A scoping review of artificial intelligence in medical education: BEME Guide No. 84
배경 (Background)
의료 분야에서 인공지능(AI, Artificial Intelligence)의 활용은 환자 진료, 의학 연구, 그리고 보건의료 시스템 전반에 걸쳐 중대한 영향을 미칠 것으로 예상된다(Weidener and Fischer 2023). 자연어처리(Natural Language Processing, NLP), 머신러닝(Machine Learning, ML), 생성형 사전학습 변환기(Generative Pre-trained Transformers, GPT) 등 AI에 접근하기 위한 구체적인 도구나 기법들이 의료 교육의 **내용(content)**뿐만 아니라 과정(process) 자체를 변화시킬 수 있는 잠재력을 가지고 있다. 기술이 지속적으로 발전함에 따라, 입학에서부터 교육과정(curricula), 교수법(teaching), 평가(assessment)에 이르기까지 의학교육의 모든 측면에 걸친 이러한 발전의 영향을 면밀히 검토하는 것이 필수적이다.
AI 분야 자체는 새로운 것이 아니지만, 최근 **머신러닝과 대규모 언어모델(Large Language Models, LLM)**에 기반한 AI의 적용—예컨대 OpenAI의 ChatGPT와 같은 AI 기반 챗봇 애플리케이션의 핵심을 이루는 기술—은 이 기술을 더 많은 사용자들이 쉽게 접근하고 사용할 수 있게 만든 획기적인 전환점이었다. Masters(2023a)는 이러한 변화를 가리켜 "ChatGPT 이전과 이후(pre and post ChatGPT world)를 구분지을 수 있는 중대한 전환점"이라고 평가했다.
AI의 급속한 확산과 함께, 의학교육자들은 이와 관련된 위험성에 대한 우려를 점점 더 강하게 표명하고 있다. 최근 한 의사 방어 단체(physician defense organization)의 글에서는, 학생들이 과제를 수행하는 데 있어 이러한 기술을 사용하는 것과 관련된 위험성을 경고하였다(Graham 2023). 다른 연구들에서도 AI가 학술 출판의 신뢰성과 **학문적 진실성(integrity of academic publishing)**을 훼손할 수 있는 잠재성에 대해 경고하였다(Masters 2023b; Loh 2023).
그와 동시에, AI에 대한 교육자들의 기대감도 커지고 있다. 최근의 주요 연구들은 AI가 평가를 향상시키는 도구로서의 강력한 가능성(예: Schaye et al. 2022)을 지니고 있으며, 입학 및 학생 선발(admissions and selection)과 같은 교육 과정의 효율성을 높일 수 있다는 점(예: Burk-Rafel et al. 2021)을 강조하고 있다.
2021년에 수행된 Lee J 외의 리뷰 연구는, 학부 의학 교육(Undergraduate Medical Education, UME)에서 무엇을(what), 그리고 어떻게(how) AI를 가르쳐야 하는지를 다룬 22편의 다양한 연구들을 확인하였으나, 대학원 의학 교육(Graduate Medical Education, GME)과 지속적 전문성 개발(Continuing Professional Development, CPD) 분야는 범위에서 제외되어 있었다. 특히 최근 12개월 동안 ChatGPT의 출시 이후, AI에 대한 출판물과 관심은 기하급수적으로 증가하고 있으며, 이는 새로운 근거들을 종합적으로 고찰해야 할 필요성을 시사한다.
본 리뷰 연구의 목적은 의료 교육 전 영역에서 AI가 어떻게 적용되고 있으며, 어떤 도전과제를 안고 있는지를 조망하는 데 있다. 우리는 스코핑 리뷰(scoping review) 방법론을 채택하여 현재 문헌의 지형을 그려내고, 관련 근거의 기반을 명확히 하며, 사용된 연구 방법론을 분류하고, 체계적 후속 연구가 필요한 주제 영역들을 도출하고자 했다. 궁극적으로 우리는 이 리뷰를 통해 의료 교육에서 AI 통합의 방향성을 제시하고, 보다 복잡하고 빠르게 변화하는 보건의료 환경에 효과적으로 적응할 수 있는 전문인을 양성하기 위한 기반을 마련하고자 한다.
연구 방법 (Methods)
본 **스코핑 리뷰(scoping review)**는 시작 후 16주 이내의 신속한 기간 내에 완료되었다. 신속한 진행에도 불구하고, 우리는 이전의 연구들(Gordon et al. 2020; Daniel et al. 2021)에 준거하여 **체계성(systematicity)**을 유지하였고, 연구의 진실성(integrity) 및 방법론적 정밀성(methodological precision) 또한 확보하였다. 본 연구의 방법론은 **Arksey와 O’Malley(2005)**의 스코핑 리뷰 프레임워크에 기반하였고, **Levac et al.(2010)**이 제안한 방식으로 이를 정교화하였다. 보고 방식에 있어서는 STORIES 진술(STructured apprOach to the Reporting In healthcare education of Evidence Synthesis)(Gordon and Gibbs 2014)과 **BEME 지침(Hammick et al. 2010)**을 따랐으며, PRISMA-ScR(Tricco et al. 2018) 보고 기준에도 부합하였다. 특히 건강 전문직 교육 분야의 스코핑 리뷰에 특화된 보고 기준이 없는 점을 보완하고자 **Peters et al.(2020, 2022)**의 가이드를 참고하였다. 연구 프로토콜은 다음 링크에서 확인할 수 있다: https://clok.uclan.ac.uk/49900/
스코핑 리뷰는 다음의 5단계 절차를 따랐다(Arksey and O’Malley 2005):
- 1단계: 연구 목표 및 질문 설정
- 2단계: 관련 문헌 탐색
- 3단계: 문헌 선정
- 4단계: 데이터 도표화(charting)
- 5단계: 결과의 통합, 요약, 및 보고
Levac et al.(2010)이 권장한 **6단계(전문가 자문, expert consultation)**는 생략하였다. 그 이유는, 본 연구의 저자진 중 AI 전문가(BK, JC, MS) 및 의학교육 전문가(CM, DD, JC, JH, MD, MG, MH, ST)가 해당 역할을 충분히 수행할 수 있었기 때문이다.
2단계: 검색 전략 (Search Strategy)
**정보 전문 전문가(information specialist)**의 도움을 받아 PubMed/MEDLINE, EMBASE, MedEdPublish를 대상으로 날짜나 언어에 제한을 두지 않고 검색을 수행하였다. 우리는 MeSH 용어와 키워드를 모두 포함한 포괄적인 검색 전략을 사용하였다. 검색어는 **AI, ML, NLP, GPT, 의학교육(medical education)**과 관련된 용어를 기반으로 하였으며, **복잡한 용어 사용을 정제하기 위해 반복적 파일럿 검색(iterative pilot searches)**을 통해 전략을 조정하였다.
2023년 7월에 실시한 초기 검색에서는 총 1,598편의 논문이 확인되었으며, 참고문헌 스크리닝을 통해 누락된 핵심 논문이 식별되면서 추가 조정이 이루어졌다. 최종적으로 보다 포괄적인 검색 전략이 2023년 8월에 수행되었고, 최종 검색 전략은 **보조 부록 1(Supplementary Appendix 1)**에 상세히 제시되어 있다.
또한, 포함된 연구의 참고문헌도 검토하여 누락된 논문이 있는지 확인하였다.
3단계: 문헌 선정 (Study Selection)
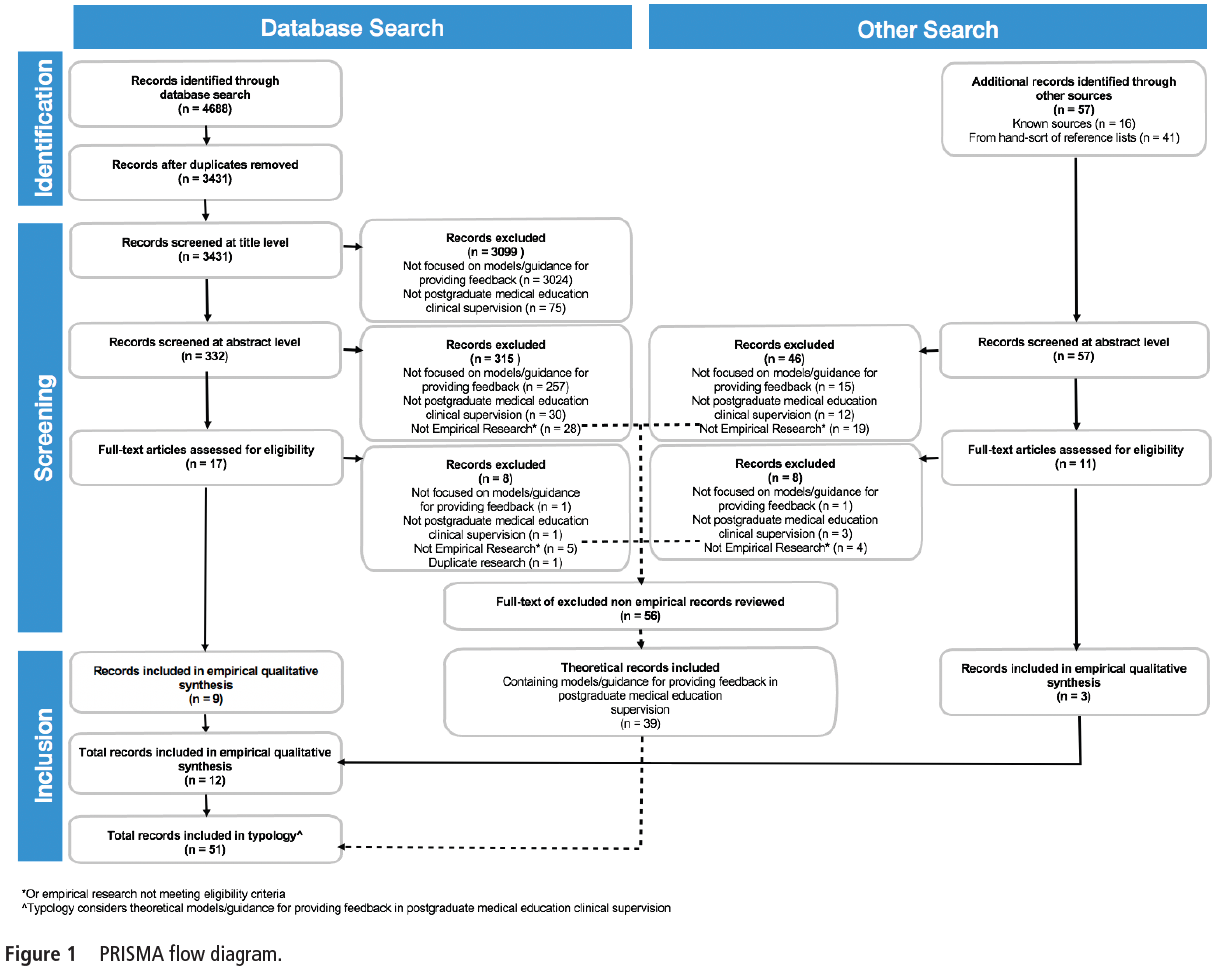
스크리닝 과정은 저자 쌍(AA, HU, MD, MG, RG)이 독립적으로 제목, 초록, 전체 본문을 검토하여 수행하였다. 이견이 있을 경우 상호 합의 또는 제3저자의 판단을 통해 해결하였다. 문헌 선정 과정을 시각적으로 나타내기 위해 **PRISMA 흐름도(PRISMA flow diagram)**를 작성하였다.
