Educational Strategies for Clinical Supervision of Artificial Intelligence Use
🤖 "AI 의사"의 시대, 당신은 '사이보그'인가 '켄타우로스'인가?
안녕하세요! 🩺 여러분은 요즘 가장 핫한 주제인 '의료 인공지능(Medical AI)'에 대해 어떻게 생각하시나요? 특히 ChatGPT 같은 LLMs (대규모 언어 모델, Large Language Models)가 등장하면서, 의학 교육과 임상 현장은 말 그대로 격변의 시기를 맞이하고 있습니다.
환자를 진료하던 레지던트가 몰래 스마트폰으로 ChatGPT에게 "이 환자 증상이 뭘까요?"라고 물어보는 상상, 이제는 현실이 되었죠. (논문의 그림 1이 딱 이 장면을 묘사하고 있습니다!)
이게 과연 괜찮은 걸까요? 의사들이 더 효율적으로 일하게 되는 걸까요? 아니면... 스스로 생각하는 능력을 잃어버리게 되는 걸까요?
오늘 소개해 드릴 저명한 의학 저널 NEJM (New England Journal of Medicine)에 실린 한 논문은 바로 이 위험하고도 매력적인 질문에 대해 아주 흥미로운 해답을 제시합니다.
⚠️ AI가 가져온 3가지 그림자: 탈숙련, 미숙련, 오숙련
우리는 AI에게 일을 맡기는 것, 즉 '인지적 부담 전가(Cognitive off-loading)'에 익숙해지고 있습니다. 간단한 계산이나 정보 검색은 편하지만, 이게 '임상 추론'처럼 복잡한 영역으로 넘어가면 심각한 문제가 생길 수 있습니다.
논문은 AI에 대한 맹목적인 의존이 3가지 위험을 초래한다고 경고합니다.
- 탈숙련 (Deskilling): 😥 이미 가지고 있던 임상 기술을 AI에 의존하다가 잃어버리는 현상.
- 미숙련 (Never-skilling): 😟 AI가 다 해주니까, 애초에 필수적인 임상 기술을 배울 기회조차 갖지 못하는 현상.
- 오숙련 (Mis-skilling): 🤯 AI가 틀린 정보나 편향된 답을 줬는데, 그걸 비판 없이 수용해서 잘못된 방식이 몸에 굳어지는 현상.
연구진은 이 문제의 심각성을 이렇게 표현했습니다.
"의학 교육(medical training)에서 AI를 사용하면, 매우 효율적이지만 AI 이전 시대의 전문가들보다 독립적인 문제 해결 및 비판적 평가(critical evaluation) 능력이 떨어지는 전문가를 초래할 수 있습니다."
(Original Text: "the use of AI in medical training could result in professionals who are highly efficient yet less capable of independent problem solving and critical evaluation than their pre-AI counterparts.")
생각만 해도 조금 아찔하죠? 🤖
💡 해답은 '적응적 실천'과 '비판적 사고'
그렇다고 AI를 무조건 금지해야 할까요? 논문은 절대 아니라고 말합니다. AI는 이미 강력한 도구이며, 문제는 '어떻게' 사용하느냐에 달려있습니다. 연구진이 제시하는 핵심 능력은 바로 '적응적 실천(Adaptive practice)'입니다. 이는 효율적인 일상 업무(자동적 실천)와 새롭고 불확실한 문제에 직면했을 때 유연하게 대처하는 혁신적 사고(적응적 실천) 사이를 자유롭게 오가는 능력을 말합니다.
그리고 이 '적응적 실천'을 가능하게 하는 무기가 바로 '비판적 사고(Critical thinking)'입니다.
"비판적 사고는 불확실성(uncertainty)에 직면했을 때 적응적 실천의 기초가 되는 구조화된 인지적 도구 집합입니다."
(Original Text: "Critical thinking is the structured cognitive tool set that underlies adaptive practice in the face of uncertainty.")
AI가 아무리 그럴듯한 답을 내놓아도, 그 답이 '추적할 수 없는 블랙박스(untraceable black box)'에서 나왔다는 사실을 인지하는 것, 그것이 비판적 사고의 시작입니다. 연구진은 우리가 AI의 답을 받아들이는 순간을 '맹목적 신뢰(Leap of faith)'라고 표현하며, 이 순간을 인식하는 것이 중요하다고 말합니다.
"AI 상호작용은... 이 판단을 추적할 수 없을(this judgement cannot be traced) 때로 정의되며, 이는 사용자가 AI 결과물을 신뢰하기 위해 '맹목적 신뢰(leap of faith)'를 고려하도록 유도합니다."
(Original Text: "An AI interaction is defined as a moment when... this judgement cannot be traced, which prompts the user to consider taking a leap of faith to trust the AI output.")
🐎 당신은 '사이보그'인가, '켄타우로스'인가?
자, 그럼 이 '비판적 사고'를 가지고 AI를 어떻게 활용해야 할까요? 논문은 두 가지 매우 흥미로운 협업 모델을 제시합니다. (그림 4 참조)
🦾 1. 사이보그 (Cyborg) 모델
- 특징: 인간과 AI가 긴밀하게 얽혀(tightly intertwine) 모든 작업 단계에서 협업합니다. AI와 거의 한 몸이 되어 일하는 방식이죠.
- 적합한 과제: 위험도가 낮거나(Low-risk), 창의적이거나, 잘 검증된 과제 (예: 이메일 초안 작성, 일반적인 학습 계획 짜기)
- 장점: 매우 효율적이고 강력합니다.
- 단점: '자동화 편향(Automation bias)'에 빠지기 쉬워, 자칫 AI의 오류를 놓치고 '탈숙련'이나 '오숙련'으로 이어질 수 있습니다.
🐎 2. 켄타우로스 (Centaur) 모델
- 특징: 신화 속의 반인반마(켄타우로스)처럼, 인간(머리)과 AI(다리)가 작업을 전략적으로 분할(strategically divide)합니다. 인간의 판단이 항상 AI보다 우위에 있으며, AI는 작업을 위임받는 '도구' 역할을 합니다.
- 적합한 과제: 위험도가 높거나(High-stakes), 불확실하거나, AI가 검증되지 않은 과제 (예: 환자 감별 진단, 복잡한 임상 의사결정)
- 장점: 인간의 '비판적 사고'가 중심이 되어 AI의 오류를 걸러내고, 안전성을 극대화합니다.
- 단점: '사이보그' 모델보다 시간과 노력이 더 들 수 있습니다.
의료 현장에서는 어떨까요? 환자의 생명과 직결된 '진단'과 '치료' 같은 고위험(High-stakes) 과제에서는, 우리는 반드시 '켄타우로스'가 되어야 합니다. AI의 제안을 받더라도, 최종 결정은 인간 의사의 비판적 평가와 검증을 거쳐야 한다는 뜻이죠!
🎓 교육자는 무엇을 해야 하는가? (DEFT-AI 프레임워크)
이 논문은 특히 의학 교육자(교수, 지도교수)의 역할을 강조합니다. 학생이 AI를 쓴다고 무조건 혼내는 것이 아니라, 그 순간을 '비판적 사고'를 가르칠 교육적 기회로 삼아야 한다고 말이죠.
이를 위해 DEFT-AI라는 멋진 프레임워크를 제안합니다. (그림 3 참조)
- Diagnosis (진단, 토론): "어떤 AI를 썼니? 어떤 프롬프트를 입력했어?"
- Evidence (증거): "그 AI가 내놓은 답을 어떻게, 무슨 근거로 검증(verify)했니?"
- Feedback (피드백): "스스로의 AI 사용법을 평가해보고, 어떻게 개선할 수 있을까?"
- Teaching (교육): "AI의 답은 '검증하고(verify)' 나서 '신뢰(trust)'해야 해. 고위험 상황에선 '켄타우로스'처럼 행동해야 한단다."
🌟 마치며: "검증하고 신뢰하라 (Verify and Trust)"
AI는 의학의 미래를 바꿀 강력한 도구임이 틀림없습니다. 하지만 이 도구에 휘둘릴 것인지, 이 도구를 지배할 것인지는 우리에게 달려있습니다. 연구진의 마지막 메시지는 이 모든 논의를 관통하는 핵심입니다.
"궁극적으로, "검증하고 신뢰하는(verify and trust)" 패러다임을 육성하는 것은 AI가 인간 전문성의 유익한 증강(beneficial augmentation)이 되도록 보장하는 데 매우 중요합니다."
(Original Text: "Ultimately, fostering a 'verify and trust' paradigm is crucial for ensuring that AI is a beneficial augmentation of human expertise.")
'사이보그'의 효율성과 '켄타우로스'의 지혜를 모두 갖춘, AI 시대를 현명하게 헤쳐나가는 우리 모두가 되기를 바랍니다!
인간-컴퓨터 상호작용 (Human–computer interactions)은 수십 년 동안 이루어져 왔지만, 최근 의료 인공지능 (AI)의 기술 발전은 더 효과적이고 잠재적으로 더 위험한 상호작용을 초래했습니다. AI에 대한 과대광고 (hype)는 인터넷 및 전자의무기록 (electronic health record)의 발전과 같은 이전의 기술 혁명을 연상시키지만,1 대규모 언어 모델 (LLMs, large language models)의 등장은 달라 보입니다. LLM은 인간과 유사한 유창함으로 지식 생성과 임상 추론 (clinical reasoning)을 시뮬레이션할 수 있으며, 이는 LLM에 주체성 (agency)과 독립적인 정보 처리의 모습을 부여합니다.2 따라서 AI는 의학 학습과 실무를 근본적으로 변화시킬 (fundamentally alter) 역량을 가지고 있습니다.3,4 다른 전문직에서와 마찬가지로,5 의학 교육 (medical training)에서 AI를 사용하면, 매우 효율적이지만 AI 이전 시대의 전문가들보다 독립적인 문제 해결 및 비판적 평가 (critical evaluation) 능력이 떨어지는 전문가를 초래할 수 있습니다.
이러한 도전은 교육적 기회와 위험을 동시에 제시합니다.
