Artificial Intelligence to Support Qualitative Data Analysis: Promises, Approaches, Pitfalls

안녕하세요! 요즘 챗GPT(ChatGPT) 같은 생성형 AI가 연구 분야에서도 뜨거운 감자죠? 🔥 특히 숫자로 딱 떨어지는 양적 연구가 아닌, 인터뷰나 텍스트의 숨은 의미를 찾아야 하는 질적 데이터 분석(Qualitative Data Analysis, QDA)에서도 AI를 써도 될지, 쓴다면 어떻게 써야 할지 고민이 많으실 거예요.
오늘 소개할 논문은 바로 이 질문에 대해 아주 명쾌하고 비판적인 시각을 제공합니다. 연구자들이 AI를 '어떻게' 쓸 수 있는지, 그리고 '무엇을' 조심해야 하는지 꼼꼼하게 짚어준 논문이에요. 핵심 내용만 쏙쏙 뽑아 정리해 드릴게요! 🧐
1. AI가 주는 약속 (The Promise): 든든한 조수, 하지만 대장은 나!
이 논문은 AI가 단순히 시간을 아껴주는 도구를 넘어, 연구의 진입 장벽을 낮추는 '파괴적 혁신(Disruptive Innovation)'이 될 수 있다고 말해요. 비용이나 언어 장벽 때문에 연구를 못 했던 사람들에게 기회를 줄 수 있다는 거죠.
하지만 AI가 완벽한 건 아닙니다. 연구진은 AI를 '팀의 일원'으로 보되, 절대적인 리더가 아닌 '주니어 멤버'로 생각하라고 조언합니다.
"AI는 가상 동료, 초심자... 그럼에도 유용한 기여를 할 수 있는 존재로서 역할을 수행할 수 있습니다."
"AI can serve as a virtual colleague, a novice … who nevertheless can make a useful contribution."
즉, 전사(Transcription)나 번역, 텍스트 요약 같은 일은 AI가 기가 막히게 잘하지만, 깊은 의미를 찾아내는 건 여전히 사람의 몫이라는 거죠.
2. 어떻게 쓸 수 있을까? (Approaches): 주제 분석부터 담론 분석까지
논문에서는 AI를 활용한 여러 접근법을 소개해요.
- 주제 분석 (Thematic Analysis): 방대한 데이터에서 코드(Code)를 찾고 패턴을 발견하는 데 도움을 줄 수 있어요.
- 담론 분석 (Discourse Analysis): 특히 거대 언어 모델(LLM)을 이용한 토픽 모델링(Topic Modeling)은 우리가 평소에 놓치기 쉬운, 너무나 당연해서 보이지 않는 '헤게모니(Hegemony)'를 발견하는 데 유용하다고 해요.
하지만 연구진은 챗GPT 같은 LLM을 사용할 때 프롬프트(Prompt)를 아주 정교하게 짜야 한다고 강조합니다. 대충 물어보면 대충 답하거든요. 😅
3. 주의해야 할 함정 (Pitfalls): 편한 게 능사는 아니다! 🚨
이 부분이 정말 중요해요! AI는 기본적으로 확률적(Probabilistic) 모델이지, 의미를 이해하는 존재가 아니에요. 그래서 그럴듯한 거짓말, 즉 '환각(Hallucination)'을 만들어낼 수 있어요.
더 무서운 건, AI가 분석을 너무 쉽게 해주다 보니 연구자가 데이터와 멀어질 수 있다는 점이에요. 질적 연구는 연구자가 데이터에 푹 빠져서(Immersion) 그 안의 미묘한 의미를 읽어내야 하는데, AI에게만 의존하면 그 '감'을 잃게 되죠.
"분석을 아웃소싱하는 것은... 연구 품질에 영향을 미치고... 연구자들에게서 데이터와의 정서적 연결—친밀감, 자부심, 주인의식—을 앗아갑니다."
"Outsourcing analysis … impacts research quality [and] robs [researchers] of their emotional connection—the intimacy, pride, and ownership—with the data."
4. 성찰성 (Reflexivity): AI도 편향이 있다?
질적 연구에서 연구자의 주관성을 성찰하는 건 필수죠. 이 논문은 AI도 하나의 '팀원'으로서 성찰의 대상이 되어야 한다고 제안해요. AI가 어떤 데이터로 학습했는지(개인적 렌즈), AI가 연구자와 어떻게 상호작용하는지(대인적 렌즈) 등을 따져봐야 한다는 거죠. AI의 알고리즘은 '보이지 않는 손(Invisible Hand)'처럼 우리 분석에 영향을 미치니까요.
💡 결론: 인간이 루프를 장악해야 한다!