포함 기준(Inclusion Criteria)
- AI, ML, NLP, GPT의 의학교육 내 사용 사례를 다룬 논문
- AI의 사용 여부와 관계없이, AI의 영향, 태도, 지식, 관점을 다룬 논문
- **학부(UME), 대학원(GME), 지속적 전문성 개발(CPD)**의 전 범위를 포함한 논문
- 의대생, 전공의, 펠로우, 의사를 대상으로 한 연구 (다직종 학습자 그룹일 경우, 의학 관련 참여자가 주요 비중일 것)
- 교육과정(curriculum), 교수학습(teaching and learning), 평가(assessment) 등 관련 영역을 다룬 논문
- 모든 방법론적 형태의 논문
- 모든 언어로 된 논문
제외 기준(Exclusion Criteria)
- 진단, 임상, 보건의료 조직 운영 또는 거버넌스를 위한 AI 활용 사례를 다룬 논문
- AI를 교육 연구의 도구로만 사용한 논문 (즉, AI 자체가 초점이 아닌 경우)
- 논문 작성에 AI를 활용했지만, AI 자체에 대한 논의는 없는 경우
4단계: 데이터 도표화 (Charting the Data)
이번 연구에서는 포함된 두 가지 명확한 문헌 범주에 따라 각기 다른 데이터 도표화 방식을 적용하였다.
- 첫 번째 범주는 Articles and Innovations로, **의학교육에서 AI 또는 관련 이슈를 실제 또는 제안된 방식으로 활용한 원저 논문(original studies)**에 해당한다.
- 두 번째 범주는 Perspectives publications로, 이는 **의학교육 분야에서 AI와 관련된 이슈에 대해 저자의 전문성, 경험, 기존 문헌 리뷰 등을 바탕으로 의견을 제시하는 학술적 견해글(scholarly perspectives)**이다. 이들은 원저 연구는 아니며, 해당 분야의 통찰에 기반한 **정보성 의견문(informed opinions)**이다.
Articles and Innovations
총 8명의 저자(AA, BK, CJC, HU, MH, MS, NX, RB)가 쌍(pair)으로 작업하며 데이터를 도표화하였다. 이들은 **사전 정의된 데이터 추출 양식(predefined data extraction form)**을 사용했으며, 이는 파일럿 테스트 후 정제되었다. 각 연구로부터 다음 항목들을 추출하였다:
- 연구 식별자: 저자명, 논문 제목, 출판일, 학술지명
- 연구 특성: 교육 단계, 연구 수행국가, 진료과목, 연구 목적, 연구 설계
- AI의 적용 분야 또는 활용 초점: 예) 입학 및 선발, 교육과정, 평가 등
- AI 기술 방법론: 일반적인 AI 개념으로 다루었는지, 또는 의사결정모델(Decision Models, DM), 전통적 머신러닝(ML), 딥러닝(Deep Learning, DL), 자연어처리(NLP) 등 구체적 기술을 사용하였는지 여부
- AI의 활용 사례(Use Cases)
- 사용된 언어모델 및 소프트웨어 프로그램 명칭 (해당되는 경우)
- AI 활용의 근거(Rationale)
- SAMR 기술통합 프레임워크에 따른 분류
(Substitution: 대체, Augmentation: 증강, Modification: 수정, Redefinition: 재정의) - AI 구현 방식에 대한 서술
- 연구 결과 요약 및 Kirkpatrick의 교육성과 평가 모델 적용 여부
- 실제 교육, 정책, 연구에의 시사점(Implications)
Perspectives
총 4명의 저자(JC, CM, JH, ST)가 두 쌍으로 나뉘어 독립적으로 도표화 작업을 수행하였다. 이들은 Articles and Innovations와 유사한 **기본 메타데이터(metadata)**뿐 아니라 다음과 같은 추가 정보도 수집하였다:
- AI 사용의 근거 및 이론적 기반
- AI의 적용 분야 및 기술 프레임워크
- 교육과정 및 연구를 위한 주제 제안
- 윤리적 쟁점 및 적용상의 제약 조건
5단계: 결과 통합, 요약 및 보고 (Collating, Summarizing and Reporting the Results)
Articles and Innovations
모든 저자들은 데이터 추출 양식을 바탕으로 정보를 모아, 시각화가 용이한 다수의 표와 도표로 정리하였다. 이는 현재의 근거 기반(evidence base)을 시각적으로 조망하기 위한 목적이다. 도표화 작업 후에는, **연구에서 다룬 개발 현황의 범위 및 평가된 결과들을 서사적으로 기술한 분석(narrative account)**을 생성하였다. 또한 **연구가 부족한 영역(paucity of research)**을 확인하고, **향후 1차 또는 2차 연구(primary and secondary studies)**가 필요한 영역을 제안하였다. (예: 체계적 문헌고찰)
Perspectives
연구팀은 데이터를 숙지한 후 **체계적인 종합 절차(systematic approach for synthesis)**를 개발하였다. 먼저, 포함된 논문들을 두 가지 중심 주제로 분류하였다:
- 의학교육에 AI 통합의 중요성 (Importance of Integrating AI into Medical Education)
- 의학교육에서의 AI 활용 가능성 (Potential Application into Medical Education)
이 중 두 번째 범주에 대해서는 **실용성 중심의 접근(utility-focused approach)**을 적용하였으며, 각 논문이 독자에게 제공할 수 있는 **‘기여(Contributions)’**를 강조하였다. 비록 대부분의 논문이 실제 평가나 연구를 거치지는 않았더라도, 이들 기여는 정보에 기반한 의사결정, 교육 프로그램 설계, AI 응용 평가 등에서 핵심적인 역할을 할 수 있다. 기여 내용은 다음과 같이 구분하였다:
- 제안된 교육적 적용 및 개발
- 교육 프레임워크
- 교육과정 내용, 역량(competencies), 도구 및 자원에 대한 제언
- 윤리적 고려사항(Ethics Considerations)
각 단계에서는 팀 구성원들이 독립적으로 분류 작업을 수행한 후, **합의(consensus)**를 도출하는 토론을 거쳤다. 결과는 **‘간단한 요약(Brief Summary)’**과 **‘핵심 포인트(Key Points)’**로 구성된 서사적 종합(narrative synthesis)으로 정리되어, 독자들이 내용을 보다 쉽게 이해하고 실제 교육에 적용할 수 있도록 하였다.
결과 (Results)
개요 (Overview)
데이터베이스 검색을 통해 총 2,123편의 논문이 확인되었으며, 중복 논문을 제거한 후 2,019편이 남았다. 제목 및 초록 스크리닝 과정을 통해 310편으로 추려졌으며, **평가자 간 신뢰도(inter-rater reliability)**는 매우 높아 κ = 0.86을 기록하였다. 이후 전면 본문 검토를 통해 AI를 단순한 연구 도구로만 사용하거나, AI에 대한 초점이 부족한 논문 70편이 제외되었고, 최종적으로 241편이 포함 대상으로 선정되었다.
**참고문헌 수기 검색(hand-searching references)**을 통해 추가로 37편의 논문이 발견되었으며, 총 278편의 논문이 본 스코핑 리뷰에 포함되었다. 전체 선정 과정을 요약한 PRISMA 다이어그램은 Figure 1에, 포함 논문에 대한 세부 정보는 Appendix 표 형태로 저장소(repository)에 업로드되어 있으며, 아래 링크를 통해 접근 가능하다:
https://clok.uclan.ac.uk/49919/

Figure 2의 인포그래픽은 포함된 연구들의 세부 내용을 요약하고 있다.
**지리적 분포(Geographic distribution)**를 보면, 연구는 **주로 영어권 북미 지역(Anglo-North American)에서 수행된 것이 가장 많았으며, 총 138편(49.6%)**이었다. 그 외 지역 분포는 다음과 같다:
- 유럽(European): 51편 (18.4%)
- 동아시아(East Asian): 22편 (7.9%)
- 중동(Middle Eastern): 22편 (7.6%)
- 남아시아(South Asian): 17편 (6.1%)
그 외 지역은 소수의 연구만 포함되었으며, 아프리카 지역(Africa)에서는 연구가 확인되지 않았다.

AI와 의학교육을 주제로 한 가장 이른 시기의 출판은 1992년에 이루어졌으며, 시간 흐름에 따라 2018년 이후 급격한 증가세를 보였다. 연도별 출판 현황은 다음과 같다:
- 2018년: 11편
- 2019년: 14편
- 2020년: 18편
- 2021년: 49편
- 2022년: 57편
- 2023년 8월 기준: 114편
(자세한 내용은 Figure 2a, 2b 및 보조부록 1의 E, I열과 부록 2 참고)

전체 포함 논문 중 Articles 또는 Innovations 범주에 해당하는 논문은 **191편(68.7%)**이었으며, 나머지 **87편(31.3%)**은 Perspectives 범주에 속하였다. 의학교육 단계별 분포를 보면,
- **학부 의학교육(UME)**에 초점을 맞춘 논문이 135편(48.6%),
- 대학원 의학교육(GME) 관련 논문이 62편(22.3%),
- 지속적 전문성 개발(CPD) 관련 논문은 **7편(2.5%)**이었다.
- 나머지 **74편(26.6%)**은 UME, GME, CPD 중 둘 이상을 포괄하거나 명확한 구분이 없는 경우였다.
(자세한 분포는 Figure 2c, 2d 및 부록 2의 H열 참고)

기초의학(basic science) 분야는 6개, 임상의학(clinical specialties)은 총 24개 전공이 논문에 포함되어 있었다. 가장 많이 등장한 기초의학 전공은 **해부학(Anatomy)**과 **생리학(Physiology)**으로 각각 **4편(1.4%)**씩이었다. 임상 전공 중 가장 빈도가 높은 분야는 다음과 같았다:
- 영상의학(Radiology): 31편 (11.2%)
- 외과(Surgery): 24편 (8.7%)
- 그 뒤를 이어
- 안과(Ophthalmology): 8편 (2.9%)
- 신경외과(Neurosurgery): 6편 (2.2%)
한편, 157편(56.5%)의 논문은 특정 전공 또는 전공 구분 없이 수행되었다. (세부 내용은 Figure 2e 및 보조부록 2의 J열 참조)
포함된 Articles 및 Innovations
본 리뷰는 매우 다양한 Articles(원저 연구) 및 **Innovations(교육 혁신 사례)**를 포괄하며, Supplementary Table 2에서 A1–A191로 체계적으로 분류 및 표기되어 있어 리뷰 전반에서 **상호 참조(cross-reference)**가 용이하다.