- AI는 시뮬레이션 기반 학습,6 지식 상기 (knowledge recall), 적시 피드백 (just-in-time feedback)7을 강화할 수 있으며, 단순 반복 작업의 인지적 부담 전가 (cognitive off-loading)에 사용될 수 있습니다. 인지적 부담 전가를 통해, 학습자는 작업 기억 (working memory)의 부담을 줄이기 위해 AI에 의존하며, 이는 더 까다로운 작업에 정신적으로 몰입 (mental engagement)하도록 돕는 전략입니다.8
- 그러나 임상 추론 및 의사 결정과 같은 복잡한 작업의 부담을 전가하는 것은 잠재적으로
- 자동화 편향 (automation bias) (자동화된 시스템에 대한 과도한 의존 및 오류 위험),
- "탈숙련 (deskilling)" (이전에 습득한 기술의 상실),
- "미숙련 (never-skilling)" (필수 역량 개발 실패), 그리고
- "오숙련 (mis-skilling)" (AI 오류 또는 편향으로 인한 잘못된 행동의 강화)으로 이어질 수 있습니다.9
- 이러한 위험은 LLM이 예측 불가능한 블랙박스 (unpredictable black boxes)10로 작동하기 때문에 특히 우려됩니다. 즉, LLM은 추론 투명성 (reasoning transparency)이 낮은 확률론적 응답을 생성하므로 신뢰성 (reliability) 평가에 한계가 있습니다. 예를 들어, 한 연구에서는 상급 의대생의 3분의 1 이상이 임상 시나리오에 대한 LLM의 잘못된 답변을 놓쳤습니다.11
AI 생성 결과물의 고유한 가변성 (inherent variability)과 잠재적인 부정확성 (potential inaccuracies)은 숙련된 임상의조차도 AI의 권고에 대해 불확실하게 만들 수 있습니다. 이러한 딜레마는 새로운 것이 아니며, 익숙하지 않은 임상 문제에 직면하는 더 광범위한 도전을 반영합니다. 그러한 순간에는 적응적 실천 (adaptive practice), 즉 효율적이고 익숙하며 정형화된 행동과 혁신적이고 유연한 문제 해결 사이를 유연하게 전환 (shift fluidly)하는 역량이 필요합니다.12 비판적 사고 (Critical thinking)는 불확실성에 직면했을 때 적응적 실천의 기초가 되는 구조화된 인지적 도구 집합입니다. 이는 임상의가 가정을 수면 위로 끌어올리고, 지식 격차와 편향을 인식하며, 오류를 완화 (mitigate errors)하고, 새로운 문제에 적응하며, 새로운 지식을 생성하거나 채택(즉, 학습)하는 데 도움이 되는 자기 성찰 (self-reflection)에 참여하도록 합니다.13,14 따라서 비판적 사고는 AI 시대의 적응적 실천에 필수적 (foundational)입니다.
의학 학습자를 지도하는 임상의(이하 교육자)는 평생의 적응적 실천을 증진하기 위해 비판적 사고를 명시적으로 가르치고 (teach), 평가하며 (assess), 시범 보여야 (model) 합니다. 이해관계자들이 의학교육에 AI를 안전하게 통합하기 위한 시스템 수준의 전략을 개발하고 있지만,15 교육자와 학습자가 AI에 비판적으로 참여 (engage critically)하는 데 필요한 기술을 갖추도록 하는 구조화된 전략의 부재라는 중대한 공백 (critical gap)이 남아있습니다.16 본 종설 (review)에서는 AI가 사용되는 모든 곳에서 수련생의 임상 지도 (clinical supervision) 중에 비판적 사고를 가르치고 평가하기 위해 교육 전략을 활용하는 프레임워크 (framework)를 제안합니다.
배우면서 가르치기(Teaching while Learning)
AI 도구가 교실과 임상 현장에 스며들면서 (permeate), 교육자들은 자신들보다 학습자들이 더 능숙하게 (adept at using) 사용할 수 있는 기술의 사용을 지도하고 있는 자신을 발견하게 됩니다. 이러한 전문성의 역전 (inversion of expertise)은 교수진이 시스템 변화를 동시에 가르치고, 배우며, 실천해야 했던 환자 중심 의료 홈 (patient-centered medical home)의 부상과 같은 의학교육의 초기 변화들과 유사합니다.17 이러한 맥락에서, 교수 개발 (faculty development)은 교육자의 정의를 (AI 문해력 (AI-literate)을 갖춘 학습자와 환자를 포함한) 임상팀의 모든 구성원으로 확장하고, 성찰적이며 팀 기반의 "실천 공동체 (communities of practice)"17를 지원함으로써 공유 학습 모델 (shared learning model)에 기반해야 합니다. 이러한 원칙은 AI 지도 (AI supervision)에 직접 적용됩니다. 교육자는 학습자 주도의 통찰 (learner-led insight)의 순간을 수용하고 AI의 역량과 한계에 대한 공동 탐구 (shared inquiry)를 장려해야 합니다. 그렇게 함으로써 불편함은 불확실성의 공동 관리 (comanagement of uncertainty)18를 위한 기회로 전환되며, 이는 모두를 위한 임상적 사고 (clinical thinking)와 AI 문해력 (AI literacy)을 증진하는 구조화된 교육적 순간을 위한 발판을 마련합니다. 아래에서 설명할 전략들은 단순히 가르치기 위한 도구가 아니라, 교육자 자신이 AI에 대한 이해를 발전시킬 수 있도록 돕는 비계 (scaffolds)이기도 합니다. 이 새로운 지형 (terrain)에서는, 가르치는 사람도 역시 배우는 사람입니다.
주요 포인트: 인공지능 사용의 임상 지도를 위한 교육 전략
- 전문가적 실천 (expert practice)의 발전을 위한 인공지능(AI)의 사용은 전례 없는 기회를 제공하지만, "탈숙련", "미숙련", "오숙련"과 같은 위험도 제기합니다.
- 임상 지도교수는 학습자보다 AI 경험이 적을 수 있습니다. 교수 개발은 AI의 역량과 한계를 공동 탐색 (coexploration)할 수 있는 공유 학습 환경을 수용해야 합니다.
- 효율성과 혁신 사이를 전환하는 적응적 실천 (Adaptive practice)은 AI 기반 학습의 기초입니다. 비판적 사고는 이러한 전환을 지원하며, 반드시 교육되고 시범 보여야 합니다.
- AI 상호작용은 임상의가 완전히 재현할 수 없는 (retrace) 결과물을 받는 순간으로 이어지며, 이는 '맹목적 신뢰 (leap of faith)'를 유발합니다. 이러한 순간을 인식하기 위해 잠시 멈추는 것이 비판적 사고에 필수적입니다.
- DEFT-AI (AI 사용에 대한 진단, 증거, 피드백, 교육 및 권장)는 학습자-AI 상호작용 동안 비판적 사고와 AI 문해력을 증진하기 위한 구조화된 프레임워크입니다.
- 두 가지 AI 사용 행동이 나타납니다: 각 작업에 대해 사용자와 AI가 긴밀하게 얽히는 사이보그 (cyborg)와, 사용자와 AI 간의 작업을 분할하고 비판적 감독 (critical oversight)을 유지하는 켄타우로스 (centaur)입니다. 적응적 AI 실천은 작업의 복잡성과 관련된 위험에 따라 이러한 행동 사이를 전환하는 능력을 필요로 합니다.
의학 학습에서 AI의 약속과 위험(Promises and Perils of AI in Medical Learning)
다음과 같은 가상적이면서도 현실적인 예시를 고려해 보십시오: 진료 세션 중에, 한 의학 레지던트가 환자를 평가한 후 조용히 (discreetly) 스마트폰을 확인하고 LLM에 감별 진단 (differential diagnosis)과 관리 계획 (management plan)을 생성하도록 프롬프트를 입력합니다 (그림 1). 몇 초 안에 AI는 논리 정연하고 (well-reasoned) 설득력 있는 주장을 제시합니다. 학습자는 AI가 생성한 권장 사항을 환자 기록에 삽입합니다. 방 건너편에서 이 상호작용을 지켜보던 교육자는 생각합니다. "이제 어떡하지? 레지던트가 AI에게 어떤 프롬프트를 제공했을까? AI에게 질문을 던지고 있는 걸까, 아니면 제안을 그대로 받아들이고 있는 걸까? 이 AI에게 임상 추론을 맡겨도 (entrusted with) 될까? 내가 개입해야 할까? 그렇다면 어떻게? 이것이 임상 추론의 미래일까?"
그림 1. 학습자의 인공지능(AI) 사용을 목격하는 교육자.
교육자의 마지막 질문은 임상의를 지원하기 위한 AI 사용을 정의하는 것과 관련된 불확실성 (uncertainty)을 강조합니다.19 오늘날 AI 상호작용은 학습자의 일과 시간 내내 발생하고 있습니다. 예를 들어, 심전도(ECG) 판독 전문성 (expertise)이 제한적인 학습자는 흉통 환자의 임상 평가를 수행하기 위해 ECG 기계의 해석에 의존하는 (lean on) 경우가 많습니다.20 기술이 발전함에 따라, 임상의는 영상의학과의 영상 판독 (image interpretation)21,22부터 자동화된 임상 기록 (automated clinical documentation)23에 이르기까지 많은 임상 업무를 AI에 전가 (off-load)할 수 있습니다.
