저자가 FUTURE-AI 원고 초안을 작성하였다. 이 초안은 전문가들에게 배포되어 반복적인 피드백 세션을 통해 가이드라인의 정확성과 명확성을 확보하는 과정이 시작되었다. 이를 통해 임상, 기술, 비기술 전문가의 다양한 관점을 통합할 수 있었으며, 결과적으로 보다 읽기 쉬우며 폭넓은 독자층에게 접근 가능한 원고가 완성되었다. 전문가들은 권고사항을 보완하기 위한 추가 참고 문헌이나 자료를 제안할 수도 있었으며, 이 단계에서 실제 사례에서 모범 사례가 어떻게 구현될 수 있는지를 보여주기 위해 방법론 예시도 포함되었다.
6라운드: 새로운 “외부” 피드백 수렴
이번 라운드에서는 **기존 연구 단계에 참여하지 않았던 추가 전문가 44명(n=44)**을 초대하여 독립적인 피드백을 요청하였다. 이 집단은 환자 권익 옹호자, 사회과학자, 규제 전문가 등 전문영역의 다양성은 물론, 아프리카, 라틴 아메리카, 아시아 등 지리적 대표성 확대를 고려하여 선별되었다.
이 전문가들에게는 서면 피드백과 함께 각 권고사항에 대한 의견을 투표 형식(찬성, 반대, 중립, 이해하지 못함, 의견 없음)으로 제출하도록 요청하였다. 명확한 합의에 이르지 못한 권고사항의 경우, 대부분이 문구의 모호함이나 오해에서 비롯된 것으로 파악되었다. 따라서 이 단계는 남아 있는 불명확하거나 논쟁적인 부분을 식별하고, 문장 표현을 정제함으로써 가이드라인이 다양한 의료 AI 커뮤니티 구성원들에게 명확하고 접근 가능하도록 만드는 데 큰 도움이 되었다.
7라운드: 온라인 합의 회의
이전 라운드의 피드백을 바탕으로, 일부 권고사항의 정확한 문구를 둘러싼 전문가 간 논쟁이 계속되는 주제들이 확인되었다. 이에 따라 2023년 6월에 총 4회의 온라인 회의를 열어 남아 있는 쟁점 사항들을 심화 논의하고 권고사항 및 문구에 대한 최종 합의를 도출하였다.
이 논의 과정에서는 여러 미해결 이슈들이 해결되었다. 예컨대, AI 도구를 적대적 공격(adversarial attacks)에 대해 체계적으로 검증할 것이라는 권고는 사이버 보안 영역에 속한다는 의견에 따라 유사한 우려들과 함께 분류되었다. 또한, 임상 평가를 제3자가 수행해야 한다는 권고는 특히 자원이 부족한 환경에서는 실행이 어렵다는 이유로 현실적으로 조정되었다. 이 합의 회의 결과, 최종 FUTURE-AI 권고안의 전체 목록과 각 권고사항의 문구가 완성되었으며, 이에 대한 상세 내용은 표 2에 정리되어 있다.
8라운드: 최종 합의 투표
마지막 단계에서는, 도출된 권고사항에 대한 최종 투표가 온라인 설문을 통해 이루어졌다. 이 시점에서 FUTURE-AI 컨소시엄의 최종 구성원은 117명으로, 이는 2라운드의 72명, 6라운드의 44명 중 응답한 전문가들, 그리고 몇몇 추가 전문가들이 포함된 수치였다. 이 최종 투표 결과, 전체 권고사항은 모든 FUTURE-AI 구성원의 5% 미만 이견을 남기고 승인되었다.
남은 소수의 이견은 대부분, 권고사항이 “권장(recommended)”인지 “강력 권장(highly recommended)”인지의 분류에 관한 것이었다.
FUTURE-AI 가이드라인
이 섹션에서는 여섯 가지 핵심 지침 원칙 각각에 대한 정의와 정당성, 그리고 FUTURE-AI 권고사항에 대한 개요를 제시한다. 표 2에는 각 권고사항과 함께, 권고 수준(예: 권장(recommended) 또는 강력 권장(highly recommended) 여부)이 요약되어 있다. 참고로, 부록의 **보충 표 1(supplementary table 1)**에는 본 논문에서 사용된 주요 용어에 대한 용어집이, **보충 표 2(supplementary table 2)**에는 FUTURE-AI 프레임워크와 관련된 주요 이해관계자 목록이 포함되어 있다.
공정성(Fairness)
공정성(fairness) 원칙은 보건의료 분야의 AI 도구가 개인 간, 또는 집단 간(대표성이 부족하거나 소외된 집단 포함)에서 동일한 수준의 성능을 유지해야 한다는 것을 의미한다. AI 기반의 의료 서비스는 모든 시민에게 동등하게 제공되어야 하며, 보건의료 AI에서 발생하는 **편향(bias)**은 개인 특성(예: 성별, 연령, 인종, 사회경제적 지위, 건강 상태 등)이나 **데이터 속성(예: 데이터 수집 기관, 사용 장비, 조작자, 주석자 등)**의 차이로부터 비롯될 수 있다. 실제로 완전한 공정성을 달성하는 것은 불가능할 수도 있기 때문에, 공정한 AI 도구는 잠재적인 편향을 식별, 보고, 최소화하여, 가능한 한 모든 하위 집단에서 동일하거나 적어도 매우 유사한 성능을 보장하도록 개발되어야 한다¹³. 이러한 목표를 달성하기 위해 FUTURE-AI 프레임워크에서는 다음 세 가지 **공정성 권고사항(fairness recommendations)**을 제시한다.
공정성 1: 편향의 원천 정의 (Fairness 1: Define sources of bias)
보건의료 AI에서 발생하는 편향은 사용 사례별로 다르게 나타난다³². 따라서 설계 단계에서 AI 개발을 담당하는 학제 간 팀(용어집 참고)은 해당 AI 도구에 적용될 수 있는 편향의 유형과 원인을 식별해야 한다³³. 여기에는 다음과 같은 항목들이 포함될 수 있다:
- 집단 특성: 성별, 연령, 인종, 사회경제적 배경, 지리적 위치 등
- 의료 프로필: 동반 질환, 장애 여부 등
- 데이터 수집 및 처리 과정에서의 편향: 인간 또는 기술적 편향(예: 데이터 수집자, 라벨링 과정, 피처 선택 등)
공정성 2: 개인 및 데이터 속성 정보 수집 (Fairness 2: Collect information on individual and data attributes)
편향을 식별하고 공정성을 향상시키기 위해, 다음과 같은 개인 특성에 대한 정보 수집이 필요하다:
- 성별, 연령, 인종, 위험 요인, 동반 질환, 장애 등
이 정보 수집은 반드시 윤리위원회의 승인과 사전 동의를 기반으로 이루어져야 하며, 비차별의 이점과 재식별 위험 간의 균형을 고려해야 한다. 또한 의료 프로필 간 유사성을 측정하는 것도 동일한 치료가 이루어졌는지를 검증하는 데 포함되어야 하며, 여기에 포함되는 요소는 다음과 같다:
- 위험 요인, 동반 질환, 생물학적 지표(biomarkers), 해부학적 특성 등³⁴
아울러 다음과 같은 데이터셋 속성도 체계적으로 수집해야 한다:
- 데이터가 수집된 기관, 사용된 장비, 전처리 및 주석 작업 과정 등
완전한 데이터 수집이 물리적으로 어렵거나 비현실적인 경우, 두 가지 대안을 고려할 수 있다:
- **결측 속성을 대체(imputation)**하거나
- 불완전한 데이터를 제거(removal)
이 선택은 AI 시스템의 구체적인 맥락과 요구 사항에 따라 사례별로 평가되어야 한다.
공정성 3: 공정성 평가 (Fairness 3: Evaluate fairness)
개인 및 데이터 속성 정보가 확보된 경우, 다음과 같은 **공정성 지표(fairness metrics)**를 이용한 편향 탐지 기법을 적용해야 한다¹³ ³⁵:
- True Positive Rate
- Statistical Parity
- Group Fairness
- Equalised Odds
식별된 편향을 교정하기 위해 다음과 같은 편향 완화(mitigation) 기법도 시험되어야 한다³⁶⁻⁴⁰:
- 데이터 리샘플링(data resampling)
- 편향 없는 표현(bias-free representations)
- Equalised odds 기반 후처리(postprocessing)
이러한 방법이 AI 도구의 공정성과 전체 모델 정확도에 어떤 영향을 미치는지 확인해야 한다. 무엇보다도, 남아 있는 편향은 반드시 문서화하여 보고해야 하며, 이는 최종 사용자 및 시민들에게 정보를 제공하는 수단이 되어야 한다(→ 추적가능성 2(traceability 2) 항목 참조).
보편성 (Universality)
보편성(universality) 원칙은 보건의료 AI 도구가 그것이 개발된 통제된 환경 외부에서도 일반화될 수 있어야 한다는 점을 강조한다. 구체적으로는, AI 도구가 새로운 환자와 새로운 사용자(예: 새로운 임상의)에게도 일반화되어야 하며, 필요한 경우 **새로운 임상 현장(clinical site)**에도 적용 가능해야 한다. 적용 범위(radius of application)의 규모에 따라, **보건의료 AI 도구는 가능한 한 상호운용성(interoperability)과 전이 가능성(transferability)**을 갖춰야 하며, 이를 통해 더 많은 시민과 임상의에게 혜택을 줄 수 있어야 한다. 이를 위해 FUTURE-AI 프레임워크에서는 다음 네 가지 보편성 권고사항을 제시한다.
보편성 1: 임상 환경 정의 (Universality 1: Define clinical settings)
AI 도구를 설계하는 초기 단계에서, 개발팀은 해당 도구가 적용될 임상 환경을 명확히 정의해야 한다. 예를 들면 다음과 같다:
- 1차 진료기관(primary healthcare centres), 병원, 가정 기반 진료(home care)
- 자원 수준이 낮은 환경과 높은 환경(low vs high resource settings)
- 단일 국가 또는 다국가 적용 등
또한 보편성 확보에 장애가 될 수 있는 요인들—예: 최종 사용자 차이, 임상 용어 정의의 불일치, 의료 장비나 정보기술(IT) 인프라의 차이—를 예측하고 준비해야 한다.
보편성 2: 기존 표준 활용 (Universality 2: Use existing standards)
AI 도구의 품질과 상호운용성을 보장하기 위해, 도구 개발 시에는 이미 정의된 커뮤니티 기반의 표준을 기반으로 해야 한다. 예를 들면 다음과 같은 표준들이 있다:
- 질병에 대한 의학 학회의 정의
- 의료 온톨로지: 예) SNOMED CT (Systematized Nomenclature of Medicine Clinical Terms)⁴¹
- 데이터 모델: 예) OMOP (Observational Medical Outcomes Partnership)⁴²
- 인터페이스 표준: 예) DICOM (Digital Imaging and Communications in Medicine), FHIR (Fast Healthcare Interoperability Resources), HL7 (Health Level Seven)
- 데이터 주석(annotation) 프로토콜, 평가 기준(evaluation criteria)²¹
- 기술 표준: IEEE⁴³, ISO⁴⁴ 등²¹ ⁴¹⁻⁴⁴
보편성 3: 외부 데이터로 평가 (Universality 3: Evaluate using external data)
**일반화 가능성(generalisability)**을 평가하기 위해, AI 도구의 기술적 검증은 모델 학습에 사용되지 않은 외부 데이터셋으로 수행되어야 한다⁴⁵. 이 외부 데이터셋은 해당 작업에 적합하며, 현실 세계에서의 변이를 반영할 수 있는 기준(reference) 또는 벤치마크 데이터셋일 수 있다.