이들 중,
- **7편(3.6%)**은 입학 및 선발(admissions and selection) 과정에서 AI를 사용한 연구(A1–A7)였고,
- **34편(17.8%)**은 **AI에 대한 교육 또는 AI를 활용한 교수(instruction)**에 초점을 두었으며(A8–A41),
- **50편(26.2%)**은 **평가(assessment)**에 AI를 적용한 연구(A42–A91)였다.
- **13편(6.8%)**은 임상 추론(clinical reasoning) 교육 또는 평가에 AI를 사용하였고(A92–A104),
- **4편(2.1%)**은 **증례 및 술기 기록 자동화(automation of case and procedure logs)**에 AI를 활용하였다(A105–A108).
- 또한, **51편(26.7%)**은 **의료에서의 AI에 대한 지식 또는 태도(knowledge or attitudes)**를 조사하였고(A109–A159),
- **32편(16.8%)**은 **대형 언어 모델(Large Language Models, LLMs)**의 **의학 문제 혹은 시험에 대한 성능(performance)**을 평가하였다(A160–A191).
(자세한 정보는 Figure 2f 및 Supplementary Appendix 2의 M열 참조)

AI의 기술적 적용 방식 (Technical Application)
AI가 실제 계산 없이 **일반 개념(general concept)**으로만 다뤄진 경우는 **65편(34%)**이었다. 나머지 연구에서는 다양한 컴퓨팅 기법이 활용되었으며, 구체적으로는:
- 데이터 마이닝(Data Mining): 4편 (2.1%)
- 전통적 머신러닝(Traditional ML): 41편 (21.5%)
- 딥러닝(Deep Learning, DL): 81편 (42.4%)
- 자연어처리(Natural Language Processing, NLP): 78편 (40.8%)
(자세한 분포는 Figure 2g, 2h 및 Supplementary Appendix 2의 N, O열, AI 관련 용어 정리는 Table 1 참조)


기술 통합 수준: SAMR 프레임워크 적용 결과
본 리뷰는 기술 통합 수준을 분석하기 위해 SAMR 프레임워크를 활용하였다.
그 결과, AI는 다음과 같은 방식으로 활용되었음을 확인하였다:
- Substitution(대체) 수준: 36편 (18.8%)
- Augmentation(기존 과정 증강): 34편 (17.8%)
- Modification(과제의 재설계): 10편 (5.2%)
- Redefinition(기존에는 불가능했던 새로운 과제 창출): 11편 (5.8%)
- 한편, **SAMR 분류가 적용되지 않은 사례는 100편(52.4%)**에 달했다.
(자세한 수치는 Figure 2i 및 Supplementary Appendix 2 참조)
AI 활용 유형: Use Cases
이 리뷰는 포함된 논문에서 AI의 다양한 **활용 사례(use cases)**도 파악하였다. 구체적으로는 다음과 같다:
- 데이터 분석(Data analytics): 9편
- 예측 모델(Predictive models): 17편
- 성과 분석(Performance analytics): 19편
- 감정 분석 또는 편향 평가(Sentiment analysis or bias evaluation): 7편
- 가상 환자 시뮬레이터(Virtual Patient Simulators, VPSs): 11편
- 개인 맞춤형 학습 플랫폼 또는 지능형 튜터링 시스템(Personalized learning platforms or intelligent tutoring systems): 6편
- 수련생 대상 임상적 의사결정 지원(Clinical guidance for trainees): 10편
- 수술 또는 술기적 안내(Procedural guidance for trainees): 5편
- 챗봇(ChatBots): 2편
- 데이터 라벨링(Data labeling): 2편
- 콘텐츠 생성(Content generation): 5편
- 총괄 평가 수행(Summative assessment completion): 32편
(상세한 분류는 Figure 2j 및 Supplementary Appendix 2의 P열 참고)

의과대학 및 레지던시에서의 입학 및 선발에 AI를 활용한 연구
(AI use in admissions and selection for medical school and residency)
한 연구(A7)에서는 **AI 챗봇(Chatbot)**을 활용하여 **입학 지원자 모집 과정 중 가상 질의응답 세션(virtual Q&A session)**을 운영하였다. 또 다른 연구(A5)에서는 감정 분석(sentiment analysis) 기법을 이용해, **지난 30여 년간 외과 레지던시 지원자 추천서에 존재하는 성별 편향(gender bias)**을 탐지하였다. 이 연구는 성별 편향이 시간이 지나면서 감소하긴 했지만 여전히 남성에게 유리하게 긍정적 편향이 존재함을 보여주었으며, 이는 선발 결과에 영향을 미친다고 밝혔다.
한편, 연구(A3)에서는 교수들이 평가한 **의대생 성적 평가서(Medical Student Performance Evaluations, MSPEs)**와 기성 감정 분석 프로그램을 활용한 머신러닝(ML) 모델의 점수를 비교하였다. 그러나 MSPE 대부분이 매우 긍정적 표현으로 작성되었기 때문에, 해당 ML 모델은 효과적으로 순위를 매기지 못했다. 이에 따라 향후 교수 평가를 보다 잘 모사할 수 있는 맞춤형 모델 개발의 가능성이 제시되었다.
또 다른 연구(A4)에서는 ML을 활용하여 지원자가 매칭될 가능성(ranking and matching)을 예측하는 모델을 개발하였고, 그 결과 **수신기 조작 특성 곡선 하 면적(AUROC)**이 0.925로 매우 높은 예측 정확도를 보였다. 총 세 건의 연구(A1, A2, A6)에서는 ML을 활용해 지원서 스크리닝을 실시했으며, 이는 회고적(retrospective) 데이터셋으로 학습 후, 회고적 또는 전향적(prospective) 데이터셋으로 검증되었다. 이들 모델은 0.925–0.95의 AUC 범위를 기록하며 매우 높은 정확도를 보여, **대량의 지원서를 심층적으로 평가하는 전체적 검토(holistic review)**를 부분적으로 자동화하는 데 기여할 가능성을 제시하였다.
특히, **인간 평가를 보완하는 방식(restorative fashion)**으로 적용될 경우, ML 모델은 편향을 줄이고, 기존에는 인터뷰 기회를 얻지 못했을 지원자를 새롭게 식별하는 데 도움을 줄 수 있다(A1). 이러한 모델들이 더욱 정교화되고 검증이 이루어진다면, 지원자 선별 과정의 효율성과 공정성을 향상시키고, 랭킹 프로세스를 보다 정확하게 만들 가능성이 있다.
AI에 대한 교육 및 AI를 활용한 교수
(Teaching about AI and AI-augmented instruction)
총 33편의 논문(A8–A41)이 AI에 대한 교육 또는 AI를 활용한 교수법을 다루었다. 이 중
- 12편은 학습 도구로서의 AI,
- 11편은 교육과정 개발(curriculum development),
- 3편은 개인 맞춤형 학습을 위한 AI,
- 5편은 의학교육 시뮬레이션에서의 AI 활용,
- 2편은 AI 관련 교육 역량을 주제로 하였다.
학습 도구로서 AI를 다룬 12편 중 7편은 **영상 이미지에서 특정 소견을 판별하는 훈련(training on image findings)**에 집중하였다. 예를 들면,
- **사구체 질환(glomerulopathies)**의 조직학적 판별(A22),
- 신경해부 구조(neuroanatomic structures)(A35),
- 일반 조직 유형(general tissue types)(A31),
- 흑색종(melanomas)(A25) 식별 교육이 이에 포함된다.
또 다른 논문에서는
- 당뇨망막병증(diabetic retinopathy)(A26, A30),
- X-ray 상 고관절 골절(hip fractures)(A24)을 식별하는 훈련도 제시하였다.
한 연구는 AI를 이용해 심초음파 영상 획득 시 실시간으로 최적의 시야를 안내하는 시스템(A32)을 설명했고, 다른 논문에서는 AI 알고리즘을 직접 개발하여 폐 구조를 초음파로 식별하는 훈련 과정(A33)을 다루었다.
그 외에도, 챗봇(chatbot) 스타일의 도구를 활용하여
- 해부학 학습(A29),
- 나쁜 소식 전달 훈련(breaking bad news)(A34),
- 수술 절차 요약 생성(surgical procedure summaries)(A28) 등에 활용한 연구도 있었다.
교육과정 개발(curriculum development) 관련 11편 중
- 6편은 교수 모듈 개발에 관한 연구였으며,
- 그중 4편은 AI 및 ML의 기초 개념을 학부생에게 가르치는 방식을 다루었다(A11, A13, A16, A19).
- GME/CPD 대상 연구에서는 주로 영상의학(radiology) 전공자를 대상으로 진행되었으며,
- AI 워크숍(A14, A17),
- 딥러닝 커리큘럼(A18),
- 데이터과학 선택과목(data-science elective)(A20),
- **의료 의사결정모델(medical DM) 교육(A21)**이 포함되었다.
- 한 연구는 **현직 의사를 위한 AI 입문 과정(A12)**을 소개하였다.
개인 맞춤형 학습을 위한 ML 활용 연구 3편은 다음과 같다:
- 노인 환자 평가를 위한 NLP 기반 즉시 학습(just-in-time learning) 지원 알고리즘(A36),
- 예비 임상과정 학생을 위한 ML 기반 적응형 학습 시스템(adaptive learning system)(A37),
- 안과환자 선별을 위한 DL 모델(patient triage)(A38)
의료 시뮬레이션에서 AI를 활용한 연구 5편은 다음 주제를 다루었다:
- **로봇 표준화 환자(robotic SP)**에 대한 인터뷰(A39),
- 심전도(ECG) 및 피부전도(GSR)를 활용한 인지 부하 평가(A40),
- 시뮬레이션 영상 분석을 위한 DL 기반 결과 평가(A41),
- 단일 신장의 시뮬레이션을 위한 ML 기반 멀티미디어(A23),
- 피부 질환 이미지 생성을 위한 생성형 AI 사용(A27)
마지막으로, **AI 교육 역량(educational competencies)**을 다룬 2편의 연구에서는
- **의대생이 임상현장에서 AI를 활용할 준비 정도를 평가하는 도구 개발(A9)**과
- **독일 GME 및 CPD 과정에서 AI 관련 역량의 보급 현황 조사(A10)**를 수행하였다.
평가에서의 AI 활용
(AI Use in Assessment)
AI를 평가(assessment)에 활용한 논문은 총 50편으로, 이 중 가장 두드러진 분야는 심리운동기술(psychomotor skills) 평가였으며, 21편의 연구가 이에 초점을 맞추었다. 이들 중
- 18편은 외과 수술기술(surgical skills),
- **3편은 술기(procedural skills)**에 대한 평가였고,
술기 관련 연구는 모두 기도삽관(intubation) 기술에 국한되었다(A71–A73).
수술기술 평가 연구들은 주로 일반외과(general surgery) 내에서의 최소침습수술(minimally invasive surgery) 및 **로봇수술(robotic surgery)**을 대상으로 하였으며(A74–A83, A85, A87–A88, A91), 일부는 **신경외과(neurosurgery)(A84, A86, A89)**와 **소아외과(pediatric surgery)(A90)**를 다루었다.