AI에게 임상 추론을 맡길 것인지에 대한 교육자의 질문은 친숙하면서도 시의적절합니다. 임상 의사 결정을 지원하는 이전 세대의 AI 도구들은 인간의 추론을 증강 (augment)하는 데 실패했지만,24 다양한 연구에서 지식 상기,25,26 복잡한 진단적 과제 해결,27-29 확률론적 추론 (probabilistic reasoning),30 관리 추론 (management reasoning),31 및 의사소통32을 포함한 여러 임상 추론 역량에서 LLM의 전문가와 유사한 수행 능력 (expertlike performance)을 입증했습니다. 그러나 보건 의료에 존재하는 기존의 편향을 반영하는 편향된 산물 (biased artifacts)33이 AI 모델 훈련 중에 포함될 가능성이 높으며, 이는 진단의 불평등 (diagnostic inequities)을 영속화 (perpetuate) (그리고 알려줄34) 가능성이 있습니다.35 더욱이, LLM은 환각을 일으키며 (confabulate)36 인간과 유사한 인지 편향 (cognitive biases)을 보입니다.37 따라서 AI가 보조 수단 (adjunct)으로 사용될 수는 있지만, 최종 진단과 치료 계획은 인간의 노력 (human endeavor)으로 남아야 합니다.38,39 우리는 임상 추론에서의 AI 사용에 본 종설의 초점을 맞추는데, 이 영역은 학습자와 그들의 미래 환자에게 높은 위험을 수반하며40 따라서 교육자와 학습자에게 우선순위 (priority)가 되어야 합니다.41
탈숙련 (Deskilling) 및 미숙련 (Never-Skilling)
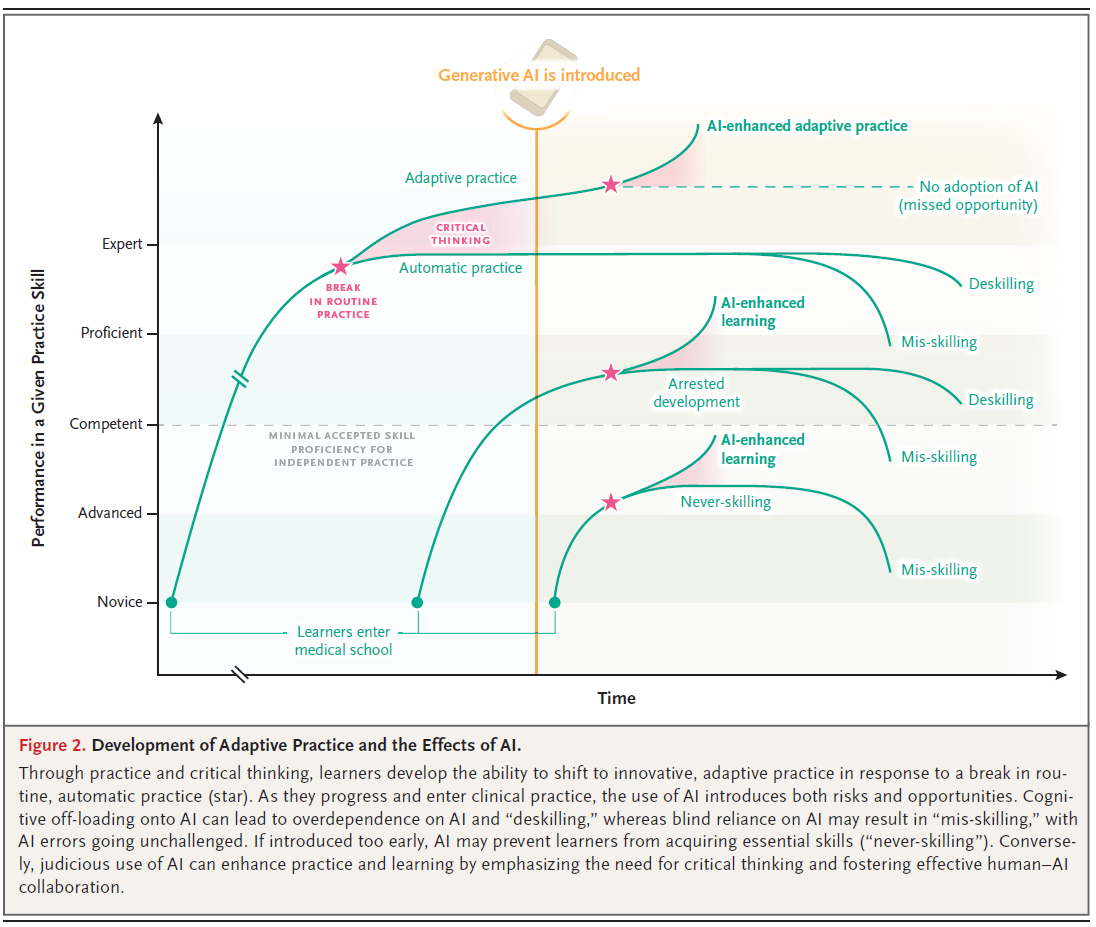
그림 2에서 볼 수 있듯이, AI를 임상 추론을 지원 (informing)하는 대신 임상 추론의 대체재 (substitute)로 사용하는 것(부담 전가, off-loading)은 기술 개발과 관련하여 탈숙련 (deskilling),42 미숙련 (never-skilling),43 및 오숙련 (mis-skilling)이라는 몇 가지 위험을 초래합니다.
- AI에 대한 과도한 의존 (Overreliance)은 웹 검색 사용에서 나타난 바와 같이44 정보 상기 (information recall)를 포함하여 학습자가 막 습득하기 시작한 임상 추론 기술의 상실로 이어질 수 있습니다.
- AI 도구 사용, 인지적 부담 전가, 비판적 사고 능력을 측정한 한 연구에서, 연구자들은 잦은 AI 도구 사용과 비판적 사고 능력 사이에 유의미한 음의 상관관계 (significant negative correlation)가 있음을 발견했으며, 이는 증가된 인지적 부담 전가에 의해 매개 (mediated)되었습니다.45
- AI에 대한 의존도가 높다고 보고한 참가자들은 독립적인 문제 해결 및 분석적 추론 (analytic reasoning)에 대한 참여가 감소한 것으로 나타났는데, 이는 개인의 인지적 노력 (personal cognitive effort)보다는 AI가 생성한 해결책으로 전환되었음을 시사합니다.
- 동일한 연구에 따르면, 젊은 참가자들이 나이 든 참가자들보다 AI 도구에 대한 의존도 (dependence)가 더 높고 비판적 사고 점수가 더 낮았으며,45 이는 AI의 과용 (overuse)이 비판적 사고 능력 개발의 실패를 초래할 수 있음을 시사합니다.
- 이러한 우려는 한 무작위 시험 (randomized trial)에서도 반복되는데, 비판적 검토 (critical scrutiny) 없이 AI 결과물을 맹목적으로 채택한 (blindly adopted) 사용자들은 복잡한 분석 기술을 요구하는 작업에서 AI를 사용하지 않았을 때보다 AI를 사용했을 때 더 저조한 성과를 보였으며,5 이러한 효과는 전반적인 수행 능력이 낮은 사용자들 사이에서 더욱 두드러졌습니다.
- 저자들은 이 결과를 사용자가 자신의 판단을 우회 (bypassing their own judgment)하고 시스템의 결과물에 묵인 (acquiescing)하는 "AI와의 비관여적 상호작용 (unengaged interaction with AI)" 탓으로 돌렸습니다.
그림 2. 적응적 실천의 개발과 AI의 영향.
오숙련 (Mis-Skilling)
오숙련 (Mis-skilling)은 학습자가 부정확하거나 편향된 AI 모델에 특정 추론 작업을 맹목적으로 맡길 (blindly entrust) 때 발생할 수 있습니다.9,33 예를 들어, 노인 환자의 폐렴 가능성을 과대평가하거나 체질량 지수가 높은 환자의 심부전 가능성을 과대평가하는 등 체계적인 편향 (systematic biases)을 가진 AI 생성 진단 예측을 본 임상의는 이러한 부정확한 예측을 채택할 가능성이 더 높았습니다.46 더욱이, AI 지원은 기본 수행 능력이 낮은 (low baseline performance) 임상의에게 불균형적으로 해를 끼쳤습니다.47,48
- 실제로 AI가 임상의보다 뛰어난 성과를 보였을 때, (인간과 AI의) 조합은 AI 단독보다 더 나쁜 성과를 보였습니다. AI 모델의 설명 (AI model explanations)은 이러한 오류를 완화 (mitigate)하는 데 실패했으며,46,47 이는 임상의가 AI 편향을 인식하고 수정할 수 없었고 오숙련이 더욱 강화될 수 있음을 시사합니다. AI의 권고가 올바른 경우에도 이를 무시하는 것은 AI에 대한 과소 의존 (underreliance)과 효과적인 AI 지원 기회의 상실을 의미합니다.
- 반대로, 임상의가 AI보다 뛰어난 성과를 보였을 때, 인간과 AI 추론의 조합은 성과를 향상시켰으며, 이는 높은 기본 수행 능력이 효과적이고 안전한 AI 지원을 촉진함을 시사합니다.47
AI 상호작용 중의 교육 전략(Educational Strategies during AI Interactions)
이러한 위험을 인식하고, 교육 프로그램과 기관들은 의학교육에서 AI 사용 원칙을 수립했으며15 보건 의료에서의 AI 사용을 위한 역량 (competencies)과 커리큘럼을 정의하기 시작했습니다.19,49,50 그러나 교육자들은 즉각적인 (in-the-moment) AI 상호작용 중에 적응적 실천 (adaptive practice)의 발전을 촉진해야 하는 도전에 여전히 직면해 있습니다. 여기에서 우리는 효과적인 임상 기술과 AI 참여의 동시 발전을 위해 교육자가 비판적 사고 (critical thinking)를 시범 보이고 비계 (scaffold)하는 데 사용할 수 있는 학습자-AI 상호작용에 대한 단계적 접근 방식 (stepwise approach)을 제안합니다. 위에서 언급했듯이, 강력한 기초 지식과 기술 (strong foundational knowledge and skills)을 증진하는 것은 AI 사용의 이점을 극대화 (maximizes the benefits)하고 위험을 완화 (mitigates the risk)하며, 우리는 이것이 효과적이고 안전한 AI 상호작용을 위한 모든 프레임워크에서 명시된 목표 (stated goal)가 되어야 한다고 믿습니다. AI 상호작용의 급증 (surge)은 AI 및 임상 문해력 (clinical literacy)을 높이기 위한 교육적 기회로 재구성되어야 (framed as) 합니다.51
AI 상호작용의 정의(Defining AI Interactions)
"인공 지능"이라는 용어는 학문과 맥락에 따라 다양한 정의를 포함하며 (encompasses), 이는 기술적 (technical), 역량 기반 (capability-based), 관계적 (relational) 정의로 그룹화될 수 있습니다 (NEJM.org에서 본 논문 전문과 함께 제공되는 보충 부록 [Supplementary Appendix]의 표 S1 참조). AI에 대한 이 세 가지 관점 중에서, 레지던트-지도교수 비네트(그림 1)에서 설명된 AI의 관계적 정의 (relational definition)는 의학교육 맥락에서 특히 유용합니다. 이 정의는 AI의 기술적 구성 (technical composition)이나 역량보다는 추론과 실천에 미치는 영향 (effects on reasoning and practice)에 기반합니다.52 AI 상호작용은 "특정한 상호작용의 맥락에서, 컴퓨터 산물 (computational artefact)이 최적의 행동 방침을 알리기 위한 판단 (judgement)을 제공하고... 이 판단을 추적할 수 없을 (cannot be traced) 때"로 정의되며, 이는 사용자가 AI 결과물을 신뢰하기 위해 '맹목적 신뢰 (leap of faith)'를 고려하도록 유도합니다.53 이러한 '맹목적 신뢰'는 어린이가 처음 계산기를 사용할 때나, 진료실에서의 AI의 경우, 의대생이 감별 진단을 위해 생성형 AI에 프롬프트를 입력할 때 흔히 발생합니다. AI의 관계적 정의는 AI가 어떻게 작업을 수행하는지에 대한 기술적 세부 사항과는 무관합니다 (independent of). 따라서 이 정의는 AI가 1940년대의 방 크기의 컴퓨터이든 미래에서 온 시간 여행 로봇이든 비네트에 적용됩니다. 여기서 우리의 요점은 AI 상호작용에 내재된 '맹목적 신뢰'가 AI 생성 결과물은 검증 (verification) 없이는 완전히 신뢰할 수 없음54을 인식하게 하며, 이는 잠시 멈추고 (pause) AI 도구와 그 결과물의 신뢰성 (trustworthiness)을 비판적으로 평가 (critically assess)할 필요를 촉발한다는 것입니다.

Technical (기술적)AI 시스템은 기반이 되는 계산 프레임워크(computational frameworks)를 기준으로 정의됩니다.
Capability-based (역량 기반)AI 시스템은 일반적으로 인간의 지능을 필요로 하는 작업을 수행하는 능력을 기준으로 정의됩니다.
Relational (관계적)AI 시스템은 인간의 추론(reasoning)과 실천(practice)에 미치는 영향을 기준으로 정의됩니다.
|
핵심 질문 (The Core Question)
|
네, 이 '관계적 정의'는 AI를 기술이나 성능이 아니라 '그것이 인간과 맺는 관계', 특히 '인간의 생각에 미치는 영향'을 기준으로 바라보는 방식이라 조금 낯설 수 있습니다.