단일 기관(single centre)용 AI 도구가 아닌 경우, 임상 평가 연구는 여러 기관에서 수행되어야 하며, 이를 통해 다양한 임상 워크플로우 간의 성능 및 상호운용성을 평가할 수 있다⁴⁶. 만약 도구의 일반화 성능이 제한적이라면, **전이 학습(transfer learning)**이나 **도메인 적응(domain adaptation)**과 같은 **보완 조치(mitigation measures)**를 적용하고 검증해야 한다.
보편성 4: 지역 임상 유효성 평가 (Universality 4: Evaluate local clinical validity)
임상 환경은 인구 구성, 장비, 임상 워크플로우, 최종 사용자 등 여러 측면에서 상이하다. 따라서 각 기관에서의 신뢰(trust)를 확보하기 위해, AI 도구는 지역 단위의 임상 유효성(local clinical validity) 평가를 거쳐야 한다¹⁷. 특히, AI 도구는 지역의 임상 워크플로우에 적합하고, 해당 지역 인구에 대해 양호한 성능을 보여야 한다. 지역 평가 시 성능이 저하된다면, **모델의 재보정(recalibration)**이 필요하며, 예를 들어 **미세조정(fine tuning)**을 통해 수행할 수 있다.
추적가능성 (Traceability)
추적가능성(traceability) 원칙은, 의료 AI 도구가 개발, 검증, 배포, 활용에 이르기까지 전체 생애 주기를 문서화하고 모니터링할 수 있는 체계를 갖추어야 한다는 점을 강조한다. 이러한 추적 체계는 AI 도구의 전 생애에 걸쳐 임상의, 의료기관, 시민 및 환자, AI 개발자, 규제 당국 등 다양한 이해관계자에게 상세하고 지속적인 정보를 제공함으로써, 투명성과 책임성을 제고한다. 또한, AI 추적 체계는 모델의 지속적인 감사(auditing), 위험 및 한계 식별, 필요 시 모델 업데이트를 가능하게 한다⁴⁷.
추적가능성 1: 위험관리 체계 구축 (Traceability 1: Implement risk management)
AI 도구의 생애 전반에 걸쳐, 학제 간 개발팀은 다음을 수행해야 한다:
- 잠재적 위험 분석,
- 위험 발생 가능성과 영향도, 위험-편익 균형 평가,
- 위험 완화 방안 정의 및 지속적 모니터링,
- 위험 관리 파일(risk management file) 유지.
여기에는 FUTURE-AI 원칙에서 다루는 위험(예: 편향, 환자 위해, 데이터 유출)뿐 아니라, 사용 사례별 위험도 포함된다. 예를 들어:
- 사용자 교육 부족 또는 지침 미준수로 인한 오용(human factors)
- 타겟 인구에 속하지 않는 개인에 대한 적용
- 의료진이 아닌 기술자가 사용하는 경우
- 하드웨어 오류, 잘못된 주석 또는 입력값, 적대적 공격(adversarial attacks) 등
완화 방안에는 다음이 포함될 수 있다:
- 사용자 경고, 시스템 종료, 입력 데이터 재처리, 새로운 데이터 획득, 대체 절차 또는 인간의 판단만 사용 등.
- 위험의 모니터링 및 재평가는 고객 피드백, 민원, 실제 성능 로그 데이터 등 다양한 경로를 통해 이루어져야 한다 (→ 추적가능성 5 참고).
추적가능성 2: 문서화 수행 (Traceability 2: Provide documentation)
투명성, 추적가능성, 책임성 강화를 위해, 다음과 같은 **적절한 문서화(documentation)**가 마련되고 유지되어야 한다⁴⁸:
- (a) AI 정보 리플렛: 시민과 의료인을 위한 사용 목적, 위험(예: 편향), 사용 지침 안내
- (b) 기술 문서: AI 개발자, 의료기관, 규제 당국을 위한 AI 모델 특성(예: 하이퍼파라미터), 학습/테스트 데이터, 평가 기준 및 결과, 편향과 한계, 정기 감사 및 업데이트 내용⁴⁹⁻⁵¹
- (c) AI 보고 표준에 기반한 학술 논문 제출¹³ ¹⁵ ⁵²
- (d) 위험 관리 파일 (→ 추적가능성 1)
추적가능성 3: 지속적 품질관리 체계 구축 (Traceability 3: Implement continuous quality control)
AI 도구는 입력 및 출력의 지속적인 모니터링과 품질 관리 체계를 갖춘 상태로 개발 및 배포되어야 한다⁴⁷. 다음과 같은 항목을 식별하는 메커니즘이 포함되어야 한다:
- 누락되었거나 범위를 벗어난 입력 변수
- 불일치한 데이터 형식 또는 단위
- 잘못된 주석 또는 전처리 오류
- 오류 또는 비현실적인 AI 출력
또한 AI의 판단에 대한 품질 평가를 위해, **결과 신뢰도에 대한 불확실성 추정값(uncertainty estimates)**이 제공되어야 하며, 보정(calibration)³³되어야 한다. 이는 최종 사용자에게 결과의 신뢰 수준을 안내하기 위함이다⁵⁴.
추적가능성 4: 정기적 감사 및 업데이트 체계 구축 (Traceability 4: Implement periodic auditing and updating)
AI 도구는 **정기적 감사(auditing)**를 위한 구성 가능한 시스템과 함께 개발 및 배포되어야 한다⁴⁷. 이 시스템은 다음을 포함해야 한다:
- 감사에 사용할 데이터셋, 평가 주기(예: 매년 등)의 명확한 정의
- 이를 통해 데이터나 개념의 드리프트(drift), 새롭게 나타나는 편향, 성능 저하, 사용자 결정 방식의 변화를 식별할 수 있어야 한다⁵⁵.
- 이에 따라 AI 모델이나 도구에 필요한 업데이트가 이루어져야 한다⁵⁶.
추적가능성 5: AI 로깅 시스템 구축 (Traceability 5: Implement AI logging)
추적가능성과 책임성 강화를 위해, AI 로깅(logging) 시스템이 도입되어야 한다. 이 시스템은 다음을 수행해야 한다:
- 사용자의 주요 행동을 프라이버시를 보호하면서 기록
- 접근하고 사용하는 데이터 명시
- AI의 예측 결과와 그에 따른 임상적 결정 기록
- 발생한 문제 상황 로그화
또한 시간대별 통계와 시각화 자료를 활용하여, AI 도구의 사용 추세와 변화를 모니터링해야 한다.
추적가능성 6: AI 거버넌스 체계 구축 (Traceability 6: Implement AI governance)
AI 도구가 배포된 이후에는 **거버넌스 체계(AI governance)**가 명확히 정의되어야 한다. 특히 다음과 같은 역할을 담당할 주체가 지정되어야 한다:
- 위험관리, 정기 감사, 유지보수, 감독 등 → 예: IT팀, 의료행정 담당자 등
또한, AI 관련 오류에 대한 책임소재를 임상의, 의료기관, AI 개발자, 제조사 간 명확히 정의해야 한다. 개인 및 집단 수준의 책임 구조, 피해 환자에 대한 보상 및 지원 체계도 함께 마련되어야 한다.
사용가능성 (Usability)
사용가능성(usability) 원칙은, 최종 사용자가 실제 환경에서 임상적 목표를 효율적이고 안전하게 달성할 수 있도록 AI 도구를 사용할 수 있어야 한다는 점을 강조한다. 이 원칙은 두 가지 측면을 포함한다. 하나는, 사용자가 AI 도구의 기능과 인터페이스를 쉽게 사용하고 오류를 최소화할 수 있어야 한다는 것이며, 다른 하나는, AI 도구가 임상적으로 유용하고 안전해야 하며, 예를 들어 의료인의 생산성을 향상시키거나 환자의 건강 결과를 개선하고 위해를 피할 수 있어야 한다는 점이다.
이를 위해 FUTURE-AI 프레임워크는 다섯 가지 사용가능성 권고사항을 제시한다.
사용가능성 1: 사용자 요구사항 정의 (Usability 1: Define user requirements)
AI 개발자는 임상 전문가, 최종 사용자(예: 환자, 의사), 그리고 데이터 관리자, 행정 담당자 등 관련 이해관계자들과 초기 단계부터 협력하여 다음에 대한 정보를 수집해야 한다:
- AI 도구의 사용 목적 및 사용자 요구사항(예: 인간-AI 인터페이스)
- **AI 도구 사용에 영향을 줄 수 있는 인간 요인(human factors)**⁵⁷
예: 디지털 리터러시 수준, 연령대, 인체공학, 자동화 편향(automation bias)
특히, 기존 임상 워크플로우와의 적합성에도 주의가 필요하며, 이는 AI 시스템의 조직 수준 통합이나 기타 AI 보조 도구들과의 상호작용까지 포함한다. 다양한 이해관계자들 사이의 다수결 전략을 통해 가장 중요한 임상 이슈를 식별하는 방식은 해당 AI 도구가 개별 선호가 아닌 보편적 적용 가능성을 갖도록 설계하는 데 유용할 수 있다.
사용가능성 2: 인간-AI 상호작용 및 감독 체계 정의 (Usability 2: Define human-AI interactions and oversight)
사용자 요구사항을 바탕으로, AI 개발자는 다음 기능이 가능하도록 인터페이스를 구현해야 한다:
- 사용자가 AI 모델을 효과적으로 활용하고,
- 입력 데이터를 표준화된 방식으로 주석 처리하며,
- AI의 입력 및 결과를 검증할 수 있는 시스템을 구축해야 한다.
**의료 AI의 특성상 리스크가 크기 때문에, 인간의 감독(human oversight)**은 필수적이며 이는 정책 결정자 및 규제 기관의 요구 사항으로 점점 더 강조되고 있다¹⁷ ²⁶. 이에 따라 Human-in-the-loop 메커니즘이 설계되어야 하며, 이는 다음 기능을 포함해야 한다:
- 편향, 오류, 불합리한 설명 탐지,
- 필요 시 **AI 예측을 무효화하거나 무시(overrule)**할 수 있는 기능 등.
규제, 자동화의 이점, AI 자율성에 대한 환자 선호도는 사용 사례마다 다를 수 있으며 시간이 지남에 따라 변화할 수 있으므로⁵⁸,
**사용 사례별 인간 감독 체계 및 정기 감사·업데이트 체계(→ 추적가능성 4)**가 필요하다.
사용가능성 3: 사용자 교육 제공 (Usability 3: Provide training)
AI 도구를 최적으로 사용하고, 오류 및 위해를 줄이며, AI 리터러시를 높이기 위해, 개발자는 다음을 포함하는 교육 자료 또는 활동을 사용자 접근 가능한 형식과 언어로 제공해야 한다:
- 튜토리얼, 매뉴얼, 예시 등 자료
- 실습 중심 교육 세션(hands-on session) 등 활동
- 다양한 최종 사용자(전문의, 간호사, 기술자, 일반 시민, 관리자 등)를 고려해야 한다
사용가능성 4: 임상 사용성 평가 (Usability 4: Evaluate clinical usability)
AI 도구의 도입을 촉진하기 위해, 해당 도구의 지역 임상 워크플로우 내 사용성은 현실 세계(real world) 환경에서 대표성과 다양성을 반영한 사용자 집단을 대상으로 평가되어야 한다(예: 성별, 연령, 임상 역할, 디지털 숙련도, 장애 여부 등)
사용성 평가는 다음에 대한 정량적·정성적 증거를 수집해야 한다:
- 사용자 만족도, 성능, 생산성
- 사용에 영향을 미치는 인간 요인(human factors)
예: 자신감, 학습 용이성, 자동화 편향⁵⁷
사용가능성 5: 임상적 유용성 평가 (Usability 5: Evaluate clinical utility)
AI 도구는 **임상적 유용성(clinical utility)**과 안전성(safety) 측면에서 평가되어야 한다.