그 외에도
- 서술형 텍스트 분석(narrative text analysis): 15편
- 임상기술(clinical skills): 10편
- 객관식 문제(MCQs) 생성: 3편
- 예측 분석(predictive analytics): 1편
이 있었다.
특히 주목할 만한 경향은, ML을 사람의 관찰 및 피드백을 대체하거나 보완하는 도구로 사용하는 것이었다(A74, A76–A78, A83, A86, A88, A90). 다수의 연구들은 가상 트레이너나 시뮬레이터를 사용하여 시뮬레이션 환경에서 평가를 수행하였다. 예컨대, **클라우드 기반 AI 비디오 분석(cloud-based, AI-powered video analytics)**을 통해 최소침습수술에서 사용자의 수행을 모니터링하고 평가한 혁신적 접근이 소개되었다(A81).
일부 연구에서는, 시각적 또는 운동적 입력(visual or kinesthetic input)을 기반으로 **숙련도(expertise level)**를 감별하거나, **학습 곡선(learning curve)**을 예측하는 알고리즘을 개발하였다(A74–A76, A80, A84, A85, A86, A87, A91). 한 연구는 참여자의 뇌파(EEG) 데이터를 ML 모델에 통합하여, 전문 외과의와 초보자의 차이를 구분하는 시스템을 제안하였다(A89).
이러한 연구들은 기존 평가가 갖는 높은 자원 소모 및 편향 가능성을 AI가 감소시킬 수 있는 잠재력을 지닌다는 점을 시사한다.
AI는 서술형 텍스트 기반 평가(narrative text assessment) 영역에서도 점차 활용되고 있으며, **감정 분석(sentiment analysis)**과 **자연어처리(NLP)**가 주요 도구로 활용되었다. 이는 **정량 평가(예: 평점)**에 더해, 광범위한 서술형 정보를 효율적으로 분석하고 맥락화하는 자동화된 방법으로 주목받고 있다.
AI는 다음과 같은 영역에 적용되었다:
- 레지던트에 대한 교수의 서술형 평가: A55, A57, A62–A64, A67–A68, A69
- 클럭십(clerkship) 학생에 대한 평가: A55, A56, A65
이러한 연구들은 AI를 활용하여
- 임상역량위원회(Clinical Competency Committees)의 의사결정 보조(A55)
- 역량 개발에 대한 통찰 도출(A57, A68–A69)
- 교수 피드백의 질 평정(A64, A67)
- 객관적 해석 지원(A65)
- 위험 학습자 식별(A68)
- 편향 탐지(A56, A66) 등을 수행하였다.
또한 NLP는
- 학생의 반성적 글쓰기(reflective writing) 분석(A59)
- 단답형 응답에서의 전문직업성 평가(A61)
- 교수 피드백 중 전문성 결여 가능성 탐지(A60)
- 의사의 전문성 및 환자안전 관련 성과 평가(A58) 등에도 사용되었다.
임상기술 평가(clinical skills assessment) 연구 10편 중 7편은 학부교육(UME) 맥락에서 수행되었다. 이들 연구에서 **가상 환자 시뮬레이터(VPSs)**는 시간 및 자원 등 전통 평가의 물리적 부담을 줄이고, **원격 시험(remote examination)**이 가능하도록 도왔다(A42, A48–A49, A51). AI는
- 가상 OSCE(Objective Structured Clinical Examinations) 구현(A42, A49),
- OSCE 자동 채점(automated grading)(A43–A44, A50),
- AI 기반 OSCE 평가 전반(A46, A48, A51)에도 적용되었다.
GME 맥락에서는,
- 의사소통 기술 교육을 위한 가상 시뮬레이터와
- 자동 평가 및 피드백 시스템이 적용되었으며(A47),
- 중환자실 수련생의 구술 증례 발표에 대한 NLP 평가도 이루어졌다(A45).
객관식 문항(MCQs) 생성을 주제로 한 3편의 연구(A52–A54)는
**딥러닝(DL)**과 NLP를 활용하여 시험 문항 및 학습 도구를 자동 생성하는 방법을 탐구하였다. 이들은
- AI가 문항 개발에서 수작업 부담을 크게 줄일 수 있는 잠재력을 강조하였지만,
- 여전히 문항의 품질 확보를 위한 인간 검토가 필요하다는 점도 지적하였다.
AI의 빠른 속도가 주요 장점으로 언급되었고, ChatGPT가 선호 도구로 자주 사용되었다. 그러나 결과는 일관되지 않았고, AI가 MCQ 생성을 전적으로 대체하기에는 시기상조라는 회의적 시각도 존재하였다(A52–A54).
마지막으로, **예측 분석(predictive analytics)**은 여러 수술기술 평가 연구에서 중요한 역할을 수행하였으나, 해당 주제를 **주제로 삼은 연구는 단 1편(A70)**뿐이었다. 이 연구는 의대생의 고부담(high-stakes) 시험에서의 성과를 예측하는 ML 모델을 개발하여, AI가 고위험 환경에서의 학업 성취를 예측하는 새로운 가능성을 제시하였다.
임상 추론 교육 및 평가에서의 AI 활용
(AI to Teach and Assess Clinical Reasoning)
임상 추론(clinical reasoning) 교육 및 평가에 있어 AI의 역할을 탐구한 연구는 총 13편이며, 이는 **의미 있는 새로운 영역의 가능성(promising frontier)**을 보여준다.
그 중 8편의 연구는 **AI 기반 가상 환자 시뮬레이터(Virtual Patient Simulators, VPSs)**와 **지능형 튜터링 시스템(Intelligent Tutoring Systems, ITSs)**의 융합에 초점을 맞췄다(A92, A95–A98, A101–A102, A104).
- VPSs는 학습자가 아바타 또는 텍스트 인터페이스를 통해 질문하고 답변을 받으며, **역동적(clinically dynamic)**인 환경에서 다양한 임상 시나리오를 바탕으로 추론 능력을 연습할 수 있도록 한다.
- 이를 통해 학습자는 정보 수집(information gathering), 가설 설정(hypothesis generation), 문제 표현(problem representation), 진단 정당화(diagnostic justification) 등 임상 추론의 전 과정을 연습할 수 있다.
ITSs는
- 개인화된 학습 및
- 실시간 피드백을 제공하면서,
- 올바른/잘못된 추론 반응을 통해 학습 과정을 안내하고(A92, A95–A97, A101–A102),
- 추가 학습 자료를 제안하기도 한다(A95).
또한, 분석 도구와 결합되었을 때(A92, A96, A101, A102), 이 시스템들은 학습자 및 교육자에게 정교한 성과 피드백과 개선 영역의 통찰을 제공할 수 있었다. 총 6편의 연구는 해당 시스템의 효과에 대해 Kirkpatrick 1단계(A92, A98, A101) 및 2b 단계(A92, A95–A96, A101–A102) 수준의 근거를 보고하였다.
VPS 및 ITS 케이스 개발은 일반적으로 많은 자원과 전문가의 투입을 필요로 하지만,
2편의 연구(A101, A104)에서는 **자연어처리(NLP)**를 활용해 이를 자동화하는 혁신적인 사례를 제시하였다.
- 각각 413건 및 2,525건의 사례를
- 실제 병원 진료기록 또는 New England Journal of Medicine의 임상 케이스 시리즈에서 추출하여 자동 생성하였다.
이러한 **방대한 사례 라이브러리(case library)**는 임상 추론 교육에서 자주 문제로 지적되는 사례의 다양성 부족과 실제 임상에서의 예측 불가능성 문제를 효과적으로 보완할 수 있었다.
ML을 활용하여 **서면 기록(written notes)**을 분석하고 임상 추론을 평가한 연구도 3편 포함되었다(A93–A94, A99).
- 예를 들어,
- OSCE 이후 서술 평가(Post-encounter OSCE notes)(A93),
- 진단 정당화 에세이(diagnostic justification essays)(A94),
- **EHR 기반 전공의 입원기록(admission notes)**을 대상으로 하였다.
- 이때 **IDEA 도구(standardized rubric)**를 기준으로 사용하였다(A99).
해당 ML 알고리즘의 **심리측정학적 타당도와 평가자 간 신뢰도(inter-rater reliability)**는 수용 가능한 수준으로 보고되었으며, 특히 한 연구(A93)는 κ(kappa) = 0.8로, **고부담 평가(high-stakes assessment)**에 적합한 신뢰도 기준을 충족하였다. 다른 연구들도 **중저위험 평가(low-stakes assessments)**에서는 적절한 기준을 만족하였다. 이들 연구는 **임상 노트(clinical notes)**라는 기존에 과소활용되던 평가 자원을 활용하여,
- 평가의 효율성 향상,
- **형성 평가(formative feedback)**의 질적 향상에 기여할 수 있음을 보여준다.
해당 영역의 마지막 두 편의 연구는 AI의 확장 가능성을 강조하였다.
- 첫 번째 연구(A100)는 **신경망(neural networks)**을 활용해 성공적인 문제 해결 패턴을 인식하였고,
- 두 번째 연구(A103)는 **3개의 대형 언어모델(LLMs)**을 비교 평가하여 주니어 의사에게 임상 의사결정 지원을 제공할 수 있는지를 분석하였다.
저자들은, 의료 데이터베이스 기반으로 학습되고 전문가 검토를 거친 고도화된 LLM이 향후 가치 있는 교육 도구가 될 수 있음을 강조하였다.
임상 및 술기 기록 자동화를 위한 AI 활용
(AI Use for Automation of Case and Procedure Logs)
총 4편의 논문은 AI/ML을 활용한 수련생의 임상 및 술기 경험 기록 자동화를 다루었다.
- 한 연구(A107)는 **자연어처리 기반 알고리즘(NLP)**을 활용하여
- 수련생의 임상 노트에서 핵심 임상 개념을 식별하고,
- 이를 전문가가 정의한 핵심 임상 문제(core clinical problems)에 매핑하였으며,
- **정확도는 92.3%**에 달하였다.
- 또 다른 연구(A105)는 상용 NLP 제품을 기반으로
- 신경과 전공의의 증례 경험을 자동 추적하였으며,
- 1개월간 기록된 증례 수가 3배 증가하는 성과를 보였다.
- 세 번째 시스템은 **‘Trove’**로 명명되었으며(A106),
- 전공의가 생성한 영상 진단 소견을 기반으로
- 진단 분류를 자동 산출하고,
- **대시보드(dashboard)**에 결과를 표시하였으며,
- 정확도는 93.2%에서 97.0% 사이였다.
- 마지막 시스템(A108)은 **심층 신경망(Deep Neural Network)**과 **강화 학습 모델(Reinforcement Learning)**을 결합하여,
- EHR 데이터 및 수술 일정 정보를 바탕으로
- 전공의가 기록해야 할 수술 경험 데이터를 자동 제안하였다.
AI에 대한 지식
(Knowledge of AI)
포함된 논문 중 **51편(26.7%)**은 AI에 대한 지식, 인식(perceptions), 태도(attitudes), 기대(hopes), 우려(concerns) 등을 다루었다. 총 3편의 연구에서는 **AI 지식에 대한 객관적 평가(objective assessment)**를 수행하였다.