결국 이 논문의 결론은 "AI를 쓰지 말라"가 아닙니다. "잘 알고, 똑똑하게 쓰자"는 거예요. AI는 엄청난 잠재력을 가지고 있지만, 그 운전대는 반드시 사람이 잡고 있어야 합니다. 연구진의 마지막 핵심 조언을 인용하며 마칠게요.
"'인간을 루프 안에(human in the loop)' 두어야 할 뿐만 아니라, 인간이 루프를 책임져야(in charge of the loop) 합니다." "Not only must there be a ‘human in the loop,’ the human must be in charge of the loop."
여러분도 AI라는 강력한 도구를 활용하되, 연구의 주인으로서 날카로운 통찰력을 놓치지 마시길 바랍니다! 💪
인공지능(Artificial intelligence, AI)은 우리 존재(existence)의 많은 측면에 침투하여(infiltrated), 우리의 직업적, 개인적 삶에 강력한 약속(powerful promises)과 엄청난 골칫거리(tremendous troubles)라는 새로운 긴장(new tensions)을 도입했습니다. 보건 의료(health care), 교육(education), 연구(research) 분야에서 AI의 역할에 대한 수많은 담론(discourses) 속에서, 우리는 AI가 질적 연구(qualitative research)를 어떻게 지원할 수 있는지를 명확히 설명하는 데(articulating) 있어 격차(gap)가 있음을 인식합니다. 연구자들(초심자와 전문가 모두)과 저널 편집자들은 서술형 데이터 분석(analysis of narrative data), 즉 질적 데이터 분석(qualitative data analysis [QDA])에 있어 AI의 능력(capabilities), 결점(shortcomings), 역할(roles), 위험(dangers), 그리고 윤리적 파장(ethical repercussions)에 대한 비판적 평가(critical appraisal)를 통해 혜택을 얻을 수 있을 것입니다. 우리의 목적은 그러한 평가(appraisal)를 제공하는 것입니다.
이 논문은 3가지의 구별되는 활동(distinct activities)을 기술합니다:
- (1) QDA를 위해 챗GPT(ChatGPT)를 사용한 즉흥적인 실험(extemporaneous experiment),
- (2) QDA를 위한 AI 사용에 대한 주제 범위 문헌 고찰(scoping review), 그리고
- (3) QDA를 위해 AI를 사용하는 것의 역사, 현재의 사용, 잠재적인 약속(행동 유도성[affordances], 적용[applications]) 및 함정(pitfalls)에 대한 비판적 탐구(critical exploration)입니다.
이 논문은 튜토리얼(tutorial)이 아닙니다. 사용 가이드(how-to guide)가 바람직할 수도 있겠지만, 우리는 몇 가지 이유로 그것을 미루고자(defer) 합니다.
- 그것은 시기상조(premature)일 것입니다: 우리는 먼저 QDA를 위한 AI 사용이 과연 좋은 아이디어인지부터 고려해야 합니다.
- 그것은 불완전할(incomplete) 것입니다: 다른 문제들을 다루면서 특정 방법론(specific methods)을 적절히 상세화하는 것은 불가능할 것입니다.
- 이 분야는 너무 빨리 움직이고 있습니다(moving too fast): 상세한 지침은 금방 구식(outdated)이 되어버릴 것입니다.
- 가장 중요한 것은, 우리의 목적이 광범위하고 지속적인 문제들(broad, enduring issues)—즉 약속(promises)과 잠재적 함정(potential pitfalls)—에 초점을 맞추는 것이라는 점입니다.
정의 (Definitions)
현재의 목적을 위해, 우리는 QDA를 서술형(비수치적) 데이터(narrative [nonnumeric] data)에 대한 모든 분석으로 정의합니다. QDA는 공식적인 학술 연구(formal academic research), 시장 조사(market research), 프로그램 평가(program evaluation), 정책 문서 생성(creation of policy documents)에 사용됩니다. 이러한 사용은 광범위한 존재론(ontologies, 진리의 본질에 대한 믿음), 인식론(epistemologies, 진리가 어떻게 학습될 수 있는지), 패러다임(paradigms), 그리고 방법론(methods)을 포괄합니다.
부록 1(Appendix 1)은 AI와 관련된 핵심 개념(key concepts)에 대한 간략한 검토를 포함하고 있습니다. 다른 출처들이 더 상세한 소개(detailed introductions)를 제공합니다. 우리는 AI가 확률적(probabilistic)이며 지각이 있는 것(sentient)이 아님을 강조합니다; AI는 패턴을 식별하는 데(identifying patterns) 탁월하지만 의미를 추론(infer meaning)할 수는 없습니다. 우리는 독자들에게 현재 챗GPT(ChatGPT)가 유행(in vogue)하고 있지만, 그것이 AI와 동의어(synonymous)는 아니라는 점을 상기시킵니다.