그 평가 결과는 다음과 같은 이점을 입증해야 한다:
- 환자에게: 조기 진단, 건강 결과 향상 등
- 의료인에게: 생산성 향상, 진료 품질 개선 등
- 의료기관에게: 비용 절감, 워크플로우 최적화 등
또한, AI 도구가 개인 또는 특정 집단에 위해를 초래하지 않는다는 점도 중요하다.
이러한 안전성은 **무작위 임상시험(randomised clinical trial)**을 통해 입증할 수 있다⁵⁹.
견고성 (Robustness)
견고성(robustness) 원칙은, 의료 AI 도구가 입력 데이터의 예상되거나 예상치 못한 변동 상황에서도 일관된 성능과 정확도를 유지할 수 있어야 한다는 것을 의미한다. 기존 연구에 따르면, 입력 데이터의 미세하고 인지하기 어려운 차이조차도 AI 모델이 잘못된 결정을 내리게 할 수 있다⁶⁰. 생의학 및 건강 데이터는 현실 세계에서 다양한 변이를 겪을 수 있으며(예상된 것과 예상되지 않은 것 모두 포함), 이는 AI 도구의 성능에 영향을 줄 수 있다. 따라서 의료 AI 도구는 이러한 실제 환경의 변이에 견딜 수 있도록 설계되고 개발되어야 하며, 이에 맞추어 평가 및 최적화되어야 한다. FUTURE-AI 프레임워크에서는 이를 위해 세 가지 견고성 권고사항을 제시한다.
견고성 1: 데이터 변이의 원인 정의 (Robustness 1: Define sources of data variations)
설계 단계에서, 개발팀은 해당 AI 도구에 요구되는 견고성 요건을 정의하고, 현실 세계에서 도구의 견고성에 영향을 줄 수 있는 변이의 원인 목록을 작성해야 한다. 여기에 포함될 수 있는 요인들은 다음과 같다:
- 의료 장비 간의 차이
- 장비의 기술적 결함
- 데이터 수집 또는 주석 처리 중 발생하는 이질성(heterogeneity)
- 적대적 공격(adversarial attacks)⁶⁰
견고성 2: 대표성 있는 데이터로 학습 (Robustness 2: Train with representative data)
AI 도구가 현실 세계의 임상 환경에서 마주하게 되는 다양한 변이를 충분히 반영한 데이터로 학습된다면, 임상의, 시민, 기타 이해관계자들은 해당 도구에 대해 더 높은 신뢰를 가질 가능성이 높다⁶¹. 따라서 학습 데이터셋은 설계 단계에서 정의된 변이 원인(→ 견고성 1 참조)을 바탕으로 **신중하게 선택, 분석, 보강(enrich)**되어야 한다.
대표성 있는 데이터로의 학습은 공정성 원칙 등 다른 원칙의 향상에도 기여한다. 예: 더 나은 편향 추정 및 편향 완화 가능성
견고성 3: 견고성 평가 (Robustness 3: Evaluate robustness)
AI 도구의 견고성을 평가하기 위한 평가 연구는 현실 세계 임상 실천에서 발생 가능한 다양한 변이 조건을 반영하는 방식으로 수행되어야 한다. 예:
- 데이터, 장비, 기술자, 임상의, 환자, 기관 간 변이 등
- 사용 가능한 평가 방법: 스트레스 테스트(stress test), 반복 가능성 테스트(repeatability test)⁶²
평가 결과에 따라 다음과 같은 **보완 조치(mitigation measures)**를 적용하고 검증해야 한다:
- 정규화(regularisation)⁶³
- 데이터 증강(data augmentation)⁶⁴
- 데이터 정합화(data harmonisation)⁶⁵
- 도메인 적응(domain adaptation)⁶⁶
설명가능성 (Explainability)
설명가능성(explainability) 원칙은, 의료 AI 도구가 그 결정의 논리에 대해 임상적으로 의미 있는 정보를 제공해야 한다는 점을 강조한다.
의료는 투명성, 신뢰성, 책임성이 요구되는 고위험 분야임에도 불구하고, 기계학습 기술은 종종 ‘블랙박스’로 불리는 복잡한 모델을 생성한다. 설명가능성은 기술적, 의학적, 윤리적, 법적, 환자적 관점에서 모두 바람직한 요소로 간주되며⁶⁷, 사용자가 다음을 수행할 수 있게 한다:
- AI 모델과 출력 해석
- AI 도구의 능력과 한계를 이해
- 필요시 개입 여부를 결정 (예: 사용할지 말지 판단 등)
그러나 설명가능성을 확보하는 작업은 기술적 난이도가 높고, 임상적으로 의미 있고 실용적인 설명을 확보하려면 개발 및 평가 과정에서 특별한 고려가 필요하다⁶⁸. 이를 위해 FUTURE-AI 프레임워크는 두 가지 설명가능성 권고사항을 제시한다.
설명가능성 1: 설명 요구사항 정의 (Explainability 1: Define explainability needs)
설계 단계에서, 최종 사용자 및 분야 전문가들과 함께 해당 AI 도구에 설명가능성이 필요한지 여부를 결정해야 한다. 설명이 필요한 경우, 다음과 같은 설명 요건을 함께 정의해야 한다:
- (a) 설명의 목적: 모델의 전반적인 동작 설명(global) vs 개별 결정 설명(local)
- (b) AI 설명에 적합한 접근법⁶⁹
- (c) 예상되는 한계 및 모니터링 항목: 예) 사용자가 AI의 결정에 과도하게 의존하는 현상⁶⁸
설명가능성 2: 설명방법 평가 (Explainability 2: Evaluate explainability)
설명 가능한 AI 방법은 정량적·정성적으로 모두 평가되어야 한다.
- 먼저 정량적으로는 계산 기반 평가 방법을 통해 설명의 정확성을 평가⁷⁰ ⁷¹
- 다음으로 정성적으로는 최종 사용자들과 함께 평가를 수행, 설명이 사용자 만족도, 신뢰도, 임상 성과에 미치는 영향을 확인⁷²
이러한 평가는 AI 설명의 한계도 식별해야 한다. 예:
- 설명이 임상적으로 일관되지 않거나³,
- 노이즈나 적대적 공격에 민감하거나⁷⁴,
- 설명이 실제보다 AI 결과에 대한 신뢰를 과도하게 높이는 경우⁷⁵
일반 권고사항 (General Recommendations)
마지막으로, FUTURE-AI 프레임워크에서는 보건의료 분야의 신뢰할 수 있는 AI의 모든 원칙에 적용 가능한 7가지 일반 권고사항을 정의하였다.
일반 1: 이해관계자와 지속적으로 소통하라
AI 도구의 생애 전반에 걸쳐, AI 개발자는 보건의료 전문가, 시민, 환자 대표, 윤리 전문가, 데이터 관리자, 법률 전문가 등 학제 간 이해관계자들과 지속적으로 소통해야 한다. 이러한 상호작용은 필요, 장애 요소, 수용 및 채택 경로에 대한 이해를 도모하고 예측하는 데 도움이 된다.
이해관계자 참여 방식에는 다음이 포함될 수 있다:
- 작업 그룹, 자문 위원회, 일대일 인터뷰
- 공동 창작 회의(co-creation meetings), 설문조사 등
일반 2: 데이터 보호를 보장하라
AI 생애주기 전반에 걸쳐 데이터 프라이버시 및 보안 보호를 위한 적절한 조치가 시행되어야 한다. 여기에 포함될 수 있는 기술 및 전략은 다음과 같다:
- 프라이버시 강화 기술 (예: 차등 프라이버시, 암호화)
- 데이터 보호 영향 평가(Data Protection Impact Assessment)
- 배포 이후의 데이터 거버넌스: 예) 데이터 접근 로그 시스템 (→ 추적가능성 5 참고)
비식별화(deidentification) 기법이 적용될 경우(예: 가명화(pseudonymisation), k-익명성(k-anonymity)), 시민 건강상의 이익과 재식별 위험 간의 균형을 신중하게 평가하고 고려해야 한다. 또한, **AI 도구에 대한 악의적 공격이나 적대적 위협(adversarial attacks)**으로부터 보호하기 위해, 제조사 및 배포자는 다음과 같은 사이버 보안 대책을 시행하고 주기적으로 평가해야 한다⁷⁶:
- 시스템 수준의 사이버보안 솔루션
- 애플리케이션 특화 방어기법 (예: 공격 탐지, 공격 완화 기법)
일반 3: AI 위험을 해결하기 위한 대책을 마련하라
개발 단계에서, 개발팀은 적용 사례에 특화된 요구사항을 반영하여 AI 모델링 계획을 수립해야 한다. 기초 AI 모델을 구현하고 테스트한 후, 이 모델링 계획에는 설계 단계에서 확인된 문제점과 위험 요인을 해결하기 위한 보완 전략이 포함되어야 한다 (→ 공정성 1 ~ 설명가능성 1 참조).
포함 가능한 보완 전략:
- 현실 세계 변이에 대한 견고성 향상: 정규화(regularisation), 데이터 증강, 데이터 정합화, 도메인 적응
- 임상 환경 간 일반화 향상: 전이 학습(transfer learning), 지식 증류(knowledge distillation)
- 소집단 간 편향 교정: 데이터 리샘플링, 편향 없는 표현, equalised odds 후처리
일반 4: 적절한 AI 평가 계획을 수립하라
신뢰와 채택을 높이기 위해, 테스트 데이터, 평가 지표, 비교 기준을 포함하는 평가 계획을 수립해야 한다.
- 첫째, 각 원칙의 평가에 적절한 테스트 데이터를 선정해야 하며,
특히 학습 데이터와 명확히 분리된 테스트 데이터를 사용하여 데이터 누수(data leakage)를 방지해야 한다⁷⁷. - 둘째, **각 지표의 장점과 한계를 고려하여 적절한 평가 지표(metrics)**를 선정해야 한다⁷⁸.
- 셋째, **기준이 되는 AI 도구 또는 기존 의료 관행과의 비교(benchmarking)**를 통해 모델 성능을 상대적으로 평가해야 한다.
일반 5: AI 규제를 준수하라
개발팀은 적용 대상 관할권(jurisdiction)과 시간에 따라 달라질 수 있는 AI 규제를 사전에 파악해야 한다. 예를 들어, **EU의 AI 법(AI Act)**에서는 모든 보건의료 분야의 AI 도구를 **고위험(high-risk)**으로 분류하며, 이에 따라 안전성, 투명성, 품질 관련 의무를 준수하고 적합성 평가를 거쳐야 한다. AI 도구의 용도 및 위험 수준에 따라 예상되는 규제 의무를 개발 초기부터 식별해두면, 후속 절차를 보다 효율적으로 준비할 수 있다.