- 스페인에서는 의대생 281명을 대상으로 참/거짓 문항을 사용하여 일반적인 AI 지식을 평가한 결과, **정답률은 65%**였다(A117).
- 사우디아라비아에서는 의대생 476명을 대상으로 **딥러닝(DL)**에 대한 지식을 평가하였고, 이 중 54%가 5개 참/거짓 문항에 하나도 정답을 고르지 못했다(A118).
- 호주, 뉴질랜드, 미국을 대상으로 한 또 다른 연구에서는 의대생 245명을 대상으로 머신러닝(ML) 지식을 **객관식(MCQs)**으로 평가했으며, **평균 점수는 49.7%**에 그쳤다(A120).
자기 보고(self-reported) 형태의 AI 지식 수준은 지역에 따라 다양했다.
- 서호주(Western Australia)의 연구에서는 의대생의 85%가 AI에 대한 기초적인 이해를 가지고 있다고 응답하였고(A151),
- **소아안과 전문의의 91%**도 기본적인 AI 개념에 익숙하다고 보고했다(A154).
- 반면 독일 의대생은 31%만이 AI 기술에 대한 기초 지식이 있다고 응답하였다(A145).
- 한 대학병원의 소아영상의학 전공의를 대상으로 한 포커스 그룹 인터뷰에서는 AI 관련 용어와 문헌 해석에 어려움을 겪는 모습이 관찰되었다(A156).
한국에서 수행된 설문(A127)에서는,
- 의대생들이 AI 관련 정보를 얻는 주요 경로로 뉴스나 방송(82%),
- 소셜미디어(41%),
- 강의(32%),
- 친구나 가족(29%) 등을 꼽았고,
- 학술 논문이나 책을 이용하는 비율은 **22%**에 불과했다.
미국의 한 연구에서도, 의대생의 72%, 교수의 59%가 미디어를 통해 AI를 접하고 있다고 보고되었다(A159).
AI 관련 강좌(course)의 개설 현황은 국가 간 차이가 컸다.
- 독일에서는 의과대학의 71.8%가 AI 과목을 제공하였으며, 대부분 **선택 과목 또는 비교과 과정(extra-curricular)**으로 운영되었다(A142).
- 반면 캐나다 의대생을 대상으로 한 조사에서는, 85%가 의과대학 커리큘럼 내에 정규 AI 교육이 없었다고 응답하였다(A146).
임상의학에서의 AI 활용에 대한 태도
(Attitudes Towards the Application of AI in Clinical Medicine)
AI의 임상 적용에 대한 태도는 다양하게 혼재되어 있었다. 다수의 의대생과 의사들은 AI가 임상 판단(clinical judgment), 연구(research), 감사 감사(auditing) 능력을 향상시키고, **행정 업무의 효율화(streamlining administrative processes)**에 기여할 수 있다고 인식하였다(A111, A117, A141).
그러나 동시에
- 윤리적 문제(ethical implications),
- 의사-환자 관계 약화(weakened physician–patient relationships),
- 예측 불가능한 상황에서의 AI의 한계 등에 대한 우려도 존재했다(A114, A119, A154, A140).
**의대생의 AI 사용 의도(intention to use AI)**를 다룬 두 편의 연구에서,
- 한 연구는 **UTAUT 모델(Unified Theory of User Acceptance of Technology)**을 이용해 **진단 지원(diagnostic support)**에 대한 AI 사용 의도를 조사하였고, ‘사회적 영향(social influence)’이 유일한 결정 요인으로 나타났다(A153).
- 다른 연구에서는, AI가 의료의 미래에서 중요한 역할을 한다는 강한 신념이 있을 때만 사용 의도가 나타났다(A157).
의학교육에서의 AI 활용에 대한 태도
(Attitudes Toward the Application of AI in Medical Education)
두 편의 연구가 AI의 의학교육 내 활용에 대한 인식을 조사하였다.
- 한 연구에서는 레바논 의대생을 대상으로 평가(assessment)에 AI를 활용하는 것에 대한 인식을 조사하였는데,
- 58%가 AI가 사람보다 더 객관적일 수 있다고 응답했지만,
- **AI만을 활용한 평가를 선호한 비율은 26.5%**에 불과했고,
- 71%는 인간과 AI의 병합된 평가 방식을 선호했다(A131).
- 또 다른 카리브 해 지역 의과대학 연구에서는
- 교수 중 33%가 ChatGPT를 사용하고 있었으며,
- 주로 객관식 문항(MCQs)을 생성하는 데 활용하였다.
- 그러나 잘못된 정보(misinformation)의 교육자료 내 유입과 **표절(plagiarism)**에 대한 우려가 존재했다.
AI에 대한 기대와 우려 (Concerns and Hopes for AI)
AI에 대한 주요 우려 사항은 다음과 같았다:
- AI로 인해 의사의 수요가 줄어들 수 있다는 점,
- 특히 **방사선과(radiology)**처럼 기술 대체 가능성이 높은 전공의 진로 선택에 부정적 영향을 미칠 수 있다는 점(A113, A115, A124, A135, A137, A147, A150).
- 의과대학 커리큘럼에서 AI 교육이 충분하지 않다는 점(A128, A143, A151)도 중요한 우려였다.
**세 편의 연구(A133, A156, A158)**는, 의학교육에 포함되어야 할 AI 관련 교육 주제로 다음을 제안하였다:
- 임상 응용(clinical applications)
- 알고리즘 개발 및 평가(algorithm development and appraisal)
- 코딩(coding)
- AI의 기초, 통계학, 윤리, 개인정보 보호(basics of AI, statistics, ethics, privacy)
의학 시험에서의 대형 언어 모델(LLMs) 성능|
(Performance of LLMs on Medical Exams)
총 **32편의 연구(A160–A191)**는 **대형 언어 모델(Large Language Models, LLMs)**이 의학 시험 또는 대형 문항은행(question banks)에서 추출한 문제를 푸는 능력을 평가하였다. 평가에 포함된 LLM에는
- Microsoft Bing Chat,
- ChatGPT,
- GPT-3, GPT-3.5, GPT-4,
- Google Bard,
- 그리고 **기타 사전 학습 언어모델들(pre-trained language models)**이 포함되었다.
이들 모델은 다음과 같은 형식의 시험에서 테스트되었다:
- 객관식 문제(Multiple Choice Questions): A160–A185, A188–A190
- 단답형 및 서술형 문제(Short answer and essay questions): A186–A187, A191
이미지 및 도해를 포함한 문항은 LLM이 시각 정보를 처리하는 데 제약이 있기 때문에 대부분 제외되었다. 몇몇 연구에서는 LLM에게 응답에 대한 ‘정당화(justification)’를 요구하기도 했으며(A164, A168, A175–A176), 이 응답의 정확성도 평가되었다.
LLM의 성과는
- 초보자부터 전문가까지의 다양한 수준의 인간 응답자,
- 정답 기준(gold standard answers)
과 비교되었다(A160–A191).
그 결과, LLM은
- 대학 차원의 기초의학 및 임상의학 시험,
- 국가 자격시험(national licensure exams),
- 전문의 자격시험(specialty licensure exams) 등에서
합격 기준 이상을 기록하거나 뛰어난 성적을 거둔 사례들이 보고되었다.
예를 들면,
- 대학 자체 시험: A178, A183, A184
- 국가시험: A160, A169, A180, A182, A187, A189
- 전문과목 시험: A169, A175, A181
그러나 일부 시험에서는 성과가 보통이거나 낮은 수준에 그친 경우도 존재하였다(A168, A170, A173–A174, A176, A190).
- 일반적으로 최신 세대의 LLM이 이전 세대 모델보다 성능이 뛰어났지만,
- 이러한 경향이 모든 시험에서 일관되게 나타난 것은 아니었다.
또한, 일반 의학 시험에서는 더 좋은 성과를 보였으나, - 전공 및 세부 전공 시험에서는 상대적으로 낮은 성적을 기록하는 경우도 있었다.
시험은 다양한 국가의 시험 문제를 기반으로 진행되었으며, 다음과 같은 국가들이 포함되었다:
- 오스트레일리아 (A177)
- 캐나다 (A162, A174)
- 중국 (A173, A190)
- 프랑스 (A160, A170, A181)
- 독일 (A165, A182)
- 인도 (A160, A163, A183–A184, A187)
- 이탈리아 (A160)
- 일본 (A189)
- 대한민국 (A171, A180)
- 네덜란드 (A179)
- 사우디아라비아 (A178)
- 스페인 (A160)
- 스위스 (A185)
- 대만 (A173)
- 터키 (A166)
- 영국 (A160, A167, A191)
- 미국 (A160–A161, A164, A168–A169, A172–A173, A175–A176, A186, A188)
대부분의 경우, 영어로 된 문제에서 LLM이 더 좋은 성과를 보였으며, 다른 언어로 된 문항을 영어로 번역한 경우에도 성능이 향상되었다. 그러나 타 언어에서의 성능은 매우 가변적이었으며,
예를 들어
- 프랑스어 문제에서는 정확도 22%,
- **이탈리아어 문제에서는 정확도 73%**로 큰 차이를 보였다(A160, A170).
현재로서는,
- 학습자와 교육자는 LLM의 정확도에 변동성이 크다는 점을 인식하고 신중히 접근할 필요가 있다(A188).
- 그러나 최신 LLM들의 눈에 띄는 성능 향상은 이러한 한계를 조만간 극복할 가능성을 보여준다.
LLM의 능력이 향상됨에 따라,
- 공식 평가(formal assessment)의 공정성(integrity),
- 신뢰도(reliability) 및
- **타당도(validity)**에 대한 우려도 증가할 것이다.
이에 따라
- 평가 방식의 재설계,
- **사실 회상(fact recall)**보다 **정보 통합 능력(information integration ability)**을 강조하는
‘오픈북(open-book)’ 형태의 시험으로의 패러다임 전환이 필요할 수 있다(A186).
리뷰에 포함된 관점(Perspectives) 논문 개요
(Overview of Perspectives Publications Included in the Review)
본 리뷰에는 총 **87편의 관점 논문(perspectives publications)**이 포함되었으며, Supplementary Table 3에서 P1–P87로 라벨링되었다. 이들 문헌은 논평(commentaries), 사설(editorials), 독자 서한(letters to the editor) 등으로 구성되어 있으며, **의학교육에서 AI 활용에 대한 의견, 제언, 혹은 실제적 활용 사례의 가능성(use cases)**을 제시하고 있다.