더 쉽게 풀어서 설명해 드릴게요.
핵심은 "블랙박스(Black Box)의 대답을 믿을 것인가?" 하는 순간입니다.
우리가 AI, 특히 ChatGPT 같은 LLM에게 무언가를 물어보면 답이 나옵니다. 하지만 그 AI가 정확히 어떤 과정을 거쳐서 그 답을 만들었는지 우리는 알 수 없습니다. 그 내부 과정이 복잡한 '블랙박스'처럼 숨겨져 있기 때문이죠.
AI 상호작용 (AI Interaction)이란 바로 이 순간을 말합니다.
- AI가 판단(답)을 제시합니다. (예: "이 환자는 폐렴일 가능성이 높습니다.")
- 나는 그 답이 나온 과정을 100% 이해하거나 추적할 수 없습니다. (블랙박스)
- 하지만 그 답은 나의 다음 생각이나 행동에 영향을 줍니다.
- 그래서 나는 이 '블랙박스'의 답을 그냥 '믿고 사용할지' 아니면 '무시할지' 선택해야 합니다.
이때 우리가 그 답을 "에라 모르겠다, 그냥 믿고 쓰자!"라고 결정하는 것이 바로 '맹목적 신뢰(a leap of faith)'입니다.
🚗 가장 쉬운 예: 내비게이션 (GPS)
- 상황: 내비게이션(AI)이 "500m 앞에서 좌회전하세요."라고 말합니다.
- 블랙박스: 우리는 내비게이션이 왜 우회전이 아니라 좌회전을 하라고 했는지 그 복잡한 실시간 교통 정보, 알고리즘을 전부 알지 못합니다.
- AI 상호작용: 지금 이 순간, 나는 내비게이션의 '추적할 수 없는 판단'을 받았습니다.
- 맹목적 신뢰: "내비가 시키는 대로 가보자"라고 결정하고 핸들을 돌리는 것.
🩺 논문의 예: 의사와 AI
- 상황: 의사가 AI에게 환자 증상을 입력하자 AI가 "감별 진단 목록 1순위는 A입니다."라고 답합니다.
- 블랙박스: 의사는 AI가 왜 B나 C가 아닌 A를 1순위로 꼽았는지, 그 수백만 개의 파라미터를 거친 추론 과정을 알 수 없습니다.
- AI 상호작용: 의사는 AI의 '추적할 수 없는 판단'을 받았습니다.
- 맹목적 신뢰: "AI의 추천을 믿고 A 질환에 대한 검사부터 해보자"라고 결정하는 것.
결론적으로,
'관계적 정의'는 AI의 기술(Technical)이나 성능(Capability)이 중요한 게 아닙니다. AI가 "인간이 이해할 수 없는 답(블랙박스)"을 제시함으로써, "인간이 그것을 '신뢰'할지 말지 고민하게 만드는' 관계 그 자체가 중요하다고 보는 것입니다.
이 논문에서 이 정의를 중요하게 다루는 이유는, 교육자들이 바로 이 '맹목적 신뢰(leap of faith)'가 일어나는 순간을 포착해서, 학습자(학생, 레지던트)가 '비판적 사고'를 하도록 개입해야 하기 때문입니다. "AI가 그렇게 말했으니 맞겠지"가 아니라, "AI가 왜 그렇게 말했을까? 정말 맞을까? 내가 검증(verify)해야겠다"라고 생각하도록 가르쳐야 한다는 것이죠.
교육적 순간 만들기(Creating an Educational Moment)
교육자가 AI 상호작용을 인식하면, 교육적 순간 (educational moment)을 만들고 비판적 사고를 함양 (cultivate critical thinking)할 기회가 생깁니다.14 비판적 사고 강화에 있어 소크라테스식 접근 (Socratic approach)의 효과를 활용하는56 기존 모델55을 기반으로, DEFT (진단, 증거, 피드백, 교육; diagnosis, evidence, feedback, and teaching) 프레임워크는 임상 추론, 증거 기반 지원 (evidentiary support), 표적화된 피드백 (targeted feedback)에 대한 구조화된 토론 (structured discussions)을 강조합니다.57 우리는 AI의 도움을 받는 학습자가 임상 추론에 참여할 때 비판적 사고와 적응적 실천의 발전을 촉진하기 위해 고안된 수정된 접근 방식인 "DEFT-AI"를 제안합니다 (그림 3 및 표 S2). DEFT는 AI 상호작용의 맥락 밖에서 개발되었지만, 교육 이론에 강력한 뿌리 (strong roots)를 두고 있으며,55,57 그 상식적인 접근 방식 (common-sense approach)은 모든 학습자-AI 상호작용을 다루는 (negotiating) 일선 교육자 (frontline educators)들에게 공감 (resonate)을 얻을 것입니다. 아래에서는 각 DEFT 구성 요소가 AI 참여 권장 사항으로 이어지는 과정을 검토합니다.
그림 3. AI 상호작용 중 비판적 사고를 증진하기 위한 DEFT-AI의 사용.
진단, 토론, 그리고 담론 (Diagnosis, Discussion, and Discourse)
교육자는 학습자의 임상 추론 과정 (clinical reasoning process)과 AI 사용을 탐색 (probing)하는 것으로 시작합니다.
- 이 단계는 데이터 수집 (data acquisition)과 귀납적 추론 (inductive reasoning)을 반영하는 학습자의 임상 문제 종합 (synthesis of the clinical problem)에 대해 묻고,
- 학습자의 연역적 추론 (deductive reasoning)과 지식 기반 (fund of knowledge)을 반영하는 감별 진단에 대해 묻는 것을 포함합니다.
- 교육자는 또한 학습자가 AI와 어떻게 상호작용했는지 묻습니다.
- 구체적으로, 어떤 AI 도구와 어떤 프롬프트 (prompts)가 사용되었는지,
- AI 생성 결과물의 타당성 (validity)을 탐색하기 위해 후속 프롬프트 (follow-up prompts)가 구조화되었는지 여부와 그 방식,
- 그리고 그 결과물이 학습자의 진단적 접근법을 영향을 미쳤는지 (influenced), 대체했는지 (replaced), 또는 증강했는지 (augmented) 묻습니다.
증거 (Evidence)
이 단계에서 교육자는 학습자의 의학 및 AI 지식, 그리고 그 지식의 적용을 평가하기 위해 지지 증거 (supporting evidence)와 반대 증거 (opposing evidence)의 사용에 대해 탐색합니다. 이 과정은
- 진단 가설 (diagnostic hypotheses)을 생성하기 위한 진단 프레임워크 (diagnostic frameworks) 사용,
- 이러한 가설의 확인 (confirmation) 또는 반박 (refutation), 그리고
- 적응적 전문성 (adaptive expertise)의 특징인 대안 가설 (alternative hypotheses)을 생성하기 위해 지식을 활용 (leverage)하는 능력을 평가하는 것을 포함합니다.
교육자는 또한 학습자에게 지지 증거로 추론을 정당화 (justify the reasoning)하도록 요청하고, 현재 진행 중인 병태생리 (pathobiology)에 대한 학습자의 이해, 관련 임상 지침 및 문헌의 적용, 근거 중심 의학 (evidence-based medicine) 프레임워크의 사용을 탐색할 수 있습니다. 동시에, 교육자는 학습자가 AI 문해력 (AI literacy)에 대해 자가 평가 (self-assessment)에 참여하도록 할 수 있습니다. 첫째, 질문은
- 기술적 이해
- ("AI가 어떻게 결론에 도달했다고 생각하는가?"),
- 비판적 평가 (critical appraisal)
- ("이 AI의 약점은 무엇인가? 이 AI 애플리케이션의 역량과 한계를 평가할 수 있는가?"), 그리고
- 실용적 적용
- ("당신이 사용한 AI는 어떤 문제를 해결하도록 설계되었는가? 이 AI가 실무를 지원하는가, 아니면 방해하는가? 효과적인 프롬프트 전략 (prompting strategies)은 무엇인가?")58,59에 초점을 맞춥니다.
- 다음으로, 교육자는 학습자에게 AI 도구 사용을 뒷받침하는 증거를 식별하도록 유도해야 합니다:
- "어떤 동료 심사 연구 (peer-reviewed research)가 임상 추론 지원을 위한 이 도구의 사용을 뒷받침하는가?"
- 일반적인 AI 문해력 척도 (AI literacy scales)를 사용하여 학습자가 선택한 AI 애플리케이션의 작동 방식을 어느 정도 이해하고 있는지 확인할 수 있습니다.60
- 교육자는 학습자가 AI와 독립적으로 새로운 문제를 탐색하는 능력과 AI에 대한 과도한 의존 (overreliance) 가능성을 평가하기 위해, AI 없이 수정된 사례 발표를 통해 소리 내어 추론 (reason out loud)하도록 요청할 수 있습니다.
피드백 (Feedback)
안내된 자기 성찰 (Guided self-reflection)이 이 단계의 중심입니다. 교육자는 학습자에게 자가 평가를 바탕으로 당면한 사례 및 학습자의 AI 사용과 관련된 잠재적인 성장 기회 (potential growth opportunities)에 대해 성찰 (reflect)하도록 요청합니다. 이러한 기회에는
- 놓친 진단적 고려 사항 (missed diagnostic considerations),
- 사례와 관련된 의학 지식의 격차 (gaps in medical knowledge),61
- AI 기술 및 그 응용에 대한 문해력 (literacy)이 포함될 수 있습니다.
교육 (Teaching)
교육자는 학습자의 자기 성찰을 바탕으로,
- 특정 활동에서의 학습자의 추론 성과 (reasoning performance)와 특정 AI 도구 사용에 대한 피드백을 제공하고,
- 학습자의 요구에 맞춘 (tailored) 일반적인 교육 원칙 (general teaching principles)을 제공할 수 있습니다. 이는
- 임상 추론 과정의 강화 (reinforcing),
- (증거의 비판적 평가를 포함한) 근거 중심 의학 원칙의 적용을 장려하는 것, 그리고
- AI 문해력 (아래에서 논의됨)을 증진하는 것을 포함할 수 있습니다.
AI 참여 권고 (AI Engagement Recommendation)
교육자는 기초 기술 (foundational skills)과 AI 문해력을 동시에 증진하는 권고 (recommendations)로 마무리합니다. 드문 예외를 제외하고, 교육자는 AI를 사용한 지속적인 연습 (ongoing practice)을 장려해야 합니다. 보다 구체적으로, 교육자는
- 학습자가 간접적이거나 간헐적인 직접 감독 (indirect or intermittent direct supervision) 하에 AI 도구를 조심스럽게 사용 (cautiously engage)할 수 있다거나, 또는
- 학습자가 지속적인 자가 모니터링 (self-monitoring)과 교육을 병행하며 감독 없이 (without supervision) 안전하게 도구를 사용할 수 있다고 결론 내릴 수 있습니다.