일반 6: 적용 사례별 윤리적 쟁점을 조사하라
개인정보 보호, 투명성, 공정성, 자율성 등 의료 AI에서 잘 알려진 윤리 문제 외에도, AI 개발자, 분야 전문가, 전문 윤리학자는 다음을 수행해야 한다:
- 해당 적용 사례에 특화된 윤리적, 사회적, 사회문화적 쟁점을
- AI 도구의 개발 및 배포 과정에서 필수적으로 식별, 논의, 해결해야 한다⁷⁹.
일반 7: 사회적·환경적 이슈 조사하기 (General 7: Investigate social and environmental issues)
의료 인공지능(AI) 도구는 임상적, 기술적, 법적, 윤리적 함의 외에도 특정한 사회적·환경적 문제를 내포할 수 있다. 이러한 문제들은 AI 도구가 시민과 사회에 긍정적인 영향을 미치기 위해 반드시 고려되고 해결되어야 한다. 규제 기관이나 독립 기관은 지속가능성 기준을 충족하는 AI 도구에 대해 인증 또는 표시 제도를 운영할 수 있다. 이러한 접근은 투명성을 촉진하고, AI 도구의 환경적 영향에 대한 통찰을 제공하며, 친환경적 실천을 채택한 도구를 부각시키는 데 도움이 될 수 있다. 관련된 사회적 이슈에는 AI 도구가 의료 전문가 및 시민의 노동 환경과 권력 관계, 새로운 기술 습득(또는 기술 상실), 그리고 시민, 보건 전문가, 사회적 돌봄 종사자 간의 향후 상호작용에 미치는 영향이 포함될 수 있다⁸⁰.
또한 환경적 지속가능성을 위해, AI 개발자들은 AI 도구의 탄소 발자국(carbon footprint)을 줄이기 위한 전략도 고려해야 한다⁸¹.
FUTURE-AI 프레임워크의 실제 적용을 가능하게 하기 위해, 우리는 **AI 도구의 수명 주기 전반에 걸쳐 권장되는 모범 사례를 시간 순서대로 통합한 단계별 가이드(step-by-step guide)**를 제공한다. 이는 아래와 같이 네 가지 주요 단계로 구성된다:
- 설계(Design) 단계는 모든 관련 이해관계자를 참여시키고, 임상적, 기술적, 윤리적, 사회적 요구사항을 포괄적으로 분석하는 사람 중심(human-centred), 위험 인식(risk-aware) 전략으로 시작된다. 이 분석을 통해 **설계 명세 목록(specifications)**과 **모니터링이 필요한 위험 목록(예: 편향 가능성, 견고성 부족, 일반화의 어려움, 투명성 결여 등)**이 도출된다.
- 개발(Development) 단계에서는 효과적인 학습과 테스트를 위한 대표성 있는 데이터셋의 수집이 우선시된다. 이 데이터셋은 앞서 확인된 바와 같이 대상 설정, 장비, 프로토콜, 인구 집단의 다양성을 반영해야 한다. 또한, 초기 설계에서 도출된 요구사항과 위험 요소에 따라, 적절한 AI 개발 계획이 정의되고 실행되며, 여기에 위험 완화 전략과 사람 중심 메커니즘이 포함되어 기능적·윤리적 요구를 충족시켜야 한다.
- 검증(Validation) 단계에서는 단순한 시스템 성능뿐만 아니라 견고성(robustness), 공정성(fairness), 일반화 가능성(generalisability), 설명 가능성(explainability) 등 신뢰할 수 있는 AI의 모든 요소들을 포괄적으로 점검하며, 필요한 모든 문서화를 완료함으로써 마무리된다.
- 배포(Deployment) 단계는 현장(local) 유효성을 확보하고, 사용자 교육을 제공하며, 모니터링 메커니즘을 실행하고, 규제 요건 준수를 보장하여 실제 보건의료 환경에서 AI 도구가 채택되도록 한다.

FUTURE-AI의 실행(Operationalisation of FUTURE-AI)
이 절에서는 각 권고사항(recommendation)에 대한 실제적인 실행 단계의 목록을 구체적으로 제시하고, 각 단계의 실행을 위한 접근법과 방법론에 대한 예시를 함께 제공한다. 이러한 내용은 표 3, 표 4, 표 5, 표 6에 정리되어 있다. 이 접근은 FUTURE-AI 프레임워크의 **모든 최종 사용자(end users)**가 의료용 AI 도구를 설계, 개발, 검증, 배포할 때 참고할 수 있는 쉽고 단계별(step-by-step) 안내를 제공하는 것을 목표로 한다.
논의(Discussion)
최근 몇 년간 의료 인공지능(medical AI)에 대한 연구가 엄청나게 증가했음에도 불구하고, 실제로 임상 현장에 도입된 AI 도구는 극히 제한적이다. 많은 연구들이 AI가 의료를 개선할 수 있는 잠재력이 크다는 점을 보여주고 있지만, 여전히 임상적, 기술적, 사회윤리적, 법적 차원의 주요 도전과제들이 존재한다.
본 논문에서는 **신뢰할 수 있고 실제로 사용 가능한(trustworthy and deployable) 의료 AI 도구의 개발을 위한 국제적 합의 지침(consensus guideline)**을 수립하기 위한 노력을 소개하였다. 이를 위해 **FUTURE-AI 컨소시엄(FUTURE-AI Consortium)**이 조직되었으며, 이 컨소시엄은 다양한 분야와 이해관계자로부터 지식과 전문성을 제공받아, 지리적으로나 분야적으로나 폭넓은 지지를 확보한 합의 결과를 도출하였다.
총 **24개월에 걸친 반복적 과정(iterative process)**을 통해 FUTURE-AI 프레임워크가 완성되었으며, 이 프레임워크는 의료 AI의 전체 수명 주기를 포괄하는 30개의 포괄적이고 독립적인 권고사항들로 구성되어 있다. 또한, 이 권고사항들은 **6가지 주요 원칙(six guiding principles)**으로 분류되어 있으며, 이를 통해 **책임 있고 신뢰할 수 있는 AI로 가는 경로(pathway)**를 명확히 제시하고 있다. 이러한 광범위한 적용 범위 덕분에, FUTURE-AI 지침은 보건의료 분야의 다양한 이해관계자에게 이익이 될 수 있다는 점이 부록의 표 2에 상세히 설명되어 있다.
FUTURE-AI는 ‘위험 정보 기반(risk-informed)’ 프레임워크로, 각 AI 애플리케이션의 특수한 위험과 도전과제를 초기부터 평가할 것을 제안한다. 예를 들어, 차별(discrimination)의 위험, 일반화 불가능성, 데이터 드리프트(data drift), 최종 사용자로부터의 수용 부족, 환자에게 잠재적으로 미치는 해악, 투명성 결여, 데이터 보안 취약성, 윤리적 위험 등이 이에 해당한다. 이어서, 이러한 위험을 줄이기 위한 **맞춤형 대응 전략(measures)**을 실행할 것을 제안한다. 예를 들어, 개인의 특성에 대한 데이터를 수집하여 편향을 평가하고 완화할 수 있다.
그러나 실행되는 특정 조치에는 이점과 동시에 약점이 존재하므로, 개발자는 이를 사전에 평가하고 고려해야 한다. 다시 말해, **위험-이익 균형(risk-benefit trade-off)**이 필요하다. 예컨대, 개인 특성 데이터를 수집하는 것은 재식별(reidentification) 위험을 증가시킬 수 있지만, 동시에 편향과 차별의 위험을 줄이는 데 기여할 수 있다. 따라서 FUTURE-AI에서는 **위험 관리(risk management, traceability 권고사항 1에서 제안됨)**가 AI 도구의 수명 주기 전반에 걸쳐 지속적이고 투명한 과정이 되어야 함을 강조한다.
또한 FUTURE-AI는 가정(assumption)에 기반하지 않는, 고도로 협력적인(collaborative) 프레임워크로, 다학제적 이해관계자들과 지속적으로 소통할 것을 권장한다(일반 원칙 1). 이는 해당 AI 도구에 대한 신뢰를 떨어뜨릴 수 있는 모든 위험과 요소를 식별하기 위해 매우 중요하다.
예를 들어, 편향의 가능성 있는 원인에 대해 사전 가정을 두기보다는, FUTURE-AI는 개발자가 의료 전문가, 분야별 전문가, 시민 대표, 윤리학자 등과 초기 단계부터 협업하여 다학제적 AI 개발 팀을 구성하고, 특정 애플리케이션에 관련된 편향의 원인을 심층적으로 조사할 것을 권고한다. 이러한 원인은 예컨대 **유방암 AI 도구의 경우, 유방 밀도(breast density)**와 같은 **특정 도메인 특성(domain-specific attributes)**일 수 있다.
FUTURE-AI 지침은 다양한 분야에 적용 가능하도록 일반적인 방식으로 정의되었다. 예컨대, 방사선학(radiology), 유전체학(genomics), 모바일 헬스(mobile health), 전자의무기록(EHR) 등 여러 영역에서 활용될 수 있도록 설계되었다. 그러나 많은 권고사항들은 해당 도메인 내에서도 의료 활용 사례에 따라 적용 가능성이 달라진다.
이를 고려하여, 각 원칙의 첫 번째 권고사항은 해당 분야의 특수성을 식별하도록 구성되었다. 예를 들어, 편향의 유형(fairness 1), 임상 환경(universality 1), 설명 가능한 AI에 대한 필요성과 접근 방식(explainability 1) 등이 있다. 이러한 구성은 도메인 간 일반화 가능성을 높이는 동시에 **미래 사용을 위한 지속 가능성(sustainability)**을 보장한다.
또한, 우리는 하나의 접근법으로 모든 상황에 대응(one-size-fits-all approach)은 불가능하다는 점을 인식하고 있다. 많은 권고사항은 **활용 사례(use case)**에 따라 다르게 적용되어야 하며, 표준이 아직 존재하지 않거나 향후 변경될 가능성이 있기 때문이다. 따라서 본 지침은 각 권고사항의 구체적 기법을 강제하지 않고, 의료 AI의 신뢰성을 높이기 위한 최선의 실천방안(best practices) 개발에 중점을 두었다.
이러한 유연성은 다양한 도전과 위험을 해결하는 방법의 다양성을 반영한 것이다. 예를 들어, AI 학습 과정에서 개인정보 보호를 위한 권고사항은 데이터 비식별화(data deidentification), 연합 학습(federated learning), 차등 개인정보보호(differential privacy), 암호화(encryption) 등 다양한 방식으로 구현될 수 있다. 이러한 구체적인 예시는 특히 표 3, 표 4, 표 5, 표 6에 수록되어 있다.
그러나 각 권고사항을 실행하는 데 가장 적합한 기법은 해당 적용 도메인, 임상적 활용 사례, 데이터의 특성, 방법론의 장단점 등을 고려하여 AI 개발팀이 최종적으로 선택해야 한다. 이와 마찬가지로, AI 개발에 참여하는 모든 이해관계자들은 각 권고사항을 함께 책임지며, 그 역할은 적용 사례, 방법, 분야, 프로젝트 구성 및 활용 상황에 따라 달라질 수 있다.
FUTURE-AI 프레임워크는 의료 AI의 규제를 위한 통찰을 제공하지만, 이러한 권고사항들을 실제 규제 절차에 통합하기 위해서는 추가적인 작업이 필요하다. 예컨대, **추적성과 거버넌스를 향상시키기 위한 메커니즘으로 로깅(logging)**을 제안하였지만, 감사(audit)는 누가 수행하고, 오류 발생 시 누가 책임질 것인지에 대한 책임 문제(liability)는 아직 해결되지 않았다.