연구진은 이들 문헌을 **주된 내용(primary content)**에 따라 다음의 다섯 가지 범주로 분류하였다:
- 의학교육에 AI를 통합해야 하는 당위성에 관한 일반 논의 – 42편
- AI의 교육적 응용 및 개발 제안 – 18편
- AI 기반 교육과정 개발 프레임워크 – 8편
- 교육과정 내용, AI 역량, 활용 자원에 대한 제안 – 15편
- AI 윤리 관련 고려사항 – 4편
또한 일부 문헌은 **보조 주제(secondary content)**로 다른 범주와도 중복되는 내용을 포함하고 있다. (자세한 내용은 Supplementary Table 3 및 Supplementary Appendix 2 참고)
의학교육에 AI를 통합해야 하는 중요성
(Importance of Integrating AI into Medical Education)
다수의 관점 논문에서는 AI를 의학교육에 통합하는 것이 미래 의사들이 임상에서 AI를 효과적으로 활용하도록 준비시키기 위해 필수적이라고 주장하였다(P50, P52–53, P60, P65–67, P70, P79). AI는 이미 **진단 및 치료 결정(diagnosis and treatment decisions)**에 영향을 미치고 있으며, 의대생과 레지던트들이 의료 시스템에서 AI 도구를 적절히 사용할 준비가 되어 있어야 한다는 것이다. 또한, 일부 논문에서는 AI가 교수-학습(teaching and learning)(P55–56, P58–59, P61, P64, P69, P71, P84–86)이나 평가(assessment)(P48, P81)를 향상시키는 도구로서의 가능성을 강조하였다.
두 편의 논문은 의학교육자에게
- AI의 영향,
- 윤리적 및 법적 고려사항에 대한 교육을 포함시킬 것을 제안하였다(P57, P87).
반면 몇몇 논문은
- AI가 임상 학습을 제한하거나 왜곡할 가능성에 대한 우려를 제기하였다(P46, P49, P54, P63, P72–73, P82).
기타 관점 논문들은 AI의 활용 가능성에 대한 일반적인 견해를 공유하였다(P47, P49, P51, P54, P62, P68, P74–78, P80, P82–83).
교육적 활용 사례 및 개발 아이디어 제안
(Specific Suggestions for Educational Applications and Ideas for Development)
총 18편의 관점 논문에서는 AI 도구를 활용한 구체적인 교육적 적용 방안을 다음과 같이 제시하였다:
- 지능형 튜터링 시스템(Intelligent Tutoring Systems, ITSs):
- 의사결정 능력 향상을 위한 개인 맞춤형 학습 경험 제공(P5)
- AI 기반 학습자 평가:
- **잠재 의미 분석(Latent Semantic Analysis)**을 활용한 임상 케이스 요약 평가 및 피드백 제공(P11)
- NLP 기반 임상술기 평가 자동화(P15)
- 챗봇(ChatBot, 예: ChatGPT):
- 의학 문헌 분석을 통한 임상 관리 교육(P10)
- USMLE 및 기타 시험 대비 지원(P12, P17)
- 비판적 사고, 창의성, 환자 의사소통 촉진(P8, P14, P16)
- 개인 맞춤형 학습 플랫폼(Personalized Learning Platforms):
- 학습 경로 설계(P1)
- 개인 맞춤 피드백 제공(P8)
- 로봇 수술 시뮬레이션 (Robot-Assisted Surgery Simulations):
- 가상현실(VR)을 활용한 AI 수술 교육 및 평가(P13)
- 해부학 교육 향상:
- 해부학의 교수, 학습, 평가 전반에서 심화 학습 및 장기 기억 정착 유도(P2)
- AI 도구를 활용한 입학 서류 준비:
- 의대 입학 서류, 레지던시 자기소개서 작성(P6, P18)
- 단, 공정성 확보를 위한 가이드라인 필요성도 제시
- AI 생성 예술(art):
- 환자와의 상호작용을 시각적으로 스토리텔링하는 데 활용(P7)
- 수술 중 영상 분석을 통한 ML 교육:
- 역량 기반 환자 평가 역량 교육(P9)
의학교육 내 AI 활용 프레임워크
(Frameworks for AI in Medical Education)
여러 관점 논문에서는 AI를 의학교육에 통합하기 위한 구조적 틀을 제안하였다:
- AI 리터러시 프레임워크(AI literacy framework):
- 의대 입학, 교육, 평가, 연구 전반에서의 AI 적용 가능성과 영향력 제시(P19)
- 영상의학 교육 프레임워크:
- 개인화 학습 및 의사결정 지원 도구로서의 AI 역할 강조(P20)
- 디지털 기술 교육 프레임워크:
- 데이터 보호, 법적 고려사항, 디지털 커뮤니케이션, 데이터 분석 역량 등 포함(P21)
- 사례 기반(case-based) UME 교육 프레임워크:
- AI 교육 내용을 사례 중심으로 정교하게 구조화(P22)
- AI에 조기 및 점진적으로 노출시키는 프레임워크:
- 학습자의 임상 적응 능력 개발을 위한 분석 계층 제공(P23)
- 의료지식 기반 확장을 위한 프레임워크:
- 보건의료 경제, 규제, 환자진료와 관련된 AI 내용 포함(P24)
- AI 윤리 통합 프레임워크(embedded AI ethics education framework):
- 기존 생명윤리 교육과 통합하여 의료 AI의 윤리적 측면을 교육할 수 있도록 설계(P25)
- ML 기반 교육과정 프레임워크:
- 임상의의 연구 역량, 통계 지식, 임상 역량 향상에 기여하는 ML 교육 구조 제안(P26)
AI 교육과정 내용 및 역량, 도구와 자원에 대한 권고사항
총 **15개의 논의(perspectives)**에서 의료 교육에서 인공지능(AI)을 가르치기 위한 교육과정 개발에 도움을 줄 수 있는 AI 관련 내용, 역량(competency), 그리고 구체적인 도구와 자원에 대한 명시적인 권고를 제시하였다.
권고된 교육 내용에는 다음과 같은 주제가 포함된다:
- AI가 의료 실무를 변화시키는 상황에서, 의사들이 환자의 요구를 충족시키기 위해 알아야 할 사항들 (P31–32),
- 데이터 과학(data science) 및 AI의 기반 개념(P33, P35),
- AI를 활용한 외과적 결과 향상 (P41),
- 안과의사를 위한 외과적 훈련 (P40),
- AI 모델 성능, 경제적 영향, 영상의학에서의 보고서 생성 (P38–39, P37),
- 근거중심의학(evidence-based medicine)을 뒷받침하는 데이터 과학 (P36),
- AI를 활용한 진단 및 예후 예측(diagnostics and prognosis) 기법 (특히 혈액학 분야) (P28),
- 기계 학습(machine learning)의 개념적 기반 (P34),
- 의료에서의 AI 윤리적 활용(ethical uses) (P27) 등이 있었다.
특히 한 출판물에서는 ‘의료 데이터 과학 의사(Doctor in Medical Data Sciences)’라는 새로운 전문 분야의 커리큘럼을 제안하였으며 (P29), 또 다른 출판물은 **1차 진료(primary care)에서의 AI 도구 활용을 위한 6개 역량 영역(six domains of competency)**을 Quintuple Aim의 맥락에서 설명하였다(P30).
AI 교육을 위한 윤리적 고려사항 (Ethics Considerations for AI Education)
총 **14개의 논의(perspectives)**에서는 **AI가 보건의료에 도입되면서 발생하는 윤리적 풍경(ethical landscape)**에 대한 다면적(multi-faceted) 시각을 반영하였다. 이들 중 다수는 AI 응용의 한계에 대한 신중함을 나타냈으며, 의료 교육에서의 AI 활용이 가지는 한계에 대해 **우려(caution)**를 표명하였다. 또한 이 논의들은, 의료 전문가들이 AI로 인한 새로운 도전에 적절히 대응할 수 있는 기술과 자질을 갖추는 것이 중요하며, AI 시대에도 인간의 판단력(human judgment)과 윤리적 사고(ethical reasoning)의 가치는 대체될 수 없다는 점을 강조하였다.
윤리 교육의 중점 분야에 대한 권고 (Recommended Focus for Ethics Education)
여러 관점 논문(perspectives papers)은 의료와 의학교육에서의 AI 활용에 따른 윤리적 문제를 지적하며, 의사들이 그러한 윤리적 도전에 **직면할 책임(responsibility)**이 있다는 점을 논의하였다. 이러한 논문들은, 현재와 미래의 의사들이 이러한 문제를 다룰 준비가 되어야 하며, 우리가 아직 AI의 윤리적 함의(ethical implications)를 충분히 이해하지 못했으며, 이러한 도전에 어떻게 적절히 대응해야 할지에 대한 방법 역시 완전히 갖추지 못했다는 사실을 인정한다.
이 논문들을 종합적으로 고려할 때, 의학교육에서 다루어야 할 주제에 대한 **중요한 통찰(insights)**을 제공하며, 의학교육자들이 커리큘럼에 포함해야 할 윤리적 이슈에 대한 명확한 지침을 얻는 데 도움이 된다. 이러한 논의에서 제안된 윤리 교육의 핵심 주제는 Figure 3에 요약되어 있다. (→ 그림 내용이 이어진다면 다음 부분에서 추가로 번역하겠습니다)

윤리 교육의 중점 주제들 (계속)
- 알고리즘 편향과 형평성 (Algorithmic Bias and Equity): 미래의 임상의들은 특히 대표성이 부족한(non-representative) 데이터셋에 기반한 학습으로 인해 발생하는 **보건의료 AI의 편향(bias)**을 이해해야 한다(P42). AI 커리큘럼을 통해, 의사들은 자신의 전제(assumption)와 임상 실무 및 AI 시스템에 내재한 편향을 **비판적으로 성찰(critical reflection)**할 수 있으며, 이는 AI의 출력 결과를 더 잘 해석하고 현재 의학 지식의 한계를 인식하는 데 도움이 된다(P22).
- 자원 배분(Resource Allocation): AI는 보건의료 내 **공정한 자원 배분(just resource allocation)**과 형평성(equity) 문제를 전면에 드러내며, 학생들에게 **정의로운 의료 정의(healthcare justice)**를 위해 AI가 어떻게 설계되고 사용되어야 하는지 고민하게 만든다(P42).
- 안전 및 품질 보장(Safety and Quality Assurance): AI의 책임 있는 사용을 위해, **의료 전문가 간의 합의(consensus)**가 필요하다. 이는 의사로서 **안전하고 효과적으로 진료할 의무(professional obligation)**와도 연관된다(P25). 임상 실무에 AI가 통합되면서, 학생들은 AI 안전성에 대한 규제 노력(regulatory efforts), 그 한계, 그리고 윤리적 함의를 이해해야 한다(P42).
- 인간 상호작용과 공감적 돌봄(Human Interaction and Compassionate Care): AI 기반 윤리 교육은 전통적 방식에 비해 학생들의 **공감(compassion)**을 함양하는 데 덜 효과적일 수 있다. 한 출판물은 공감은 가르칠 수 있으며, 의학교육에서의 **긍정적인 역할 모델(role model)**이 학생들의 공감적 실천에 대한 이해를 심화시킬 수 있다고 주장하였다(P44).
- 데이터 프라이버시 및 보안(Data Privacy and Security): 의료에서 AI를 활용하려면, 환자 데이터에 대한 윤리적 처리와 법적 측면에 대한 깊은 이해가 필요하다(P42, P43). 사용 가능한 데이터셋이 방대해지고 AI의 능력이 향상됨에 따라, 데이터 비식별화 해제(de-anonymization) 또는 재식별(reidentification) 가능성이 높아지고 있으며, 이는 다른 데이터와의 **교차 참조(cross-referencing)**를 통해 이루어질 수 있다(P43).