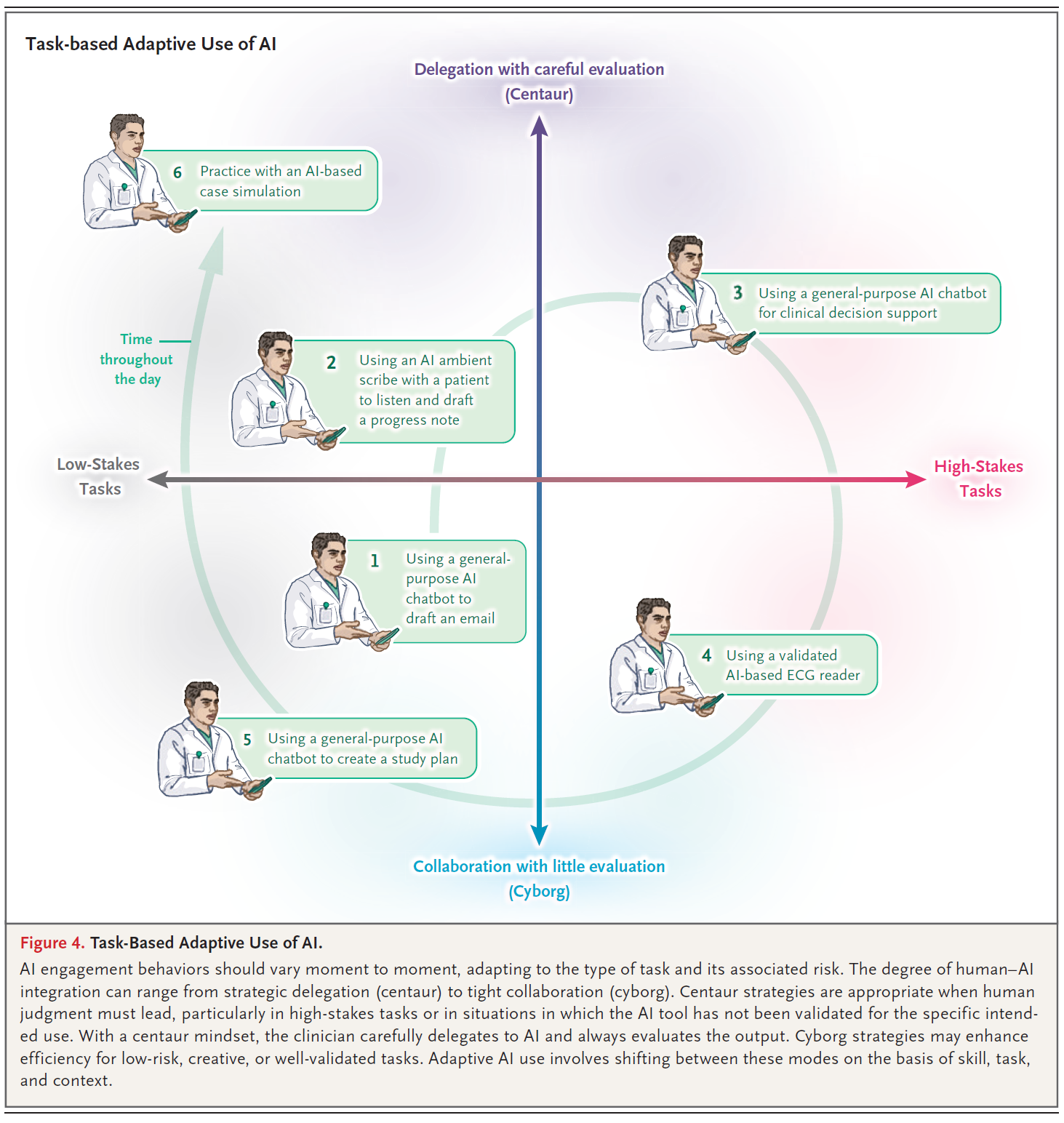
이 에피소드가 전개됨에 따라, 두 가지 뚜렷한 인간-AI 협업 행동 (human–AI collaboration behaviors) 중 하나가 나타날 가능성이 높습니다. 이러한 행동은 켄타우로스 (centaur)와 사이보그 (cyborg)5로 알려져 있습니다 (그림 4).
- 켄타우로스 사용자는 자신과 AI 사이에 전략적으로 작업을 분할 (strategically divide tasks)합니다.
- 그들은 각 개체의 강점과 역량에 따라 책임을 할당하는데, 이는 신화 속의 반인반마 (half-human, half-horse) 생물체의 이름에서 유래했습니다. AI는 아이디어 구상 (ideation), 요약 (summarization), 또는 초안 작성 (drafting)에 사용될 수 있지만, 켄타우로스 사용자는 진단과 의사 결정을 위해 자신의 임상적 판단 (clinical judgment)에 의존합니다. 반면에,
- 사이보그 사용자는 작업의 모든 단계에서 자신의 작업을 AI와 얽히게 (intertwine) 합니다.
- 이 이름은 인간과 기계의 하이브리드인 공상 과학 소설 속 사이보그에서 유래했습니다. 사이보그 사용자는 반복적으로 프롬프트를 입력하고 (iteratively prompting), 수정하며 (correcting), 정당성을 요구 (asking for justifications)한 다음, AI와 공동으로 (jointly with AI) 결과물을 정제 (refining)함으로써 AI와 함께 평가 계획을 작성합니다. 이러한 접근 방식은 AI 능력 범위 내의 잘 정의되거나 (well-defined) 위험도가 낮은 (low-risk) 작업에 대해 효율적이고 강력할 수 있지만, 자동화 편향 (automation bias)으로 인한 미숙련, 탈숙련, 또는 오숙련의 위험을 수반합니다.
사이보그와 켄타우로스 행동은 상호 배타적이지 (mutually exclusive) 않습니다. 사용자는 작업과 위험에 따라 이 두 가지 행동 사이를 전환해야 (shift between them) 하며, 이는 임상 추론 기술의 발전을 보존하면서 효율성과 혁신을 극대화할 수 있는 적응적 실천의 한 예입니다 (그림 4).
그림 4. AI의 과제 기반 적응적 사용.
교육자는 사이보그-켄타우로스 프레임워크를 사용하여 학습자가 자신의 상호작용 스타일을 성찰하도록 도울 수 있습니다. 예를 들어,
- 교육자는 고위험 (high-risk), 불확실 (uncertain), 또는 진단적 (diagnostic) 작업, 특히 AI 도구의 검증된 사용 범위를 벗어나는 작업(예: 복잡한 의사 결정을 위해 ChatGPT와 같은 범용 [general-purpose] AI 챗봇 사용)에 대해서는 켄타우로스 접근 방식 (centaur approach)을 채택하도록 권장할 수 있습니다. 이러한 환경에서, 교육자는 학습자가 AI를 사용하되 그 결과물을 주의 깊게 검증 (carefully validate its output)하도록 격려할 수 있습니다. 반대로,
- 사이보그 전략 (cyborg strategies)은 AI 도구가 신뢰할 수 있는 성능을 입증한 저위험 (low-risk), 잘 정의된 (well-defined), 또는 창의적인 (creative) 작업(예: 일반적인 의사소통 초안 또는 초기 아이디어 구상)에 적합할 수 있습니다. 사이보그 모드에서 학습자는 성찰적 감독 (reflective oversight)을 유지하고 필요에 따라 교육자에게 자신의 접근 방식을 정당화할 수 있다면, AI와 반복적으로 해결책을 공동 구축 (iteratively coconstruct solutions)할 수 있습니다.
- 보편적으로, 교육자는 학습자에게 질문 없이 (without interrogation) AI 결과물을 수동적으로 채택 (passively adopting)하는 것을 명시적으로 경고 (explicitly caution)해야 합니다. 대신, 적응적 참여 (adaptive engagement)가 권장되어야 합니다. 즉,
- 올바른 작업을 위해 올바른 상호작용 스타일을 선택하고, AI 제안에 대해 비판적으로 생각하며, 검증된 결과물을 얻기 위해 프롬프트를 정제 (refining prompts)하고, 학습자의 역량이 발전하고 맥락이 변화함에 따라 AI와의 임상적 상호작용을 수정하는 것입니다.
- 이러한 상호작용 스타일을 명명하고 (naming) 토론함으로써, 교육자는 학습자가 기술 발전 및 임상적 복잡성과 함께 성장할 수 있는 AI를 활용한 적응적 실천을 함양하도록 돕습니다.
AI 문해력 증진(Promoting AI Literacy)
AI 문해력 (AI literacy)은 컴퓨터 시스템의 판단을 재현 (retrace)할 수 없고 인지적 멈춤 (cognitive pause)이 필요한 순간으로서 AI 상호작용을 "인지 (call out)"하는 능력에서 시작됩니다.62 DEFT-AI는 비판적 사고를 통해 적응적 실천을 촉진하고, 작업에 따라 켄타우로스, 사이보그, AI-독립적 행동 간의 원활한 전환 (seamless shifting)을 용이하게 합니다. 교육자가 집중해야 할 AI 문해력의 두 가지 핵심 영역은 AI의 비판적 평가에 대한 구조화된 접근과 정확성과 관련성을 극대화하기 위한 프롬프트의 효과적인 사용 ("프롬프트 엔지니어링", prompt engineering)입니다.
AI의 비판적 평가 (critical appraisal)는 신뢰성에 대한 근거 기반 판단 (evidence-based judgment)을 내리기 위해 도구 자체와 그 결과물에 대한 구조화된 평가 (structured evaluation)를 필요로 합니다. 근거 중심 의학 (evidence-based medicine)의 기본 원칙에 뿌리를 둔 근거 기반 실천 (Evidence-based practice)은 새로운 증거를 임상 실무에 도입하는 구조화된 과정을 제공합니다.63 Sackett의 5단계 모델 — 질문하기 (asking), 최상의 증거 획득하기 (acquiring), 증거 평가하기 (appraising), 실무에 적용하기 (applying), 결과 평가하기 (assessing) — 은 근거 기반 실천을 위한 포괄적이고 구조화된 프레임워크를 제공합니다.64 이러한 과정을 통합하면 AI 도구와 그 결과물에 대한 별도의 탐구 (separate inquiries)를 구조화함으로써 특정 작업에서 AI의 신뢰성 (trustworthiness)을 판단하는 데 도움이 될 수 있습니다.
AI 도구에 대한 근거 기반 평가(Evidence-Based Evaluation of the AI Tool)
AI 도구 자체의 신뢰성 (trustworthiness)을 평가하기 위해, 첫 번째 단계는 증거 검색을 시작하는 질문 (question)을 결정하는 것입니다. 비네트의 경우, 교육자는 다음과 같은 질문을 할 수 있습니다:
- "성인 외래 환자 (adult ambulatory care patients)의 감별 진단 (differential diagnosis)에 대한 이 LLM의 정확도 (accuracy)는 얼마인가?"