또한 우리는 AI 모델의 지속적인 평가와 조정(fine-tuning)을 권장하지만, 현행 규제는 제품 출시 이후의 수정(post-release modifications)을 금지하고 있다. 이는 제조사의 초기 검증(validity)을 형식적으로 무효화하기 때문이다. 향후 규제는 사전에 정의된 허용 기준 내에서의 현장 맞춤(local adaptations) 가능성을 고려해야 할 것이다.
한편, FUTURE-AI 지침의 실행은 상당한 비용이 수반될 수 있으며, 이는 AI 개발자와 보건의료 시스템 모두에 영향을 미칠 수 있다. 이러한 재정적 고려는 특히 소규모 개발자나 자원이 제한된 의료 시스템에서 AI 도입의 격차를 심화시킬 수 있다. 다양한 분야의 이해관계자들이 협력함으로써 이러한 재정적 부담을 분산시키고, 고급 AI 도구에 대한 형평성 있는 접근을 지원할 수 있다.
반대로, FUTURE-AI 지침을 조기에 채택하면 비용을 절감할 수도 있다. 임상적으로 부가가치가 없는 AI 도구를 개발하거나, 도구 개발 후에 여러 원칙을 해결하려는 노력을 하기보다, 초기 단계에서부터 신뢰할 수 있고 실제로 사용 가능한 AI 도구를 설계함으로써, 사후 도입보다 비용 효과적일 수 있다. 실제로 사후 도입은 도구의 **해결 구조(solution architecture)의 큰 부분을 변경해야 하는 고비용 요청(change requests)**이 자주 요구된다.
마지막으로, 의료 AI 도구의 발전과 채택이 진행됨에 따라 새로운 요구사항, 도전 과제, 기회가 생겨날 것이다. 일부 권고사항은 여전히 표준화된 해결 방안이 존재하지 않으며, 이에 따라 우리는 FUTURE-AI를 동적인 살아 있는(living) 프레임워크로 제안한다.
우리는 다양한 목소리로부터 배우고 지침을 다듬기 위해, **전용 웹사이트(www.future-ai.eu)**를 개설하였다. 이곳에서 FUTURE-AI 네트워크에 참여하고, 자신의 경험과 관점에 기반한 피드백을 제공할 수 있도록 초대하고 있다. 웹사이트에는 **FUTURE-AI 자기 점검 체크리스트(self-assessment checklist)**도 포함되어 있으며, 이는 FUTURE-AI 권고사항의 활용을 쉽게 하고 예시를 제시하기 위한 질문과 사례로 구성되어 있다.
추가적으로 우리는 **의료 AI 연구자, 제조사, 평가자, 최종 사용자, 규제기관과의 교류를 위한 정기적인 웹 세미나 및 워크숍 등 외부 소통 행사(outreach events)**를 개최할 계획이다. 향후 연구에서는 FUTURE-AI의 실행을 특정 의료 분야에서 심층적으로 분석하고, 각 원칙의 도메인 특화 적용 방법을 탐색할 예정이다. 예를 들어, **공정한 머신러닝(Fair ML), 설명 가능한 AI(XAI)**와 같은 분야는 이미 독립적인 빠르게 진화하는 분야로 자리잡고 있다.

‘+’는 권장(recommended), ‘++’는 **강력히 권장(highly recommended)**을 의미합니다.
🟡 Fairness (공정성)
- 가능한 편향의 원인을 초기부터 식별할 것 – 연구 및 실제 적용 모두에서 강력히 권장됨(++).
- 개인 및 데이터 속성에 관한 정보를 수집할 것 – 연구 및 실제 적용 모두에서 강력히 권장(++).
- 편향을 평가하고, 필요한 경우 교정 조치를 시행할 것 – 연구에서는 권장(+), 실제 적용에서는 강력히 권장(++).
🟢 Universality (보편성)
- 의도된 임상 환경과 다양한 세팅 차이를 정의할 것 – 연구 및 실제 적용 모두에서 강력히 권장(++).
- 공통적으로 정의된 기준(임상 정의, 기술 표준 등)을 사용할 것 – 연구 및 실제 적용 모두에서 권장(+).
- 외부 데이터셋 및/또는 다기관 데이터를 사용하여 평가할 것 – 연구 및 실제 적용 모두에서 강력히 권장(++).
- 현장(local) 임상 유효성을 입증하고 시연할 것 – 연구 및 실제 적용 모두에서 강력히 권장(++).
🔵 Traceability (추적 가능성)
- AI 생애 주기 전반에 걸친 위험 관리 프로세스를 구현할 것 – 연구에서는 권장(+), 실제 적용에서는 강력히 권장(++).
- 기술적·임상적 문서화(documentation)를 제공할 것 – 연구 및 실제 적용 모두에서 강력히 권장(++).
- 입력 및 출력의 품질 관리를 위한 메커니즘을 정의할 것 – 연구에서는 권장(+), 실제 적용에서는 강력히 권장(++).
- 주기적인 감사를 위한 시스템을 구현할 것 – 연구에서는 권장(+), 실제 적용에서는 강력히 권장(++).
- 사용 이력을 기록할 수 있는 로깅 시스템을 구현할 것 – 연구에서는 권장(+), 실제 적용에서는 강력히 권장(++).
- AI 거버넌스를 위한 메커니즘을 수립할 것 – 연구에서는 권장(+), 실제 적용에서는 강력히 권장(++).
🟠 Usability (사용 가능성)
- 최종 사용자 요구사항을 초기 단계부터 정의할 것 – 연구 및 실제 적용 모두에서 강력히 권장(++).
- 인간-AI 상호작용 및 감독을 위한 메커니즘을 수립할 것 – 연구 및 실제 적용 모두에서 강력히 권장(++).
- 교육 자료 및 실습 기반 활동(예: 튜토리얼, 핸즈온 세션)을 제공할 것 – 연구 및 실제 적용 모두에서 권장(+).
- 독립적인 최종 사용자에게 수용성 및 경험을 평가받을 것 – 연구에서는 권장(+), 실제 적용에서는 강력히 권장(++).
- 임상적 유용성과 안전성(예: 효과성, 위해성, 비용-편익)을 평가할 것 – 연구에서는 권장(+), 실제 적용에서는 강력히 권장(++).
🟣 Robustness (강건성)
- 초기 단계에서 데이터의 다양성 원인을 정의할 것 – 연구 및 실제 적용 모두에서 강력히 권장(++).
- 대표성을 갖춘 실제 데이터를 사용하여 학습할 것 – 연구 및 실제 적용 모두에서 강력히 권장(++).
- 현실 세계의 다양한 환경에 대한 견고성을 평가하고 최적화할 것 – 연구 및 실제 적용 모두에서 강력히 권장(++).
⚪ Explainability (설명 가능성)
- 설명 가능성에 대한 필요성과 요구사항을 정의할 것 – 연구 및 실제 적용 모두에서 권장(+).
- 최종 사용자와 함께 설명 가능성의 정확성, 적합성, 영향 등을 평가할 것 – 연구에서는 권장(+), 실제 적용에서는 강력히 권장(++).
⚫ General (일반 원칙)
- AI 생애 주기 전반에서 다학제 이해관계자들과 협력할 것 – 연구 및 실제 적용 모두에서 강력히 권장(++).
- 개인정보 보호 및 보안을 위한 조치를 구현할 것 – 연구 및 실제 적용 모두에서 강력히 권장(++).
- 식별된 AI 위험에 대해 대응할 수 있는 조치를 구현할 것 – 연구에서는 권장(+), 실제 적용에서는 강력히 권장(++).
- 적절한 평가 계획(예: 데이터셋, 메트릭, 기준 방법 등)을 정의할 것 – 연구 및 실제 적용 모두에서 강력히 권장(++).
- 적용 가능한 모든 규제 요건을 식별하고 준수할 것 – 연구에서는 권장(+), 실제 적용에서는 강력히 권장(++).
- 애플리케이션 특유의 임상 이슈를 조사하고 대응할 것 – 연구에서는 권장(+), 실제 적용에서는 강력히 권장(++).
- 사회적, 환경적 이슈를 조사하고 대응할 것 – 연구 및 실제 적용 모두에서 권장(+).
표의 내용을 자연스럽게 정리한 위 서술은 FUTURE-AI 프레임워크의 각 권고사항이 어느 정도 수준으로 연구 및 실제 활용에서 요구되는지를 직관적으로 보여줍니다. 필요하시면 이 내용을 기반으로 한 시각적 요약(예: 인포그래픽)도 제작해드릴 수 있습니다.