- 자동화 편향 및 임상기술 보존(Automation Bias and Skill Preservation): AI에 대한 **과도한 신뢰(undue reliance)**로 인한 **자동화 편향(automation bias)**은 오류를 초래할 수 있으므로, 균형 잡힌 신뢰와 회의적 시각이 요구된다(P25).
윤리 교육은 AI가 의사의 역할을 대체하는 것이 아니라 보완해야 함을 강조해야 하며, 교육은 AI가 대체할 수 없는 임상 기술과 인간 상호작용을 유지하는 데 중점을 두어야 한다(P42). 또한, 하이브리드 인텔리전스(hybrid intelligence) 시스템을 활용하여 **환자-의료진 간의 치료적 관계(therapeutic relationship)**와 **공감(empathy)**을 강화할 수 있도록 해야 한다(P44). - 투명성과 설명된 동의(Transparency and Informed Consent): 건강 AI의 사용은 설명된 동의(informed consent) 및 AI가 진료 결정에 어떤 식으로 개입하는지를 환자에게 알릴 의무에 대한 핵심적인 질문을 제기한다(P42). **의료 AI에 대한 숙련도(proficiency)**는 **윤리적 역량(ethical competency)**과 불가분의 관계에 있으며, 윤리적 고려는 임상 결정에 영향을 미치고, 반대로 임상 결정도 윤리적 사고에 영향을 준다. 미래의 의사들은 AI의 잠재적 결과를 인식하고, 이를 윤리 원칙에 비추어 환자와 논의할 수 있는 능력을 배양해야 한다(P25). 의학교육에서는 학생들이 자신의 데이터가 어떻게 수집되고, 동의는 어떤 의미를 가지며, 그 범위가 어디까지인지를 명확히 이해하도록 해야 한다(P43).
윤리 교육을 위한 제안된 교육적 접근법 (Proposed Educational Approaches for Ethics Education)
AI 윤리 교육을 위한 한 가지 권장 접근법은, 실제 사례(real-life case studies)를 의학교육 커리큘럼에 포함시키는 것이다. 이 방법은 설명된 동의(informed consent), 편향(bias), 투명성(transparency) 등 **보건의료 AI가 제기하는 다면적인 윤리 문제(multifaceted ethical issues)**를 구체적으로 보여줄 수 있다(P42). 이러한 사례 기반(case-based) 방법론은 이론적 이해를 풍부하게 하는 동시에, 학생들의 **실천적 의사결정 능력(practical decision-making skills)**을 연마하는 데 도움을 준다.
또 하나의 접근법은 **‘내재된 AI 윤리 교육 프레임워크(Embedded AI Ethics Education Framework)’**를 적용하는 것이다. 이 접근법은 기존의 의료 윤리 수업 내에서 AI 윤리 교육을 점진적으로 통합하는 방식으로, 기술 오남용으로 인한 잠재적 해악(potential harms)을 다루고, 환자 진료의 핵심이라 할 수 있는 **위험-이익 분석(risk-benefit analysis)**을 수행할 수 있도록 학생들을 준비시킨다(P25).
세 번째 접근법은 현재 임상 현장에서 실제로 사용되고 있는 AI 시나리오를 학습 사례로 활용하여, 학생들이 AI의 기술적 측면과 윤리적 함의를 함께 비판적으로 평가할 수 있도록 준비시키는 것이다(P22). 이 접근법은 **비판적 성찰(critical reflection)**을 촉진하고, 환자 중심 진료(patient-centered care)에서 AI를 활용하기 위해 필요한 **학제 간 대화(interdisciplinary dialogue)**를 장려한다.
또 다른 접근법은, 전통적인 의학교육에서 **윤리 교육을 사람 중심(human-led)**으로 진행해온 것처럼, AI의 한계(limitations)를 강조하면서 인간 중심의 윤리 교육을 유지하는 것이다. 이 방식은 기술에 대한 의존보다는 인간의 상호작용(human interaction)과 도덕적 추론(moral reasoning)의 함양에 초점을 맞추며, 동시에 인간과 기계가 서로 배우며 윤리적 의사결정에서 더 나은 성과를 낼 수 있는 ‘하이브리드 인텔리전스(hybrid intelligence)’ 시스템의 가능성도 열어둔다. 이러한 다양한 교육 전략들을 종합해보면, 보건의료와 보건전문직 교육에서 AI가 가져온 복잡성(complexity)을 극복하기 위해, 의료 전문직 종사자들이 기술적 능력(technical skill)과 윤리적 식별력(ethical discernment)을 모두 갖추는 것이 필수적임을 강조하고 있다.
Discussion
본 리뷰는 의학교육 영역에서 인공지능(AI)에 대한 폭발적인 관심의 확산을, 출판된 문헌들을 통해 조망하려는 여정을 시작하였다.
**논문 및 관점(perspectives) 문헌에 대한 상세한 표, 요약 인포그래픽, 관련 설명 서술(narrative)**은 현재 근거의 상태를 명확하게 보여준다.
AI에 대한 최초의 의학교육 관련 연구는 1992년으로 거슬러 올라가며, 이는 실제 AI가 개발된 시점보다 훨씬 후의 일이지만, 이후 지속적인 출판물 증가는 AI에 대한 끊임없는 흥미와 꾸준한 진화를 보여준다. 최근의 출판 급증은 처음에는 해당 분야의 성숙과 함께 발생한 자연스러운 성장으로 보일 수 있으나, 우리의 분석에 따르면 이는 ChatGPT의 공개 출시와 직접적인 관련이 있는 동시대적(contemporaneous) 반응으로 보인다.
최근 AI 기술의 발전은 전 세계적으로 접근 가능하고 비용 효율적인 AI 도구들이 빠르게, 광범위하게, 그리고 사실상 한계 없이 확산되는 결과를 낳았다. 이러한 **기술의 민주화(technological democratization)**는 출판물의 출신 지역 다양성에서도 나타나며, 약 3분의 1이 북미 또는 유럽의 전통적 학문 중심지를 벗어난 지역에서 출판되었는데, 이는 최근의 대부분 BEME 리뷰보다 높은 수치이다¹²³⁴.
이 리뷰는 중앙집중적(centralized) 관점에서 분산(distributed)된 관점으로의 전환을 반영하며, AI가 전 세계 의학교육을 어떻게 변화시키고 있는지를 보다 포괄적이고 통합적인 시각으로 이해하게 해준다. 이 **스코핑 리뷰(scoping review)**는 AI의 의학교육 내 여정을 그려나가면서, 단순히 근거의 증감만이 아니라 교육 환경 전반에 스며든 광범위한 변화를 드러낸다.
이러한 **전반적 환경 수준에서의 변화(impact at such a broad environmental level)**를 고려할 때, 본 분석은 **Oberg의 문화 충격 이론(culture shock theory)**의 네 단계, 즉 **허니문(Honeymoon), 좌절(Frustration), 적응(Adaptation), 수용(Acceptance)**과 잘 맞아떨어진다¹². 각 단계는 AI 통합에 대한 감정적, 심리적, 행동적 반응을 개인 및 영역에 따라 다양하게 나타나는 방식으로 표현한다.
- ‘허니문(Honeymoon)’ 단계는 **매혹(fascination)**과 **이상주의(idealism)**가 혼합된 상태로, 주로 **관점 논문(perspective articles)**이나 **혁신 사례 논문(innovation pieces)**에서 나타난다. 이들 논문은 전문가들에 의해 작성된 경우가 많으며, 의미 있는 통찰(insight), 유용한 자원(resources), 그리고 향후 발전 방향에 대한 기초를 제공한다.
하지만 이들은 종종 AI의 잠재력에 대해 과도하게 낙관적이며, 윤리적 고려와 도전 과제에 대한 탐색이 부족한 경향이 있다. - ‘좌절(Frustration)’ 단계에서는 AI에 대해 압도당한 느낌(feeling overwhelmed), 이해 부족에 대한 두려움(fear), **방향 상실감 및 소외감(feeling lost and out of place)**이 나타난다. 이러한 반응은 충분히 타당하며, AI라는 시스템 충격(shock)에 적응하기 위한 필연적인 단계로 이해할 수 있다. 특히 AI의 구체적 응용에 따른 윤리적 고려와 도전 과제는 반드시 고려되어야 하며, **지속가능한 도입(sustainable implementation)**을 위해서는 이들 간의 균형이 중요하다.
- **NLP, 특히 ChatGPT를 의학시험에서 활용한 연구들[A160–191]**에서는, 많은 논문들이 **양가적 태도(ambivalence)**를 보였다. 이는 문화 적응(cultural adaptation)의 비선형적(nonlinear)이며 개인적인 성격을 반영하며, 허니문과 좌절 단계를 동시에 경험하는 듯한 모습—**AI의 능력에 대한 경이로움(awe)**과 **기존 의학교육 방식이 필요 없어질지도 모른다는 우려(apprehension)**가 공존한다. 우리는 이 논문들을 단순한 사례로 언급하는 것이 아니라, 혁신적이거나 새로운 관점을 제시하지 않는다면, 이와 유사한 추가 연구는 더 이상 정당화되기 어렵다는 점을 강조하고자 한다.
- AI 통합에 따른 초기 좌절과 도전이 명확히 인식되기 시작하면, ‘적응(Adaptation)’ 단계로 전환된다. 이 단계에서는 교육자들이 실용적이고 효과적인 방식으로 AI 도구를 도입하기 시작한다. 이 시기는 AI에 대한 경외감이나 회의에서 벗어나, **보다 균형 잡힌 현실적 통합(balanced and functional integration)**으로 전환되는 시기이며, AI의 **실제 활용 사례(use cases)**가 등장하는 것이 특징이다. 그러나 관점 논문에서는 이러한 사례들에 대한 논의가 종종 **장기적 이해나 반복적 탐구(longitudinal or iterative understanding)**를 결여하고 있다는 점도 지적할 필요가 있다. 이는 효과적인 통합을 위해 매우 중요한 요소이다.
- 마지막 단계인 ‘수용(Acceptance)’ 단계에서는 교육자들이 AI와 맺는 관계가 **단순한 적응(adaptation)**을 넘어, 진정한 통합과 편안함의 상태로 **변모(transformation)**하는 모습을 볼 수 있다. 이 단계는 AI가 더 이상 외부의 혼란을 주는(disruptive) 요소가 아니라, **교육 설계의 필수 구성 요소(integral part of the educational blueprint)**로 받아들여지는 전환의 지점을 의미한다. 이 단계에 해당하는 일부 출판물은, AI에 대한 **깊은 이해(deep understanding)**와 **숙련된 활용(skillful utilization)**을 보여주며, AI 기술을 **교육 개발 전반에 걸쳐 창의성(creativity), 비판적 사고(critical thinking), 미래지향적 시각(forward-looking perspective)**과 함께 자연스럽게 통합하고 있다. 이러한 **성숙한 수용의 단계(mature phase of acceptance)**는 단순히 AI 도입의 충격(shock)에서 회복하는 것을 넘어서, **기술을 능동적이고 사려 깊게 수용하는 태도(proactive, thoughtful embrace)**를 상징한다. 이 단계의 교육자들은 **진정한 의미의 선구자(pioneers)**가 되어, AI가 의학교육에 **조화롭고 혁신적으로 통합될 수 있는 기준(benchmark)**을 제시하며, 그들의 경험과 실천은 넓은 교육 공동체에 **귀중한 통찰(insight)**을 제공한다. 이들은 **불안(apprehension)에서 수용(acceptance)**으로 나아가는 여정에서, 기술 수용뿐 아니라 개인적·전문적 성장의 여정을 함께 보여준다.