- 챗GPT는 OpenAI의 생성형 사전학습 트랜스포머(generative pretrained transformer, GPT)로 가는 사용자 인터페이스(user interface, 앞문[front door])일 뿐이며,
- GPT는 수많은 거대 언어 모델(large language models, LLMs) 중 하나일 뿐이고, LLM은 AI의 한 유형일 뿐입니다.
이러한 떠오르는 "기반 모델(foundation models)"들이 이전의 AI 도구들과 비교하여 새로운 능력(novel capabilities)을 가지고 있기는 하지만, 우리는 대부분의 경우 의도적으로 이것들을 구별하지 않습니다; 대신, 우리는 AI의 사용을 일반적인 용어(general terms)로 논의하여 사용자들이 자신의 필요에 가장 적합한 도구(tools best suited)를 고려할 수 있도록 합니다.
QDA를 위한 챗GPT: 증례 보고 (ChatGPT for QDA: A Case Report)
이 논문의 추진력(impetus)은 챗GPT(OpenAI, San Francisco, California)가 QDA를 위해 즉시 사용 가능한 도구(out-of-the-box tool)로서 어떻게 기능할 수 있을지에 대한 우리의 개인적인 호기심(personal curiosity)이었습니다. 다른 과업(tasks)들에서의 챗GPT의 성공에 자극받고(prompted), 이전 저자들의 탐색적 QDA 노력(exploratory QDA efforts)에 고무되어, 우리는 3개의 기존 서술형 데이터셋(existing narrative datasets)을 재분석(reanalyze)하기 위해 챗GPT-4(2024년 2월 기준)를 테스트했습니다. 부록 2(Appendix 2)는 우리의 경험을 간략히 기록하고 있으며(chronicles), 추가 디지털 부록 1(Supplemental Digital Appendix 1)은 더 자세한 세부 사항을 제공합니다. 요약하자면, 반복적인 노력(repeated efforts)에도 불구하고, 우리는 실질적인 가치(substantial value)가 있는 분석 결과를 도출(elicit)할 수 없었습니다. 우리는 이 노력을 대체로 실패(failure)로 간주했으며, 돌이켜보면(in retrospect) 이것은 우리의 순진함(naivete)—기대치(expectations), QDA를 위한 컴퓨터 사용, 프롬프트 엔지니어링의 정교함(sophistication of prompt engineering, 특히 다단계 및 고차원적 요청[multistep and high-level requests] 사용)에 있어서의—과 챗GPT의 내재적 결점(inherent shortcomings)이 결합된 결과라고 생각합니다.
주제 범위 문헌 고찰 (Scoping Review)
이러한 경험은 AI가 QDA를 어떻게 지원해 왔는지에 대해 더 배우도록 우리를 자극했고(prompted), 이에 우리는 주제 범위 문헌 고찰(scoping reviews)을 위해 수용된 방법(accepted methods)에 따라 QDA에서의 AI에 대한 체계적이지만 제한적인(systematic but limited) 주제 범위 문헌 고찰을 수행했습니다. 우리의 방법(methods), 결과(results), 한계(limitations)는 여기에 간략히 요약되어 있으며 추가 디지털 부록 2(Supplemental Digital Appendix 2)에 자세히 기술되어 있습니다. 전문 연구 사서(expert research librarian)의 지원을 받아, 우리는 2024년 2월과 5월에 Scopus, PsycInfo, Web of Science, ERIC, Google, Google Scholar를 체계적으로 검색(systematically searched)했습니다. 우리는 언어에 상관없이(in any language) AI가 지원하는 QDA(AI-supported QDA)를 다룬 모든 출판물(예: 원저 연구[original research], 리뷰[review], 사설[editorial])을 포함시켰습니다. 한 명의 저자(One author, D.A.C.)가 DistillerSR(Distiller SR Inc., Ottawa, Ontario, Canada)를 사용하여 논문 포함 여부 결정(article inclusion)과 데이터 추출(data extraction)을 수행했습니다. 필요에 따라 논문을 번역(translate)하기 위해 구글(Google)이 사용되었습니다. 포함 기준(inclusion criteria)을 위해 스크리닝(screened)된 483편의 논문 중, 130편이 포함 기준을 충족했습니다. 64편은 2023년 또는 2024년 1월에서 5월 사이에 출판되었습니다. 표 1(Table 1)은 주요 연구 특징(key study features)을 보고하며, 추가 디지털 부록 3(Supplemental Digital Appendix 3)은 모든 논문을 나열합니다. 이 리뷰의 한계(limitations)로는 한 명의 검토자(one reviewer)에 의한 수행, 제한적인 데이터 추출(limited data extraction), 그리고 관련 연구의 누락 가능성(possible omission) 등이 있습니다.