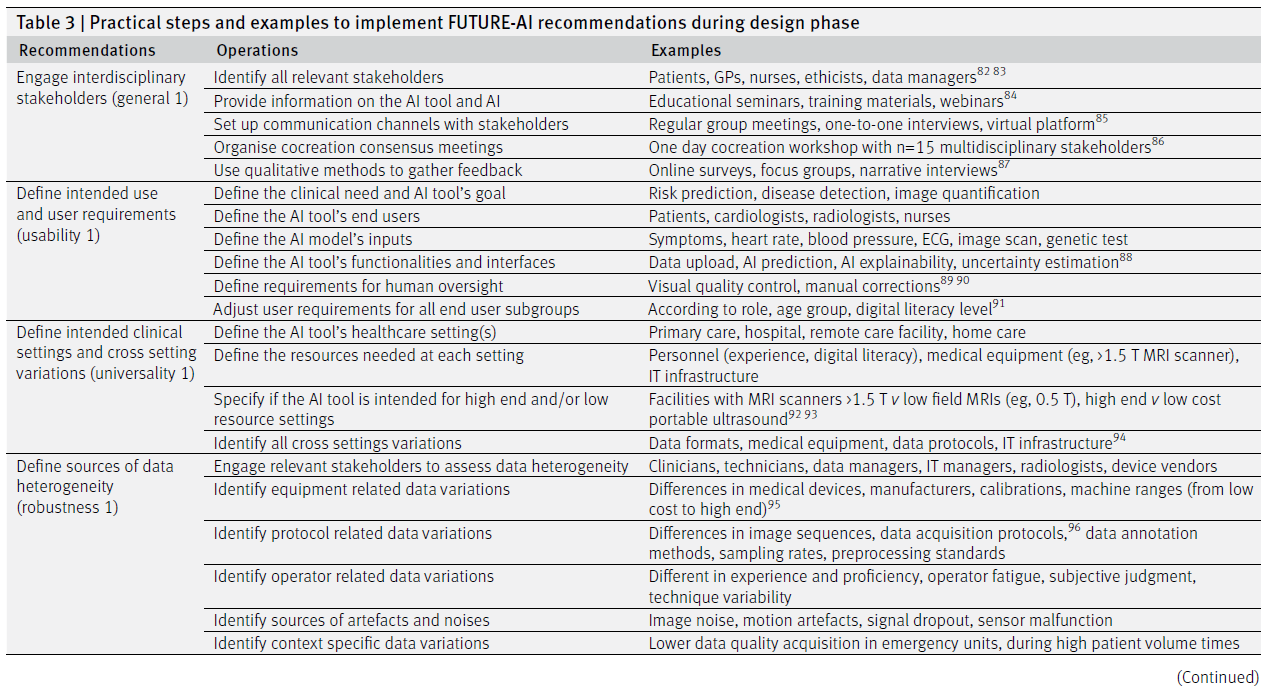
✅ 1. 다학제 이해관계자 참여 (Engage interdisciplinary stakeholders – general 1)
- 운영 방안:
- 모든 관련 이해관계자 식별
- AI 도구 및 AI 자체에 대한 정보 제공
- 이해관계자와의 소통 채널 설정
- 공동창작(Co-creation) 합의 회의 구성
- 정성적 방법을 활용한 피드백 수집
- 예시:
- 환자, 일반의(GP), 간호사, 윤리학자, 데이터 관리자
- 교육 세미나, 교육 자료, 웨비나
- 정기적인 그룹 미팅, 일대일 인터뷰, 온라인 플랫폼
- 다학제 이해관계자 15명과의 공동 창작 워크숍
- 온라인 설문조사, 포커스 그룹, 내러티브 인터뷰
✅ 2. 의도된 사용 목적과 사용자 요구사항 정의 (Define intended use and user requirements – usability 1)
- 운영 방안:
- 임상적 필요와 AI 도구의 목표 정의
- AI 도구의 최종 사용자 정의
- AI 모델의 입력 요소 정의
- AI 도구의 기능 및 인터페이스 정의
- 사람 중심 감독 요건 정의
- 모든 사용자 하위 집단별로 요구사항 조정
- 예시:
- 위험 예측, 질병 탐지, 영상 정량화
- 환자, 심장 전문의, 영상의학과 전문의, 간호사
- 증상, 심박수, 혈압, 심전도(ECG), 영상 스캔, 유전자 검사
- 데이터 업로드, AI 예측, AI 설명 가능성, 불확실성 추정
- 시각적 품질 관리, 수동 교정
- 역할, 연령, 디지털 리터러시 수준에 따라 조정
✅ 3. 임상 환경 및 환경 간 변이 정의 (Define intended clinical settings and cross-setting variations – universality 1)
- 운영 방안:
- AI 도구가 적용될 의료 환경 정의
- 각 환경에서 필요한 자원 정의
- 고사양/저사양 환경을 구분하여 AI 도구 적용 여부 명시
- 모든 환경 간 변이 사항 식별
- 예시:
- 1차 진료(primary care), 병원, 원격 진료, 가정 내 진료
- 인력(경험, 디지털 리터러시), 의료 장비(예: 1.5 T MRI), IT 인프라
- 고자장 MRI(>1.5T) vs 저자장 MRI(예: 0.5T), 고사양 vs 저비용 휴대형 초음파
- 데이터 형식, 의료 장비, 데이터 프로토콜, IT 인프라
✅ 4. 데이터 이질성의 원인 정의 (Define sources of data heterogeneity – robustness 1)
- 운영 방안:
- 관련 이해관계자들과 함께 데이터 이질성 평가
- 장비 관련 데이터 변이 식별
- 프로토콜 관련 데이터 변이 식별
- 작업자 관련 데이터 변이 식별
- 아티팩트 및 노이즈의 원인 식별
- 맥락별 데이터 변이 식별
- 예시:
- 임상의, 기술자, 데이터 관리자, IT 관리자, 영상의학과 전문의, 장비 업체
- 의료기기 종류, 제조사, 교정 방식, 기기 성능 범위(저사양~고사양)
- 영상 시퀀스, 데이터 취득 프로토콜, 데이터 주석 방법, 샘플링 속도, 전처리 기준
- 작업자의 숙련도 차이, 피로도, 주관적 판단, 기술적 편차
- 영상 노이즈, 모션 아티팩트, 신호 손실, 센서 오작동
- 응급실, 환자 대기량이 많은 시간대에서의 데이터 품질 저하
📝 (다음 페이지로 이어집니다 – Continued)
해당 표의 이어지는 다음 부분도 있으시면 보내주시면 계속해서 번역해드리겠습니다.

✅ 5. 잠재적 편향 요인 정의 (Define any potential sources of bias – fairness 1)
- 운영 방안:
- 관련 이해관계자들과 함께 편향의 원인을 정의
- AI의 공정성에 영향을 줄 수 있는 표준 속성 정의
- 표준 속성 외에도 애플리케이션 특이적 편향 요인 식별
- 가능한 모든 인간 편향 요인 식별
- 예시:
- 환자, 임상의, 역학자, 윤리학자, 사회복지사 등과 협력
- 성별, 연령, 사회경제적 지위
- 피부암 감지를 위한 피부 색, 유방암 진단에서의 유방 밀도
- 데이터 라벨링, 데이터 큐레이션 과정에서의 인간 편향
✅ 6. 최종 사용자를 위한 설명가능성 요건 정의 (Define the need and requirements for explainability with end users – explainability 1)
- 운영 방안:
- 최종 사용자와 함께 설명가능성의 필요 여부 평가
- 설명가능성이 필요한 경우, 그 목적 명확히 설정
- 적절한 설명방법(approach)을 정의
- 사용자 하위집단별로 설명 방식 설계 조정
- 예시:
- 임상의, 기술자, 환자와 협력
- 이미지 분할 AI에는 설명 필요 없음, 진단 지원 AI에는 설명 필수
- AI 모델 이해, 진단 추론 지원, 치료 결정 정당화
- 시각적 설명, 중요 특징 시각화(feature importance), 반사실(counterfactuals)
- 임상의용 히트맵, 사용자별 맞춤 설명
✅ 7. 윤리적 이슈 탐색 (Investigate ethical issues – general 6)
- 운영 방안:
- 의료 AI 윤리 전문가와의 협의
- AI 도구의 설계가 관련 윤리적 가치와 부합하는지 평가
- 애플리케이션 특이적 윤리 문제 식별
- 지역 윤리 규범 준수
- 예시:
- 의료 AI, 소아과 등 분야별 윤리 전문가
- 자율성, 정보 접근권, 동의, 비밀 보장, 형평성 등의 가치 고려
- 소아용 AI 도구의 정서적 영향 등
- 유럽, 영국, 미국, 캐나다, 중국, 인도, 일본, 호주 등의 윤리 지침
✅ 8. 사회적·환경적 이슈 탐색 (Investigate social and environmental issues – general 7)
- 운영 방안:
- AI 도구가 유발할 수 있는 사회적·환경적 영향 조사
- 사회·환경적 영향을 줄이기 위한 완화 전략 정의
- 알고리즘 및 에너지 효율 최적화
- 책임 있는 데이터 사용 촉진
- AI 도구의 환경적 영향을 모니터링 및 보고
- 예시:
- 노동력 축소, 근로환경 악화, 탈숙련화, 돌봄의 탈인간화, 건강 문해력 저하, 탄소 발자국 증가, 부정적 사회 인식
- 의사-환자 소통 인터페이스 개선, 교육 프로그램 개발, 에너지 효율적 컴퓨팅, 공공 참여 유도
- 전력 소비를 줄이는 에너지 효율 알고리즘, 가지치기, 양자화, 에지 컴퓨팅
- 필요한 데이터만 수집·처리, 지역 기반 학습 기술로 대규모 데이터 이동 방지
- 에너지 사용량, 탄소 배출량, 폐기물 발생 등을 포함한 환경 영향 정기 보고

✅ 9. 공동체에서 정의한 기준을 사용할 것 (Use community defined standards – universality 2)
- 운영 방안 및 예시:
- 임상 과제에 대한 표준 정의 사용: 예) 미국심장학회(American Academy of Cardiology)의 심부전(Heart Failure) 정의¹²¹
- 데이터 라벨링을 위한 표준 방법 사용: 예) 유방 영상에 사용되는 BI-RADS 기준¹²²
- AI 입력을 위한 표준 온톨로지 사용: 예) 영상 데이터에는 DICOM, 임상 데이터에는 SNOMED¹²³⁴¹
- 기술적 표준 채택: 예) 의료 AI 소프트웨어를 위한 IEEE 2801-2022 표준¹⁴³
- 표준화된 평가 기준 사용: 예) Maier-Hein et al.¹²¹의 영상 AI 평가, Barocas et al.³¹ 및 Bellamy et al.³⁵의 공정성 평가 기준
✅ 10. 위험 관리 프로세스를 구현할 것 (Implement a risk management process – traceability 1)
- 운영 방안 및 예시:
- 임상적, 기술적, 윤리적, 사회적 모든 위험 요인 식별
- 예: 소수집단에 대한 편향, 자원이 부족한 환경에서의 일반화 어려움, 데이터 드리프트(data drift), 최종 사용자의 수용 부족, 노이즈에 민감한 입력
- 운영상의 모든 위험 요인 식별
- 예: 사용자 교육 부족 혹은 지침 미준수로 인한 AI 오용, 대상 외 인구(예: 임플란트 보유자) 적용, 예상 외 사용자 사용(예: 의사가 아닌 기술자), 하드웨어 오류, 잘못된 주석, 적대적 공격(adversarial attacks)¹²⁵
- 각 위험의 발생 가능성 평가
- 예: 매우 높음, 높음, 가능성 있음, 드묾
- 각 위험의 결과(심각도) 평가
- 예: 환자 위해, 차별, 투명성 부족, 자율성 침해, 환자 재식별 위험¹²⁶
- 가능성과 심각도를 기반으로 위험 우선순위 지정
- 예: 모델에 개인 속성이 포함되지 않으면 편향 위험, 포함되면 재식별 위험
- AI 개발 중 적용할 위험 완화 조치 정의
- 예: 데이터 증강(data augmentation), 편향 수정 기술, 도메인 적응(domain adaptation)⁶⁶, 전이 학습(transfer learning)¹²⁸, 지속 학습(continuous learning)¹²⁹
- AI 배포 이후 적용할 위험 완화 조치 정의
- 예: 사용자 경고, 시스템 종료, 입력 데이터 재처리, 새로운 입력 데이터 수집, 대체 절차 사용, 인간 판단만 허용
- 위험 모니터링 및 장기 관리 메커니즘 구축
- 예: 6개월마다 정기적인 위험 평가 시행
- 종합적인 위험 관리 문서 작성
- 예: 모든 위험, 발생 가능성, 결과, 완화 조치, 모니터링 전략 포함
- 임상적, 기술적, 윤리적, 사회적 모든 위험 요인 식별
용어 참고:
- AI: 인공지능 (Artificial Intelligence)
- BI-RADS: 유방 영상 보고 및 데이터 시스템