우리가 데이터를 추출하고 도식화하는 과정에서, 연구 보고 방식에 있어 **중대한 공백(critical gaps)**을 확인할 수 있었다. AI가 의학교육에 적용되는 과정에서의 ‘나침반(compass)’ 역할을 할 체계적인 틀이 필요하다는 것이다. 이러한 간극을 해소하기 위해서는 교육 맥락, 단계, AI 기술 등 서로 분절된 요소를 단순히 나열하는 수준을 넘어, **보급(dissemination), 재현(replication), 혁신(innovation)**을 지원하는 **포괄적 프레임워크(comprehensive framework)**가 요구된다. 이에 저자들은 FACETS 프레임워크를 제안한다(도표 Figure 4 참조).

이 구조화된 접근은 향후 AI 연구에 있어 다음의 핵심 요소들에 중점을 둔다:
- 형태(Form)
- 활용 사례(Use Case)
- 맥락(Context)
- 교육 형태(Education Form)
- 기술(Technology)
- 기술 통합을 위한 SAMR 프레임워크
본 리뷰는 이 요소들이 대부분의 문헌에서 개별적으로는 보고되고 있으나, 단일 논문 내에서 통합적으로 보고된 경우는 드물다는 점을 지적한다. 이러한 분절된 요소들을 체계적이고 통합된 방식으로 결합하는 것은, 의학교육자 및 연구자 모두에게 AI 기술이 어떻게 사용되고 있는지, 기존 실천과의 연계는 어떠한지, 그리고 교육 맥락에 어떻게 통합될 수 있는지를 설명하는 데 매우 유용하다.
FACETS는 단순히 연구자가 자신의 논문을 구상하는 데 도움이 되는 틀일 뿐 아니라, 독자가 AI의 전체적 범위와 영향력을 파악하는 데에도 도움이 되도록 설계되었다. 이는 이 분야의 이해와 혁신을 진전시키는 데 필수적인 접근이며, 향후 연구에 대한 **저자 팀의 핵심적인 권고사항(core recommendation)**이기도 하다.
이 프레임워크는 **관점 논문(perspective pieces)**이나 **태도 조사(attitude surveys)**에는 적용되지 않을 수 있으나, AI 활용 사례나 보다 광범위한 혁신에 대해 보고한 논문의 저자들이 이를 활용한다면 상당한 이점을 제공할 수 있다. FACETS 프레임워크는 연구 간의 수렴 지점을 식별하고, **보다 초점을 맞춘 후속 종합 연구(focused syntheses)**를 위한 유용한 안내자가 될 수 있다.
본 리뷰는 철저하고(rigorous), 체계적이며(systematic), 광범위한(wide-ranging) 작업으로, 스코핑 리뷰(scoping review)의 전통에 충실하게 부합하는 방식으로 수행되었다. 따라서, 향후 추가적인 스코핑 리뷰는 필요하지 않다고 판단된다.
그러나 **현재의 폭발적 연구 생산 속도(velocity of output)**를 고려할 때, 입학(admissions), 교수(teaching), 평가(assessment), 임상 추론(clinical reasoning) 영역에서는 곧 **보다 심층적인 체계적 문헌고찰(systematic reviews)**이 필요해질 것이다. 또한 본 리뷰의 범위를 벗어나 있어 다루지 않았지만, 의학교육 연구에서 AI 활용이라는 또 다른 영역도 체계적 문헌고찰이 필요할 수 있다. **교육기관이 보유한 방대한 빅데이터(big data)**의 **미개척 가능성(untapped potential)**을 고려할 때, 이는 추가 연구가 절실히 요구되는 핵심 분야임이 분명하다.
한계점 (Limitations)
이 리뷰의 한계는 스코핑 리뷰의 본질적 한계에서 비롯된다. 스코핑 리뷰는 본질적으로 근거의 종합(synthesis)을 목표로 하지 않는다는 점에서 제한이 있다(Levac et al., 2010)¹. 또한, 연구를 **범주화하는 과정에서의 주관성(subjectivity)**도 한계로 작용한다. 예를 들어 일부 연구는 **교수(teaching)**와 평가(assessment) 두 영역 모두에 해당될 수 있다. 아울러, 용어의 **일관성 부족(inconsistent terminology)**도 문제로 지적되는데, 이는 의학교육 내 빠르게 발전하는 AI 분야의 복잡성을 여실히 보여준다.
AI 관련 문헌의 범위가 방대하고 계속 진화하는 특성상, 본 리뷰는 **초기 단계에서 검색 전략을 여러 차례 반복(iterated the search)**하였지만, 그럼에도 불구하고 일부 연구가 누락되었을 가능성은 존재한다. 이는 체계적이고 엄격한 방법론을 사용했음에도 불구하고 발생할 수 있는 현실적 한계이다.
또한 본 리뷰는 BEME 리뷰로서는 **비정통적(unconventional)**이지만, 다양한 시각 제공을 위해 perspective article을 포함하였다. 그러나 이러한 포함은 일부에게는 리뷰의 경험적 강도(empirical strength)를 희석시키는 것으로 인식될 수 있다. 이에 따라, 본 연구팀은 이들 관점 논문을 **별도의 병렬 데이터 집합(parallel data set)**으로 구분하여 투명하게 제시하기로 결정하였다. 이는 이 논문들이 무엇을 제공하고 무엇을 제공하지 않는지를 명확히 밝히는 데 큰 가치가 있었기 때문이다.
한편, 본 리뷰는 **Arksey & O’Malley의 스코핑 리뷰 프레임워크의 여섯 번째 단계(외부 전문가 자문)**를 수행하지 않았다. 저자 팀 내에 AI 및 교육 전문가가 포함되어 있어 해당 역할을 수행했다고 판단했지만, 이 과정을 생략한 점은 한계로 간주될 수 있다.
실천 및 정책에 대한 함의 (Implications for Practice and Policy)
이 리뷰는 AI가 의학교육에서 갖는 **변혁적 역할(transformative role)**을 강조하며, AI를 교육과정 개발(curriculum development), 교수법(teaching methodologies), 학습자 평가(learner assessment) 등 여러 측면에 **통합(integration)**시켜야 할 필요성을 제기한다.
이는 기존의 역량 프레임워크를 업데이트하고, 의학교육에서의 AI 활용에 대한 표준화된 가이드라인을 수립할 필요성을 의미한다. 또한, **교육자, 정책 결정자, AI 개발자 간의 협력(collaborative efforts)**이 강조되며, 이를 통해 **형평성(equity)**과 접근성(accessibility) 문제를 해결하고, 편향 없는 AI 도구의 보편적 이용을 보장할 수 있어야 한다.
AI에 대한 초기 흥미에서 **실질적 채택(profound adoption)**으로 나아가기 위해서는 **지속적인 자원 및 시간 투자(continuous investment in resources and time)**가 필수적이다. 아울러, AI 사용에 따른 윤리적 문제와 오남용의 위험을 관리하는 것 역시 매우 중요하다. 무엇보다도, AI를 통해 새로운 통찰과 효율성을 얻더라도, 보건의료에서의 인간 요소(human element)는 결코 대체되어서는 안 된다는 점이 핵심이다.
**윤리 교육(ethical education)**은 필수적이며, AI가 의료제공자의 역할을 대체하는 것이 아니라 보완(enhance)해야 함을 보장해야 한다. 이는 환자-의료진 관계(patient-provider relationship), 공감(empathy), 그리고 **환자의 자율성(respect for patient autonomy)**을 지키는 데도 필수적이다. 이러한 접근은 **의료의 탈인간화(dehumanization)**를 방지하고, 의료전문직의 핵심 가치와 인간적 기술을 강화하는 방식으로 AI가 활용되도록 만든다.
미래 연구에 대한 함의 (Implications for Future Research)
본 리뷰는 향후 연구 및 교육 개발을 위한 핵심 영역을 다음과 같이 제시한다:
- **AI가 의학교육 전반 및 특정 학습성과에 미치는 장기적 영향(long-term impact)**에 대한 **포괄적 연구(comprehensive studies)**의 필요성
- 자동화 편향(automation bias), 과소·과대기능화(over-/under-skilling), 불균형 심화(disparity exacerbation),
그리고 **핵심 임상기술의 보존(preservation of essential clinical skills)**과 같은 AI 관련 위험요소에 대한 연구 - 향후 AI 관련 연구에서 FACETS 프레임워크의 활용 권장
이와 같은 포괄적 접근을 통해, AI는 윤리적으로 타당하며(ethically sound), 교육적으로 효과적이고, 위험성과 도전과제를 충분히 인식한 채로 의학교육에 통합될 수 있을 것이다.
결론 (Conclusions)
본 리뷰가 그려낸 의학교육 내 AI의 지형은, 단계, 전문 분야, 목적, 활용 사례에 이르기까지 매우 광범위하며, 그 대부분은 아직 **초기 적응 단계(early adaptation phase)**에 머물러 있다. **장기적이고 구조적인 변화(longitudinal or deep change)**를 보여주는 사례는 극히 일부에 불과하다. 이에 본 리뷰의 핵심 성과 중 하나는 FACETS 프레임워크로, 향후 연구와 실천을 위한 **체계적 접근법(structured approach)**을 제공한다는 점에서 의미가 크다. 현재로서는 즉각적인 체계적 문헌고찰(systematic review)의 필요성이 뚜렷이 나타나지는 않지만, AI의 **동적 특성(dynamic nature)**을 고려할 때, **지속적인 감시(vigilance)와 유연한 대응(adaptability)**이 필요하다는 점은 명백하다.
'논문 읽기 (with AI)' 카테고리의 다른 글
| 델파이 연구를 활용한 캐나다 인공지능 의료 커리큘럼 개발 (NPJ Digit Med. 2024) (0) | 2025.04.12 |
|---|---|
| 의학과 사회의 가교 역할-의사-사회과학자 파이프라인 확대의 필요성 (JAMA, 2025) (0) | 2025.04.10 |
| 어머니의 이메일 계정을 삭제하며 (JAMA, 2025) (0) | 2025.04.10 |
| 의학교육의 디지털 건강 역량 프레임워크 델파이 연구에 기반한 국제적 합의 성명서 (JAMA Network Open, 2025) (0) | 2025.04.10 |
| 인공지능을 활용한 미래형 의과대학 구축 (JAMA, 2025) (1) | 2025.04.10 |