두 번째와 세 번째 단계는 AI의 신뢰성에 대한 증거를 획득 (acquiring)하고 평가 (appraising)하는 것을 포함하며, 이는 동료 심사 연구 (peer-reviewed research), AI 스코어카드 (AI scorecards)65 및 관련 리더보드 (leaderboards) (AI 도구의 이름과 순위를 표시하는 스코어보드),66,66 그리고 보건 시스템이나 정부 기관(예: 식품의약국, Food and Drug Administration)의 규제 정보 (regulatory information) 등입니다. 스코어카드, 리더보드, 규제 프레임워크가 AI 도구 평가에 도움이 되지만, 실시간 판단 (real-time judgment)에는 불충분하며 (insufficient) 현재 교육자에게는 유용성이 제한적입니다. AI 도구 자체에 대한 포괄적인 평가 (comprehensive assessment)는 대부분의 교육자와 학습자의 범위를 벗어난다 (beyond the scope)고 가정하는 것이 타당해 보입니다.
AI 결과물에 대한 근거 기반 평가(Evidence-Based Evaluation of AI Output)
AI 도구를 평가하는 대신, 임상의는 자신의 임상 기술, 환자 선호도 (patient preferences), 연구 증거를 통합하여 AI 결과물 (AI output)을 평가할 준비가 되어 있습니다.64 임상의는 AI가 답변하는 데 사용된 임상 질문에 대해 독립적으로 증거를 획득하고 평가 (independently acquire and appraise evidence)하며 (예: 확립된 가이드라인, 출판된 문헌, 또는 전문가 컨설턴트의 의견), 자신들의 결론을 AI 결과물과 비교합니다. AI와 인간 결과물 간의 신뢰할 수 있는 일치 (reliable concordance)는 인간의 경계 (vigilance) 필요성을 줄일 수는 있지만 결코 제거할 수는 없으며 (never remove), AI 도구 사용의 신뢰성을 증진시킵니다. 학습자는 환자에 대한 임상 평가와 관련하여 AI 결과물을 자신의 임상 추론 결과물과 신뢰성 있게 비교할 수 있도록 이러한 독립적인 기술 (independent skills)을 개발해야 합니다.
LLM에 프롬프트 입력하기(Prompting LLMs)
효과적인 프롬프트 입력 (Effective prompting)은 LLM 기반 의료 애플리케이션의 유용성을 극대화하고 이에 대한 의미 있는 평가를 수행하는 데 중요한 기술 (critical skill)입니다.68 환자에 대한 컨설턴트의 의견 요청과 마찬가지로, LLM 프롬프트는 응답의 관련성 (relevance)과 품질 (quality)을 결정합니다. 인간의 자문 (human consultations)에서와 마찬가지로, 모호하거나 (vague) 잘못 구성된 (poorly framed) 질문은 혼란이나 잘못된 방향 (misdirection)으로 이어질 수 있습니다. 결과물은 입력만큼만 좋습니다 (The output is only as good as the input).
좋은 프롬프트의 주요 특징은 구체성 (specificity)과 맥락 제공 (context provision)을 포함합니다.
- 일반적인 질문과 비교할 때, 잘 정의된 질문 (well-defined query)이 더 정확한 응답을 산출합니다 (예: "심장 질환에 대해 말해줘" 대신 "관상동맥 질환의 가장 흔한 위험 요인은 무엇인가?").
- 맥락 제공은 배경 정보를 통합함으로써 LLM이 더 관련성 높은 (relevant) 결과물을 생성하도록 돕습니다 (예: "저는 흡입기 치료에 반응하지 않는 천식 환자를 진료실에서 돌보고 있는 폐 전문의입니다. 치료 반응 부족을 설명할 수 있는 여러 가설을 나열해 주십시오.").
- LLM을 유도하는 (lead) 편향된 프롬프트 (Biased prompts) (예: "진단명이 무엇인가요? 제 생각엔 천식 같은데요.")는 "아첨하는 (sycophantic)" 응답69과 인간과 유사한 인지 편향 (cognitive biases)37을 조장할 수 있습니다. 따라서 LLM과의 대화 중에 편향되지 않은 프롬프트 (unbiased prompts)로 연습하고 반복 (practice and iteration)하는 것이 필수적입니다.54
- 초기 프롬프트의 일부로 예시 사례 (example cases)를 제공하면 정확도가 향상됩니다.
- 또한, AI 모델에게 "소리 내어 생각하도록 (think out loud)" (즉, 연쇄적 사고 프롬프팅 [chain-of-thought prompting]) 요청하는 것은 AI의 추론 담론 (reasoning discourse)을 드러내어, 그 결과물의 정확도를 향상시키고 (enhances the accuracy)70,71 추론에 대한 평가 (assessment)를 가능하게 합니다.72
- 예를 들어, "우선순위가 정해진 감별 진단 목록을 생성해 줘"라는 프롬프트 뒤에 "너의 추론 과정을 설명해 줘"라고 이어붙이는 것입니다.
- 최신 LLM 모델은 인터페이스에 연쇄적 사고 추론이 내장 (embedded)되어 있어,71 결과물에 대한 비판적 평가를 용이하게 합니다.
- AI 결과물이 부정확해 보이거나 추가적인 성찰을 촉발할 때, 모델에게 설명을 요청하거나 응답을 수정하도록 프롬프트를 입력하는 등 후속 대화 (follow-up conversation)에 참여시키는 것은 수동적 사용 (passive use)을 능동적 학습 (active learning)으로 전환시키고, 비판적 사고를 강화하며, AI의 교육적 가치를 극대화할 수 있습니다.
검증하고 신뢰하라 (Verify and Trust)
AI 도구의 기술적 발전에도 불구하고, 그 사용은 여전히 신중한 고려와 함께 '맹목적 신뢰 (leaps of faith)'를 요구합니다. 검증의 필요성 (need for verification)은 AI 상호작용의 핵심에 있습니다. 의학 학습자들이 이러한 도구들을 환자 평가의 핵심 부분으로 점점 더 많이 사용함에 따라, 의학교육자들은 AI 상호작용이 여기 머무를 현실 (here to stay)임을 직시해야 합니다. 비판적 사고 (Critical thinking)가 AI에 대한 과도한 의존에서 발생할 수 있는 탈숙련, 미숙련, 오숙련에 대한 방벽 (bulwark)73이지만, 비계 (scaffold)로서 비판적 사고를 증진할 기회는 적응적 실천 기술 (adaptive practice skills)의 발전을 가속화하고 학습자와 교육자 모두의 AI 문해력을 동시에 향상시킬 수 있습니다. DEFT-AI는 학습자-AI 상호작용 중에 비판적 사고를 증진하기 위한 구조화되고 상식적인 접근 방식 (structured and common-sense approach)을 제공하며, AI 사용 과정의 일부로서 AI 결과물의 타당성 (validity)을 확립하는 것의 중요성을 강조합니다. 검증이 AI 사용의 핵심 (verification is key)이라는 확신을 수련생들에게 심어줄 (inculcate) 책임 (onus)은 교육자에게 있습니다. 이를 효과적으로 수행하려면 학습자와 교육자 사이에서 AI 역량을 증진하기 위해 AI 개발자, 보건 의료 시스템, 교육 프로그램 간의 긴밀한 협력을 통한 커리큘럼 재설계 (curricular redesign)가 필요할 것입니다. 또한 우리는 AI 상호작용이 발생하는 교육 환경에서 학습자-AI 상호작용에 대한 체계적인 평가 (systematic assessment)를 포함해야 합니다.74 거버넌스 구조 (governance structures), 엄격한 검증 프레임워크 (rigorous validation frameworks), 지속적인 모니터링 (ongoing monitoring) 없이는, AI 기반 오류와 편향의 위험이 AI 기술의 이점을 상회 (outweigh)할 수 있으며, 따라서 의학교육을 개선하기보다는 위태롭게 (jeopardize) 할 수 있습니다. 궁극적으로, "검증하고 신뢰하는 (verify and trust)" 패러다임을 육성하는 것은 AI가 인간 전문성의 유익한 증강 (beneficial augmentation)이 되도록 보장하는 데 매우 중요합니다.
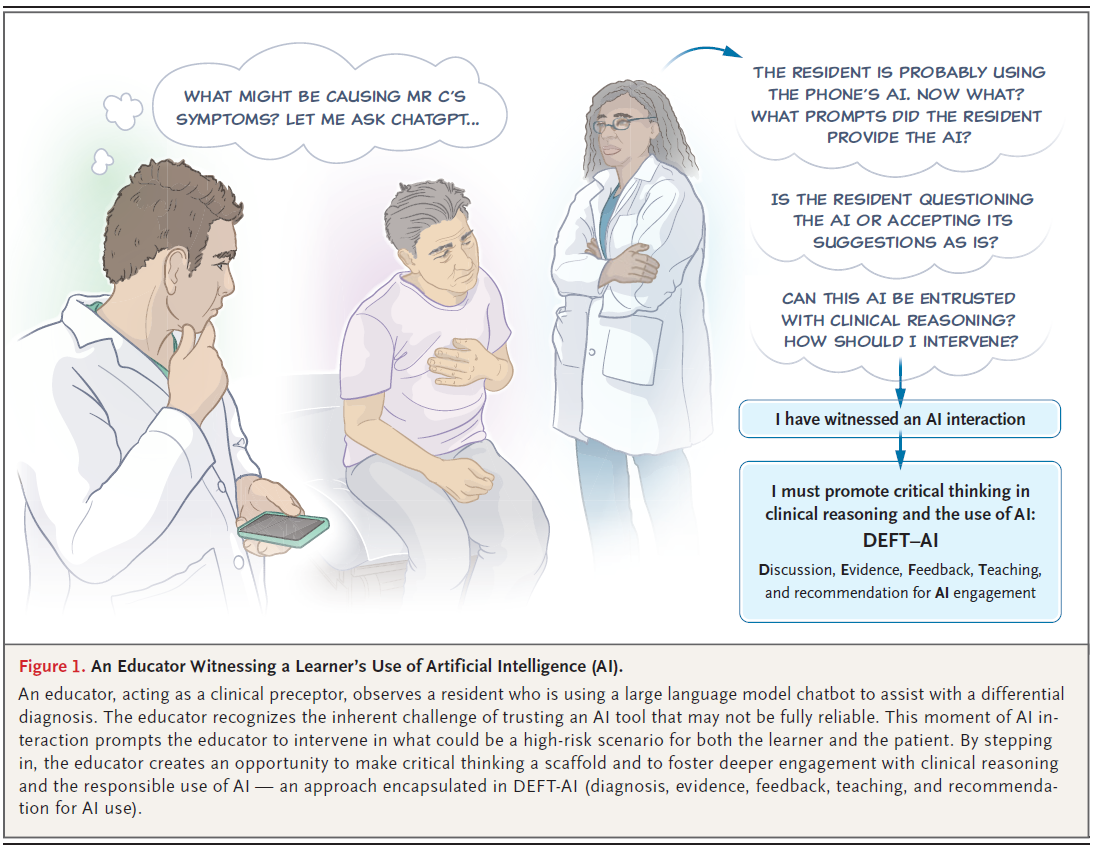
🖼️ 그림 1. 레전드 번역
그림 1. 학습자의 인공지능(AI) 사용을 목격하는 교육자.