- DICOM: 디지털 영상 및 의료 통신
- SNOMED: 임상 용어 시스템화 명명법
- IEEE: 미국 전기전자기술자협회
- MRI: 자기공명영상
- ECG: 심전도
- GP: 일반의(General Practitioner)

✅ 1. 대표성 있는 학습 데이터셋 수집 (Collect representative training dataset – robustness 2)
- 운영 방안:
- 인구통계적 변이를 반영하는 학습 데이터 수집
- 임상적 변이를 반영하는 학습 데이터 수집
- 실제 임상 환경의 변이를 반영하는 학습 데이터 수집
- 현실 환경 조건을 모방한 학습 데이터 인위적 강화
- 예시:
- 연령, 성별, 인종, 사회경제적 배경 등
- 질병 하위군, 치료 프로토콜, 임상 결과, 희귀 사례 등
- 데이터 획득 프로토콜, 주석 기준, 의료 장비, 스캐닝 중 환자 움직임 등
- 데이터 증강(data augmentation), 데이터 합성(data synthesis, 예: 저품질 데이터, 노이즈 추가), 데이터 조화(harmonisation, homogenisation)
✅ 2. 개인 및 데이터 속성에 대한 정보 수집 (Collect information on individuals’ and data attributes – fairness 2)
- 운영 방안:
- 개인 속성 데이터 수집을 위한 승인 요청
- 가능하다면 표준 속성(예: 성별, 연령, 민족, 교육 수준) 수집
- 공정성 분석을 위한 애플리케이션 특이적 정보 포함
- 하위집단 간 데이터 분포 추정
- 데이터의 출처 및 특성에 대한 정보 수집
- 예시:
- 성별, 연령, 민족, 사회경제적 지위
- 피부색, 유방 밀도, 임플란트 유무, 동반 질환
- 남성 대 여성, 인종 간 데이터 분포 비교
- 데이터센터 위치, 장비 특성, 전처리 및 주석 과정 정보
✅ 3. 데이터 프라이버시 및 보안 조치 시행 (Implement measures for data privacy and security – general 2)
- 운영 방안:
- 데이터 프라이버시와 보안을 위한 조치 적용
- 악의적 공격에 대한 방지 대책 시행
- 관련 법규 및 데이터 보호 규정 준수
- 적절한 데이터 거버넌스 메커니즘 수립
- 예시:
- 데이터 비식별화(de-identification), 연합 학습(federated learning), 차등 개인정보 보호(differential privacy), 암호화(encryption)
- 방화벽(firewalls), 침입 탐지 시스템(IDS), 정기 보안 감사
- GDPR(일반 개인정보 보호법), HIPAA(건강보험 이동성 및 책임법)
- 접근 제어, 로깅 시스템 등
✅ 4. 식별된 AI 위험에 대한 대응 조치 실행 (Implement measures against identified AI risks – general 3)
- 운영 방안:
- 기준선 AI 모델 구현 및 한계 파악
- 현실 세계의 변이에 대한 강건성 향상 기법 적용
- 환경 간 일반화 가능성 향상을 위한 기법 적용
- 하위 집단 간 공정성 향상을 위한 기법 적용
- 예시:
- 편향, 일반화 부족 등의 한계
- 정규화(regularisation), 데이터 증강(data augmentation), 데이터 조화(harmonisation), 도메인 적응(domain adaptation)
- 지식 증류(knowledge distillation), 전이 학습(transfer learning)
- 데이터 리샘플링(resampling), 편향 없는 표현, 공정성 기반 후처리(equalised odds postprocessing)
✅ 5. 인간-AI 상호작용 메커니즘 구축 (Establish mechanisms for human-AI interactions – usability 2)
- 운영 방안:
- 데이터 전처리 및 라벨링 표준화 메커니즘 구축
- AI 모델 사용을 위한 인터페이스 구현
- 설명 가능한 AI를 위한 인터페이스 구현
- AI 결과의 품질 관리를 위한 사용자 중심 메커니즘 구현
- 사용자 피드백 수집을 위한 메커니즘 구현
- 예시:
- 데이터 전처리 파이프라인, 라벨링 플러그인
- API(Application Programming Interface)
- 시각적 설명, 히트맵, 중요도 막대
- 시각 품질 통제, 불확실성 추정
- 피드백 인터페이스
용어 참고:
- AI: 인공지능
- Federated learning: 중앙 서버에 데이터 없이 분산 학습 수행
- Differential privacy: 개별 정보 보호 보장하는 수학적 기술
- Regularisation, Domain adaptation: 과적합 방지 및 도메인 간 일반화 기법
- Knowledge distillation: 큰 모델의 지식을 작은 모델로 전이하는 기법

✅ 1. 적절한 평가 계획 수립 (Define adequate evaluation plan – general 4)
- 운영 방안:
- 신뢰할 수 있는 AI의 평가 요소를 정의
- 적절한 테스트 데이터셋 선정
- 기존의 진료 기준(Standard of care)과 비교
- 적절한 평가 지표 선택
- 예시:
- 강건성, 임상적 안전성, 공정성, 데이터 드리프트, 사용성, 설명가능성
- 새 병원의 외부 데이터셋, 공개 벤치마킹 데이터셋
- 기존 위험 예측 모델, 영상의학 전문의의 시각 평가, 임상의의 의사결정
- 분류 정확도(F1 score), 생존 분석 concordance index, 공정성 평가를 위한 statistical parity
✅ 2. 외부 데이터셋 및 다기관 평가 사용 (Evaluate using external datasets and/or multiple sites – universality 3)
- 운영 방안:
- 관련 공개 데이터셋 식별
- 외부의 비공개(proprietary) 데이터셋 식별
- 다기관 평가 장소 선정
- 평가 데이터와 장소가 실제 변이를 반영하는지 확인
- 훈련 데이터로 사용되지 않았는지 검증
- 예시:
- Cancer Imaging Archive, UK Biobank, M&Ms, MAMA-MIA, BRATS
- 동일 기관 또는 다른 병원에서 수집된 신규 전향적 데이터
- 동일 국가 내 3개 기관, 다른 국가 내 5개 기관
- 인구 통계, 임상의, 장비의 다양성 반영
- 훈련에 사용 여부: 예/아니오
✅ 3. 공정성 및 편향 수정 조치 평가 (Evaluate fairness and bias correction measures – fairness 3)
- 운영 방안:
- 공정성 평가를 위한 속성과 요인 선택
- 공정성 지표 및 기준 정의
- 공정성 평가 및 편향 식별
- 편향 수정 조치 평가
- 수정 조치가 모델 성능에 미치는 영향 평가
- 식별된 편향 및 수정되지 않은 편향 보고
- 예시:
- 성별, 연령, 피부색, 동반 질환
- 예: 통계적 균형(parity) 차이가 -0.1~0.1 사이일 경우 공정하다고 판단
- 연령에 대해 공정, 성별에 대해서는 편향
- 데이터 리샘플링, 편향 없는 후처리(equalised odds postprocessing)
- 예: 리샘플링 후 성별 편향은 줄었지만 모델 성능은 감소
- 정보전달지 및 기술 문서에 편향 명시
✅ 4. 사용자 경험 평가 (Evaluate user experience – usability 4)
- 운영 방안:
- 다양한 최종 사용자의 사용성 평가
- 사용성 설문조사를 통한 만족도 평가
- 사용자 성능 및 생산성 평가
- 신규 사용자의 학습 난이도 및 교육 요구 평가
- 예시:
- 성별, 연령, 디지털 숙련도, 역할, 임상 프로필 기반으로 분류된 사용자
- System Usability Scale(SUS) 활용
- AI 도구 사용 전후 진단 소요 시간, 영상 분량 계량화 등
- 숙련까지 걸리는 평균 시간, 훈련 과정에서의 어려움
✅ 5. 임상적 유용성과 안전성 평가 (Evaluate clinical utility and safety – usability 5)
- 운영 방안:
- 임상적 평가 계획 수립
- AI 도구가 환자 결과 향상에 기여하는지 평가
- 생산성 향상 또는 진료 질 향상 여부 평가
- 비용 절감 효과 확인
- AI 도구의 안전성 평가
- 예시:
- 무작위 대조군 시험(RCT), 시뮬레이션(in silico) 연구
- 위험 예측 향상, 조기 진단, 개인맞춤 치료
- 진료 속도 향상, 대기 시간 단축, 빠른 진단, 환자 섭취 증가
- 진단 비용 절감, 과잉 치료 감소
- 부작용 또는 중대한 이상반응 여부 (RCT 기반)
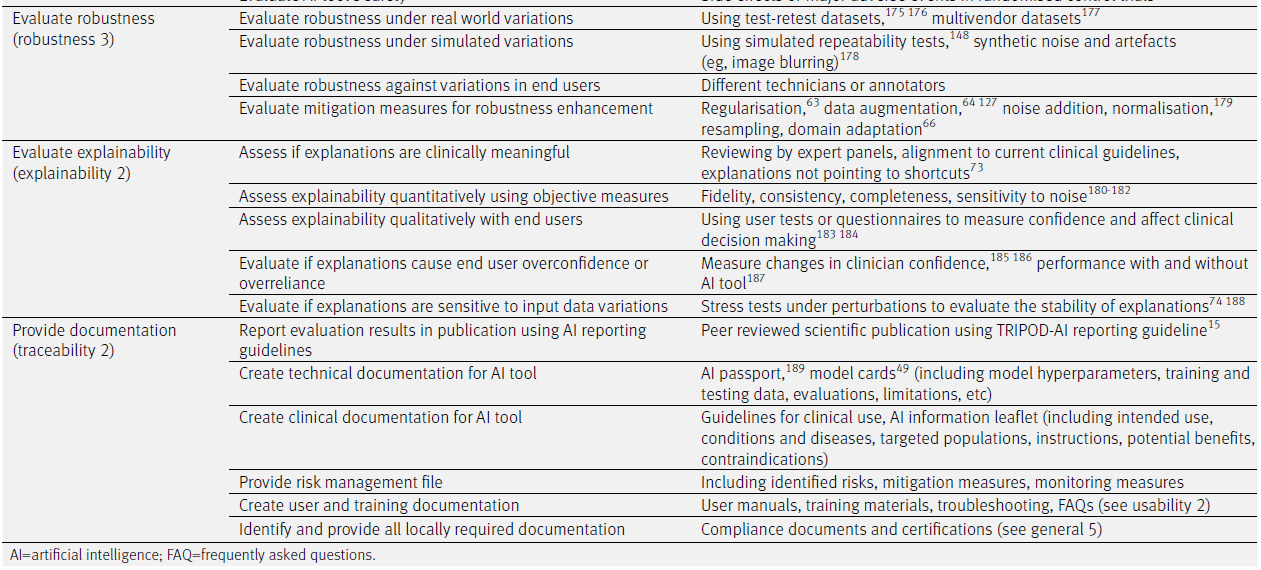
✅ 6. 강건성 평가 (Evaluate robustness – robustness 3)
- 운영 방안:
- 실제 세계의 다양한 변이 상황에서 강건성 평가
- 시뮬레이션된 변이 상황에서 강건성 평가
- 최종 사용자 간의 변이에 따른 강건성 평가
- 강건성 향상을 위한 완화 조치 평가
- 예시:
- 테스트-재테스트 데이터셋, 다기관(multivendor) 데이터셋 사용
- 반복 가능성 테스트, 합성 노이즈 또는 아티팩트(예: 영상 흐림) 삽입
- 서로 다른 기술자 혹은 주석자 비교
- 정규화, 데이터 증강, 노이즈 추가, 리샘플링, 도메인 적응 등
✅ 7. 설명가능성 평가 (Evaluate explainability – explainability 2)
- 운영 방안:
- 설명이 임상적으로 의미 있는지 평가
- 설명가능성을 객관적인 지표로 정량 평가
- 설명가능성을 최종 사용자와 함께 정성 평가
- 설명이 최종 사용자의 과신(overconfidence)이나 과잉 의존을 유발하는지 평가
- 설명이 입력 데이터의 변이에 민감한지 평가
- 예시:
- 전문가 패널의 리뷰, 임상 가이드라인과의 정렬, 지름길(shortcuts)을 지적하지 않는 설명
- 신뢰도(fidelity), 일관성(consistency), 완전성(completeness), 노이즈 민감도 측정
- 사용자 테스트나 설문을 통한 신뢰도 및 임상 의사결정에의 영향 평가
- 임상의의 신뢰도 변화, AI 유무에 따른 성과 변화 측정
- 스트레스 테스트를 통한 설명의 안정성 평가
✅ 8. 문서화 제공 (Provide documentation – traceability 2)
- 운영 방안:
- AI 평가 결과를 보고서나 학술지에 출판
- AI 도구에 대한 기술 문서 작성
- AI 도구에 대한 임상 문서 작성
- 위험 관리 파일 제공
- 사용자 및 교육 문서 생성
- 지역별 요구 문서 식별 및 제공
- 예시:
- TRIPOD-AI 보고 가이드를 사용한 동료 심사 논문
- AI 여권(AI passport), 모델 카드(model cards): 하이퍼파라미터, 학습/테스트 데이터, 평가 결과, 한계 등 포함
- 임상 사용 지침서, AI 정보 리플릿: 사용 목적, 대상 질환 및 인구, 작동 원리, 이점 및 금기사항 등
- 식별된 위험, 완화 조치, 모니터링 전략 포함한 파일
- 사용자 매뉴얼, 교육 자료, FAQ, 트러블슈팅 가이드
- 법적 요구사항에 따른 인증 문서 및 규정 준수 서류
📌 참고 용어:
- Fidelity: AI 설명이 실제 모델의 작동과 일치하는 정도
- Stress Test: 시스템의 한계를 평가하기 위한 인위적 교란
- Model Cards: AI 모델에 대한 투명한 설명 문서
- TRIPOD-AI: AI 모델 보고를 위한 표준화된 지침

✅ 1. 현장 임상 유효성 평가 및 입증 (Evaluate and demonstrate local clinical validity – universality 4)
- 운영 방안:
- 지역 데이터를 활용하여 AI 모델 테스트
- AI 도구의 지역 유효성에 영향을 줄 수 있는 요인 파악
- AI 도구가 병원 IT 시스템이나 임상 워크플로우와 잘 통합되는지 평가
- AI 도구의 실제 활용 가능성과 운영상 문제 파악
- 지역 유효성을 위한 조정 조치 시행
- AI 도구의 성능을 현지 임상의와 비교
- 예시:
- 지역 임상 등록 데이터 사용
- 지역 기술자, 장비, 임상 워크플로우, 데이터 수집 프로토콜
- AI 도구의 인터페이스가 병원 IT 시스템과 호환되는지, 기존 진료 흐름을 방해하는지 여부
- 사용 시간, 임상의 만족도, 기존 진료 절차와의 충돌 여부
- 모델 보정(model calibration), 파인튜닝(fine-tuning), 전이학습(transfer learning)
- 병렬 비교(side-by-side comparison), 인 실리코(in silico) 시험
✅ 2. AI 입력 및 출력의 품질 관리 메커니즘 정의 (Define mechanisms for quality control of AI inputs and outputs – traceability 3)
- 운영 방안:
- 오류 입력 데이터 탐지 메커니즘 구현
- 비현실적인 AI 출력 탐지 메커니즘 구현
- AI 도구의 신뢰도 판단을 위한 불확실성 추정값 제공
- 지속적인 품질 모니터링 시스템 구축
- 사용자가 문제를 보고할 수 있는 피드백 메커니즘 구축
- 예시:
- 결측값 또는 out-of-distribution 탐지기, 자동화된 영상 품질 평가
- 후처리 정합성 점검, 이상 탐지 알고리즘
- 각 환자 또는 데이터 포인트별로 보정된 불확실성 추정 제공
- 실시간 대시보드를 통한 데이터 품질 및 성능 지표 추적
- 임상의가 오류나 이상을 보고할 수 있는 피드백 포털
✅ 3. 정기 감사 및 업데이트 시스템 구현 (Implement system for periodic auditing and updating – traceability 4)
- 운영 방안:
- 정기 감사 일정 정의
- 감사 기준 및 지표 정의
- 감사용 데이터셋 정의
- 데이터 또는 개념 변화 탐지를 위한 메커니즘 구현
- AI 도구의 감사 책임자 지정
- 감사 결과를 기반으로 AI 도구 업데이트
- 감사 및 업데이트 이후 결과 공유 시스템 구현
- AI 업데이트의 영향 모니터링
- 예시:
- 반기 또는 연 1회 감사
- 정확성, 일관성, 공정성, 데이터 보안
- 새로 수집한 지역 병원 데이터셋
- 입력 데이터 분포의 변화 탐지
- 내부 감사팀 또는 외부 감사 전문기관
- AI 모델 재학습, 프로토콜 조정, 지속 학습
- 의료 관리자 및 임상의와의 자동 보고 공유
- 시스템 성능 및 사용자 만족도에 대한 영향 평가
📌 용어 설명
- In silico trial: 컴퓨터 시뮬레이션 기반의 시험
- Postprocessing sanity check: 결과의 논리적 타당성 확인 절차
- Out-of-distribution detector: 훈련 범위를 벗어난 입력을 탐지하는 알고리즘
- Calibrated uncertainty: 보정된 신뢰 수준 추정값
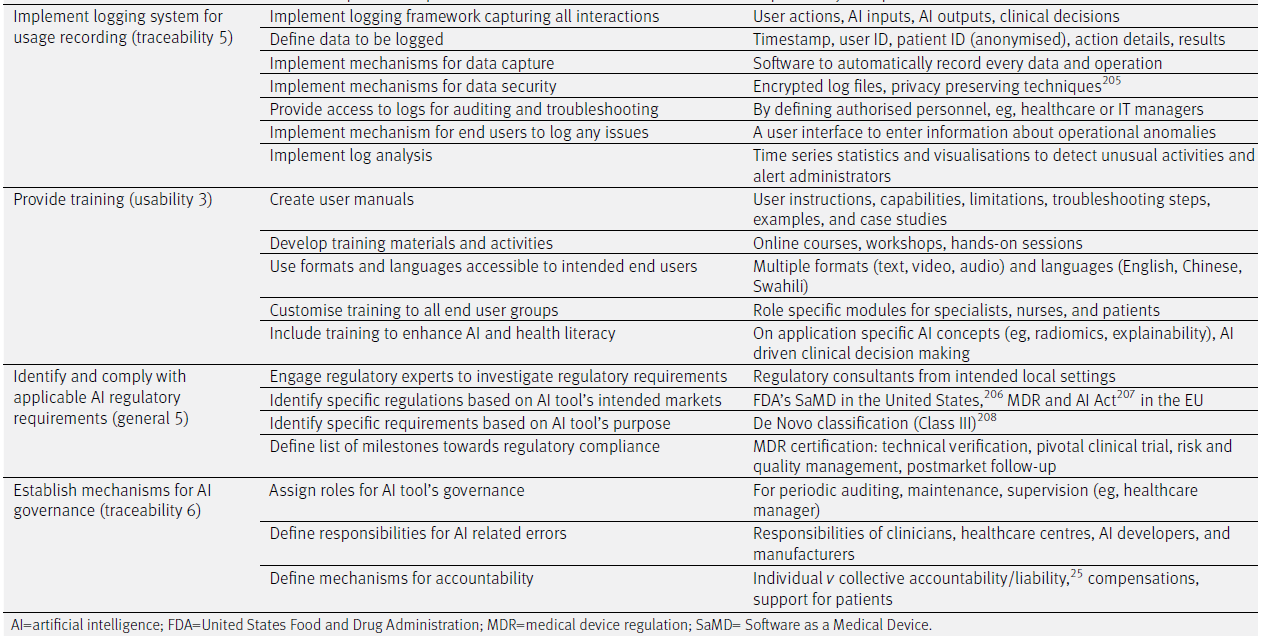
✅ 4. 사용 기록 로깅 시스템 구현 (Implement logging system for usage recording – traceability 5)
- 운영 방안:
- 모든 상호작용을 기록하는 로깅 프레임워크 구현
- 기록할 데이터 정의
- 데이터 캡처를 위한 자동화 메커니즘 구현
- 데이터 보안을 위한 메커니즘 구현
- 감사 및 문제 해결을 위한 로그 접근 권한 제공
- 사용자가 문제를 기록할 수 있는 인터페이스 구현
- 로그 분석을 위한 메커니즘 구현
- 예시:
- 사용자 행동, AI 입력, AI 출력, 임상 결정 등
- 타임스탬프, 사용자 ID, 환자 ID(익명화), 작업 상세 내역, 결과
- 모든 입력과 출력을 자동 기록하는 소프트웨어
- 암호화된 로그 파일, 프라이버시 보호 기술
- 지정된 관리자만 로그에 접근 가능 (예: 의료 관리자, IT 관리자)
- 운영상 이상 사항 입력을 위한 사용자 인터페이스 제공
- 이상 탐지 및 관리자 알림을 위한 시계열 통계 및 시각화
✅ 5. 사용자 교육 제공 (Provide training – usability 3)
- 운영 방안:
- 사용자 매뉴얼 작성
- 교육 자료 및 활동 개발
- 사용자 친화적인 형식과 언어 사용
- 사용자 그룹별 맞춤형 교육 제공
- AI 및 건강 문해력 향상을 위한 교육 포함
- 예시:
- 사용 지침서, 기능 설명, 제한 사항, 예시, 사례 기반 가이드
- 온라인 강의, 워크숍, 실습 세션
- 텍스트, 영상, 오디오 등 다양한 형식과 영어·중국어·스와힐리 등 다양한 언어
- 역할별 맞춤 모듈 (예: 전문의, 간호사, 환자용)
- AI 개념(예: 라디오믹스, 설명가능성) 및 임상 의사결정 관련 교육
✅ 6. 관련 규제 요건 확인 및 준수 (Identify and comply with applicable AI regulatory requirements – general 5)
- 운영 방안:
- 규제 전문가와 협력하여 요건 조사
- AI 시장별 구체적 규제 식별
- AI 목적별 구체적 요구사항 식별
- 규제 준수를 위한 이정표 정의
- 예시:
- 지역 특화 규제 컨설턴트
- 미국: FDA의 SaMD(Software as a Medical Device), 유럽: MDR 및 AI 법안
- AI 도구가 해당하는 De Novo 분류(예: Class III 등)
- MDR 인증: 기술 검증, 임상시험, 위험/품질 관리, 사후 추적(follow-up)
✅ 7. AI 거버넌스 메커니즘 수립 (Establish mechanisms for AI governance – traceability 6)
- 운영 방안:
- AI 도구 거버넌스를 위한 역할 지정
- 오류 발생 시 책임 소재 정의
- 책임성(accountability) 메커니즘 정의
- 예시:
- 정기 감사, 유지보수, 감독을 위한 역할 지정 (예: 헬스케어 관리자)
- 임상의, 의료기관, AI 개발자 및 제조사의 책임 분배
- 개인 vs 집단 책임, 보상 시스템, 환자 지원 제도
📌 주요 용어 정리:
- SaMD (Software as a Medical Device): 단독으로 의료 목적을 수행하는 소프트웨어
- MDR (Medical Device Regulation): EU의 의료기기 규제
- De Novo Classification: FDA의 위험도 기반 신기술 분류 체계
- Accountability: 결과에 대한 책임성, 법적·윤리적 책임 포함
'논문 읽기 (with AI)' 카테고리의 다른 글
| 의학교육에서의 인공 지능에 대한 범위 검토: BEME Guide No. 84 (Med Teach. 2024) (0) | 2025.04.12 |
|---|---|
| 생성적 인공 지능을 의학교육에 통합하기: 커리큘럼, 정책 및 거버넌스 전략 (Acad Med. 2025) (0) | 2025.04.12 |
| 델파이 연구를 활용한 캐나다 인공지능 의료 커리큘럼 개발 (NPJ Digit Med. 2024) (0) | 2025.04.12 |
| 의학과 사회의 가교 역할-의사-사회과학자 파이프라인 확대의 필요성 (JAMA, 2025) (0) | 2025.04.10 |
| 어머니의 이메일 계정을 삭제하며 (JAMA, 2025) (0) | 2025.04.10 |