임상 지도교수(clinical preceptor) 역할을 하는 교육자가 감별 진단(differential diagnosis)을 돕기 위해 대규모 언어 모델 챗봇을 사용하고 있는 레지던트를 관찰합니다. 교육자는 완전히 신뢰할 수 없을지도 모르는(not be fully reliable) AI 도구를 신뢰하는 것의 내재적인 어려움(inherent challenge)을 인식합니다. 이러한 AI 상호작용의 순간(moment of AI interaction)은 교육자로 하여금 학습자와 환자 모두에게 고위험 시나리오(high-risk scenario)가 될 수 있는 상황에 개입(intervene)하도록 촉발합니다. 개입함으로써, 교육자는 비판적 사고(critical thinking)를 비계(scaffold)로 삼고 임상 추론(clinical reasoning) 및 책임감 있는 AI 사용에 더 깊이 관여(deeper engagement)하도록 촉진할 기회를 만듭니다. 이는 DEFT-AI(진단[diagnosis], 증거[evidence], 피드백[feedback], 교육[teaching] 및 AI 사용 권장[recommendation for AI use])에 요약된 접근 방식입니다.
📋 그림 설명
이 그림은 논문에서 제시된 가상적이면서도 현실적인 임상 시나리오를 시각적으로 보여줍니다.
- 상황: 진료실에서 한 레지던트(학습자)가 가슴 통증을 호소하는 듯한 환자(Mr. C)를 진료한 후, 스마트폰을 보며 생각에 잠겨 있습니다.
- 학습자의 생각: 말풍선에는 "MR C의 증상을 유발하는 것이 무엇일까? ChatGPT에게 물어봐야겠다..."라고 생각하는 내용이 나타나, 학습자가 감별 진단을 위해 생성형 AI를 사용하려 함을 보여줍니다.
- 교육자의 관찰: 방 건너편에서 한 교육자(임상 지도교수)가 팔짱을 낀 채 이 장면을 목격하고 있습니다.
- 교육자의 내적 독백 (고민): 교육자의 생각은 여러 가지 질문으로 가득 차 있습니다.
- "레지던트가 아마도 휴대폰의 AI를 사용하고 있겠지. 이제 어떡하지? 레지던트가 AI에게 어떤 프롬프트를 제공했을까?"
- "레지던트가 AI에게 질문을 던지고(questioning) 있는 걸까, 아니면 제안을 그대로 받아들이고(accepting) 있는 걸까?"
- "이 AI에게 임상 추론을 맡겨도(entrusted) 될까? 어떻게 개입해야 할까?"
- 교육자의 결론 (행동 계획): 이러한 고민은 교육자가 취해야 할 행동을 보여주는 순서도로 이어집니다.
- 인식: "나는 AI 상호작용(AI interaction)을 목격했다."
- 필요성: "나는 임상 추론과 AI 사용에 있어 비판적 사고(critical thinking)를 증진해야 한다."
- 해결책: 이를 위한 프레임워크로 DEFT-AI (토론[Discussion], 증거[Evidence], 피드백[Feedback], 교육[Teaching], AI 참여 권고[recommendation for AI engagement])를 제시합니다.
결론적으로 이 그림은, 학습자가 AI를 사용하는 순간을 교육자가 목격했을 때 느끼는 딜레마와, 이 순간을 비판적 사고와 AI 문해력을 가르치는 교육적 순간(educational moment)으로 전환하기 위해 DEFT-AI 프레임워크를 사용해야 함을 강조하고 있습니다.
🖼️ 그림 2. 레전드 번역
그림 2. 적응적 실천의 발달과 AI의 영향.
실천(practice)과 비판적 사고(critical thinking)를 통해, 학습자들은 정형화된, 자동적 실천(automatic practice)의 중단(break, 별표[star]로 표시)에 대응하여 혁신적인 적응적 실천(adaptive practice)으로 전환하는 능력을 개발합니다. 그들이 발전하고 임상 실무에 들어서면서, AI의 사용은 위험(risks)과 기회(opportunities)를 모두 도입합니다.
- AI에 인지적 부담을 전가(Cognitive off-loading)하는 것은 AI에 대한 과도한 의존(overdependence)과 "탈숙련(deskilling)"으로 이어질 수 있으며,
- 반면 AI에 대한 맹목적인 의존(blind reliance)은 AI 오류가 도전받지 않은 채(unchallenged) "오숙련(mis-skilling)"을 초래할 수 있습니다.
- 너무 일찍 도입되면(If introduced too early), AI는 학습자가 필수 기술을 습득하는 것을 막을 수 있습니다("미숙련, never-skilling").
- 반대로, AI의 현명한 사용(judicious use)은 비판적 사고의 필요성을 강조하고 효과적인 인간-AI 협업(human–AI collaboration)을 촉진함으로써 실천과 학습을 향상(enhance)시킬 수 있습니다.
📋 그림 설명
이 그래프는 시간이 지남(X축)에 따라 학습자의 실무 기술 수행 능력(Y축)이 어떻게 발달하는지, 그리고 생성형 AI의 도입이 이 과정에 어떤 영향을 미치는지 보여줍니다.
- 기본적인 학습 곡선 (왼쪽 녹색 선):
- 학습자는 '초심자(Novice)' 수준에서 의학 교육을 시작합니다.
- 시간이 지남에 따라 '상급자(Advanced)'를 거쳐 '역량 있음(Competent)' 수준에 도달합니다. 이 수준은 '독립적 실무를 위한 최소 허용 기술 숙련도(MINIMAL ACCEPTED SKILL PROFICIENCY FOR INDEPENDENT PRACTICE)'입니다.
- 계속 발전하여 '능숙함(Proficient)' 수준에 이르면, 정형화된 '자동적 실천(Automatic practice)'을 수행합니다.
- 어느 시점(분홍색 별표)에서 '정형화된 실무의 중단(BREAK IN ROUTINE PRACTICE)'이라는 새로운 도전에 직면합니다.
- 이때 '비판적 사고(CRITICAL THINKING)'를 발휘하여 기존의 자동적 실천에서 벗어나 '적응적 실천(Adaptive practice)'으로 전환하며 '전문가(Expert)' 수준으로 나아갑니다.
- 생성형 AI의 도입 (수직 주황색 선):
- 학습자의 발달 과정 중 '생성형 AI가 도입(Generative AI is introduced)'되는 시점을 나타냅니다. 이 그림은 AI가 학습자의 여러 발달 단계(초심자, 역량 있음, 능숙함)에서 도입될 수 있음을 보여줍니다.
- AI 도입 후의 다양한 경로 (오른쪽 곡선들):
- AI가 도입된 이후, 학습자가 AI를 어떻게 활용하느냐에 따라 매우 다른 결과가 나타납니다.
- 긍정적 경로 (AI 강화):
- AI 강화 학습 (AI-enhanced learning): AI를 비판적으로 활용하여 '역량 있음(Competent)' 또는 '능숙함(Proficient)' 수준에서 학습을 가속화하고 발달을 지속합니다.
- AI 강화 적응적 실천 (AI-enhanced adaptive practice): '능숙함(Proficient)' 수준의 학습자가 AI를 비판적 사고와 결합하여 '적응적 실천' 능력을 더욱 향상시키는 최상의 시나리오입니다.
- 부정적 경로 (위험):
- 미숙련 (Never-skilling): '초심자(Novice)' 또는 '상급자(Advanced)' 단계에서 AI가 너무 일찍 도입되어 학습자가 AI에 의존한 나머지, '독립적 실무를 위한 최소 역량'조차 스스로 개발하지 못하는 상태입니다.
- 발달 정체 (Arrested development): '역량 있음(Competent)' 수준에서 AI에 부적절하게 의존하여 더 이상 기술이 발전하지 않고 정체되는 상태입니다.
- 탈숙련 (Deskilling): 이미 '역량 있음' 또는 '능숙함' 수준의 기술을 습득했지만, AI에 과도하게 의존하여 이전에 가졌던 기술을 상실하고 수행 능력이 오히려 퇴보하는 현상입니다.
- 오숙련 (Mis-skilling): AI가 생성한 부정확하거나 편향된 정보를 맹목적으로 수용하여 잘못된 지식이나 기술을 습득하고 강화하는 현상입니다.
- 또 다른 경로 (놓친 기회):
- AI를 채택하지 않음 (No adoption of AI): (가장 위의 점선) AI 기술을 아예 받아들이지 않는 경우로, 이는 'AI 강화 적응적 실천'이라는 잠재적 이점을 얻지 못하는 '놓친 기회(missed opportunity)'로 표시됩니다.
결론적으로, 이 그림은 AI가 학습자의 기술 발달에 양날의 검임을 시각적으로 강조합니다. 비판적 사고 없이 맹목적으로 의존하면 미숙련, 탈숙련, 오숙련 등의 심각한 위험을 초래할 수 있지만, 현명하게(judiciously) 비판적 사고와 결합하여 사용하면 학습을 가속화하고 '적응적 실천'을 강화하는 강력한 기회가 될 수 있음을 보여줍니다.


🖼️ 그림 3. 레전드 번역
(맞은편 페이지) 그림 3. AI 상호작용 중 비판적 사고를 증진하기 위한 DEFT-AI의 사용.
AI 상호작용을 인식한 후, 교육자는 구조화된 교육적 순간(structured educational moment)에 학습자를 참여시켜 상호작용에 대해 토론하고, 평가하며, 피드백을 제공하고, 임상 추론과 AI 사용법을 가르칩니다. 이 토론은 사용된 프롬프트를 포함하여 학습자의 임상 추론 과정(learner's clinical reasoning process)과 AI 사용 접근 방식을 포괄합니다. 교육자는 학습자의 임상 및 AI 지식을 평가하기 위해 지지 증거(supporting evidence)와 반대 증거(opposing evidence)의 사용에 대해 학습자를 탐색합니다. 이 과정은 학습자가 AI를 임상 추론을 대체(replace)하기 위해 사용했는지 아니면 정보를 얻기(inform) 위해 사용했는지 판단하는 데 도움이 되며, 학습자의 AI 문해력(AI literacy)을 엿볼 수 있는 창을 제공합니다. 그 후 교육자는 학습자가 성장 기회(growth opportunities)에 대해 성찰(reflecting)하도록 안내하고 AI 상호작용 및 임상 추론에 대한 비판적 사고(critical thinking)를 장려합니다. 마지막으로, 교육자는 AI를 효과적으로 사용하고, 올바른 도구를 선택하며, 프롬프트를 정제(refining prompts)하는 것에 대해 집중적인 교육(focused teaching)을 제공합니다. 학습자는 AI 출력에 의존하는 것(사이보그[cyborg] 전략)과 AI 출력을 확인하는 것(켄타우로스[centaur] 전략) 사이를 전환하며, 과제(task)에 맞게 AI 사용을 조절하도록(adapt) 권장됩니다. 표 S2는 DEFT-AI의 확장된 버전을 제공합니다.
[상단 제목] DEFT-AI: AI 사용 중 비판적 사고를 증진하기 위함
[인물] Educator (교육자) Learner (학습자)
진단, 토론, 담론 (Diagnosis, Discussion, and Discourse)
[설명] 교육자가 학습자의 구체적인 AI 사용에 대해 설명을 요청합니다.
- Educator: 어떤 구체적인 AI를 사용했나요? Learner: 제 휴대폰에 있는 무료 버전 ChatGPT를 사용했습니다.
- Educator: 이 과정에서 AI를 어떻게 사용했나요? Learner: 그냥 "천명(wheezing)의 감별 진단은 무엇인가?"라고 입력했습니다.
- Educator: 앱에 어떤 프롬프트를 입력했나요? Learner: 최고의 진단 검사와 치료 전략을 물었습니다.
증거 (Evidence)
[설명] 교육자가 학습자의 근거 기반 AI 사용에 대해 평가하도록 요청합니다.
- Educator: AI가 생성한 결과물을 어떻게 검증(verify)했나요? Learner: 음. 안 했습니다. 답변이 저에게는 그럴듯해 보였습니다.
- Educator: 사용한 AI가 정확하고(accurate) 안전하다(safe)고 알려져 있나요? Learner: 네. 소셜 미디어에서 사람들이 (그 AI가) 진단을 얼마나 잘하는지에 대해 쓴 게시물들을 계속 보고 있습니다.
피드백 (Feedback)
[설명] 교육자가 학습자에게 AI 사용에 대한 성장 기회(growth opportunities)를 성찰(reflect)하도록 요청합니다.
- Educator: 이 경우 자신의 AI 사용을 어떻게 평가하나요? Learner: 저는 ChatGPT 사용에 꽤 익숙해진(familiar) 것 같습니다. 지금은 항상 사용하거든요.
- Educator: AI 사용을 어떻게 개선할(improve) 수 있을까요? Learner: 심전도(ECGs)와 흉부 방사선 사진을 판독할 수 있는 AI가 빨리 나왔으면 좋겠어요. 다음번에는 AI 결과물을 검증해야겠습니다.
교육 (Teaching)
[설명] 교육자가 대화에서 발견된 사항(findings)을 바탕으로 집중적인 교육 지점(focused teaching points)을 제공하고, 앞으로 AI를 안전하게 사용할지 여부, 시기, 방법에 대해 권고합니다.
Educator:
- 효과적이라고 알려진 AI 도구를 사용하세요. 그 정확성과 안전성에 대한 동료 심사(peer-reviewed) 증거를 찾아보세요. 우리 기관은 아마 고품질 데이터를 기반으로 유사한 모델을 채택하고 검증했을 수 있습니다.
- 가치 있고 정확한 결과물을 생성하기 위해서는 챗봇에 프롬프트(Prompting)를 입력하는 것이 중요합니다. "컨설턴트와 대화하는 것"이라고 생각하세요.
- 누가(Who) (AI의 의도된 용도와 당신의 역할), 어디서(Where) (맥락에 대한 설명), 그리고 무엇을(What) (당신의 목표와 구체적인 과제 또는 질문)에 대해 충분하고 구체적인 정보를 제공하세요.
- 항상 AI에게 "추론 과정을 설명하도록(explain its reasoning)" 요청하세요. 이는 AI의 답변을 개선시키고, 당신이 AI가 어떻게 생각하는지 그리고 얼마나 신뢰할 수 있는지를 평가할 수 있게 해줍니다.
- 프롬프트 한 번으로는 충분하지 않습니다(One prompt is not enough): 대화를 나누고 피드백을 주세요. 제가 당신에게 그랬던 것처럼, 당신도 AI에게 "자가 성찰에 참여하고 오류를 찾도록(engage in self-reflection and look for errors)" 요청할 수 있습니다.
- AI는 항상 오류(error)와 편향(bias)에 취약합니다(prone). 항상 "검증하고(verify) 신뢰하세요(trust)". 당신의 지식, NEJM 그룹의 간행물과 같은 신뢰할 수 있는 의학 정보 출처, 그리고 저와 같은 당신의 신뢰할 수 있는 동료들과 대조하여 그 답변을 반드시 확인하세요.
AI 참여 권고 (Recommendation for AI engagement)
[설명] 교육자가 안전한 AI 사용을 위해 학습자에게 특화된(learner-specific) 권고를 제공합니다.
Educator:
- 당신의 추론을 대체(replace)하기보다는 정보를 얻기(inform) 위해 AI를 사용하는 연습을 계속하세요. AI 결과물은 예비 방사선 보고서나 자동화된 심전도 해석과 마찬가지로 당신의 예비적인 입력값(preliminary inputs)입니다. 검증하고, "그런 다음(then)" 신뢰하세요. 언제 (사이보그[cyborg]처럼) 그것에 의존(rely on)할 수 있는지 그리고 언제 (켄타우로스[centaur]처럼) 그 결과물을 확인(confirm)해야 하는지 알아야 합니다.
🖼️ 그림 4. 레전드 번역
그림 4. 과제 기반 AI의 적응적 사용(Task-Based Adaptive Use of AI).
AI 참여 행동(AI engagement behaviors)은 과제의 유형(type of task)과 관련된 위험(associated risk)에 맞춰 순간순간 달라져야(vary moment to moment) 합니다. 인간-AI 통합(human–AI integration)의 정도는 전략적 위임(strategic delegation) (켄타우로스, centaur)에서부터 긴밀한 협업(tight collaboration) (사이보그, cyborg)에 이르기까지 다양할 수 있습니다.
- 켄타우로스 전략은 특히 위험도가 높은 과제(high-stakes tasks)나 AI 도구가 특정 의도된 용도로 검증되지 않은(not been validated) 상황과 같이 인간의 판단이 주도해야(human judgment must lead) 할 때 적절합니다. 켄타우로스 사고방식(centaur mindset)을 통해, 임상의는 AI에게 신중하게 작업을 위임(delegates)하고 항상 그 결과물을 평가(evaluates)합니다.
- 사이보그 전략은 위험도가 낮거나(low-risk), 창의적이거나(creative), 혹은 잘 검증된(well-validated) 과제에 대해 효율성을 향상시킬 수 있습니다. 적응적 AI 사용(Adaptive AI use)은 기술, 과제, 맥락(skill, task, and context)에 기초하여 이러한 모드(modes) 사이를 전환(shifting)하는 것을 포함합니다.
📋 그림 설명
이 그림은 의료 현장에서 AI를 '적응적'으로 사용하는 것이 무엇을 의미하는지 시각적으로 보여주는 2x2 매트릭스입니다.
- 수평축 (X축): 과제의 위험도(Stakes)를 나타냅니다.
- 왼쪽: 위험도가 낮은 과제 (Low-Stakes Tasks) (예: 행정 업무)
- 오른쪽: 위험도가 높은 과제 (High-Stakes Tasks) (예: 환자 진단 및 치료)
- 수직축 (Y축): AI와의 상호작용 방식(Interaction Style)을 나타냅니다.
- 아래쪽 (사이보그, Cyborg): '평가/검토가 거의 없는 (긴밀한) 협업 (Collaboration with little evaluation)'. 사용자와 AI가 긴밀하게 통합되어 함께 작업합니다.
- 위쪽 (켄타우로스, Centaur): '신중한 평가/검토를 동반한 위임 (Delegation with careful evaluation)'. 사용자가 AI에게 작업을 맡기되(위임), 그 결과물을 비판적으로 검토하고 감독합니다.
그림 속 6가지 예시 과제:
이 그림은 학습자(의사)가 하루 동안(Time throughout the day, 회색 화살표) 수행하는 여러 과제를 이 매트릭스 상에 배치하여, 과제의 성격에 따라 AI 사용 전략을 어떻게 바꿔야 하는지 보여줍니다.
- 범용 AI 챗봇으로 이메일 초안 작성: (Low-Stakes / Cyborg) 위험도가 낮고, AI와 긴밀하게 협업하여 효율을 높입니다.
- AI 앰비언트 스크라이브(ambient scribe)를 사용하여 환자 진료 내용을 듣고 경과 기록지 초안 작성: (Low-Stakes / Centaur) 위험도는 낮지만, 기록의 정확성을 위해 AI가 작성한 초안을 신중하게 검토(평가)해야 합니다 (켄타우로스 방식).
- 임상 의사결정 지원을 위해 범용 AI 챗봇 사용: (High-Stakes / Centaur) 위험도가 매우 높고 AI가 검증되지 않았으므로, AI의 제안을 전적으로 위임하되 매우 신중하게 평가하고 검증해야 합니다 (가장 켄타우로스적인 접근).
- 검증된 AI 기반 ECG 판독기 사용: (High-Stakes / Cyborg) 환자 진단과 관련된 고위험 과제이지만, 도구가 '검증'되었기 때문에 3번보다 더 긴밀하게 협업(사이보그)할 수 있습니다. 하지만 여전히 인간의 최종 확인이 필요합니다.
- 범용 AI 챗봇으로 학습 계획 생성: (Low-Stakes / Cyborg) 위험도가 낮으므로 AI와 긴밀하게 협업하여 계획을 세웁니다.
- AI 기반 사례 시뮬레이션으로 연습: (Low-Stakes / Centaur) 위험도는 낮지만, AI가 제공하는 시뮬레이션 내용을 학습자가 비판적으로 평가하며 학습해야 합니다.
결론: 이 그림의 핵심은 AI 사용에 '하나의 정답'은 없다는 것입니다. '적응적 실천(Adaptive Practice)'이란, 이메일 작성(1번)처럼 사이보그 모드로 효율을 높이다가도, 임상 의사결정(3번)처럼 켄타우로스 모드로 즉시 전환하여 비판적 평가를 수행하는 등, 과제의 위험도와 맥락에 맞춰 AI와의 관계(위임 vs 협업)를 유연하게 조절하는 능력을 의미합니다.
'논문 읽기 (with AI)' 카테고리의 다른 글
| 임상적 불확실성에 대비한 수련의 교육 전략 (N Engl J Med. 2025) (0) | 2025.11.16 |
|---|---|
| 병상 옆 임상 만남(Bedside Clinical Encounter)을 재활성화하기 위한 전략 (N Engl J Med. 2025) (0) | 2025.11.16 |
| 환자 진료 최전선에서의 역량 기반 의학 교육 (N Engl J Med. 2025) (0) | 2025.11.16 |
| 진단 형평성(Diagnostic Equity)에 대한 의학 교육을 통한 진단 탁월성(Diagnostic Excellence) 증진 (N Engl J Med. 2025) (0) | 2025.11.13 |
| 의학 교육의 불연속성 위기 헤쳐나가기 (N Engl J Med. 2025) (0) | 2025.11.12 |