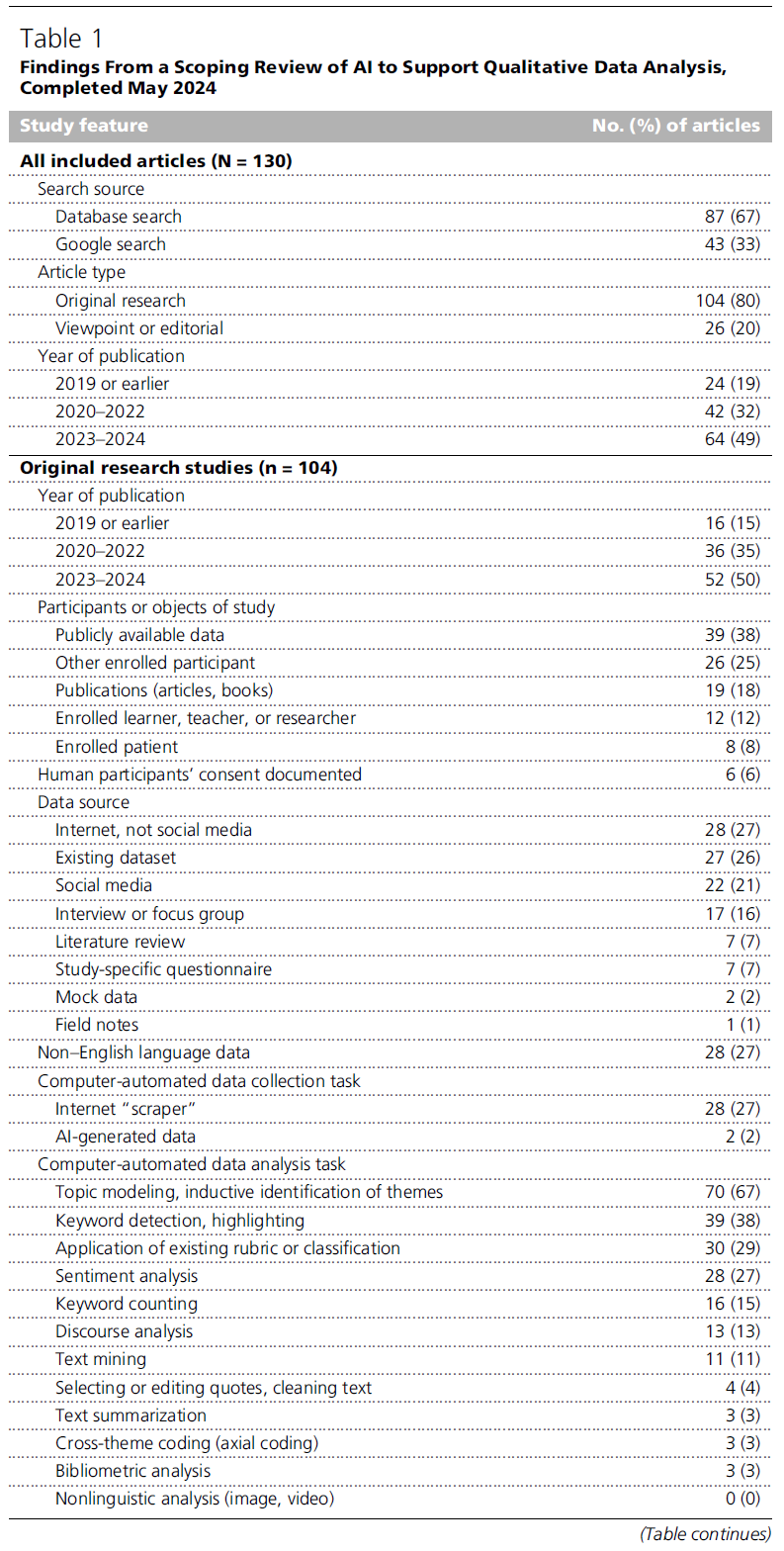

QDA에서 AI의 잠재적 약속과 함정 (Potential Promises and Pitfalls of AI in QDA)
맥락 속의 기술: 컴퓨터 보조 QDA 기능 (Technology in context: Computer-assisted QDA functions)
주제 범위 문헌 고찰(scoping review) 초기에, 우리는 컴퓨터 보조 질적 데이터 분석 소프트웨어(computer-assisted qualitative data analysis software, CAQDAS)의 역사에 대한 이해(appreciation)를 얻게 되었습니다. 1963년부터 컴퓨터는 QDA를 지원해왔으며, 현재 수십 개의 무료 소프트웨어(freeware)와 상용 도구(commercial tools)가 이용 가능합니다(예: NVivo, Atlas.ti, MAXQDA, Dedoose). 전통적인 CAQDAS 제품들은 다수의 유용한 기능(useful functions)을 제공하며, 이들 중 대부분은 일반적인 의미(usual sense)에서의 "AI"를 필요로 하지 않습니다. 다음은 그러한 기능들입니다(상세 내용은 표 2 및 다른 출처 참조):
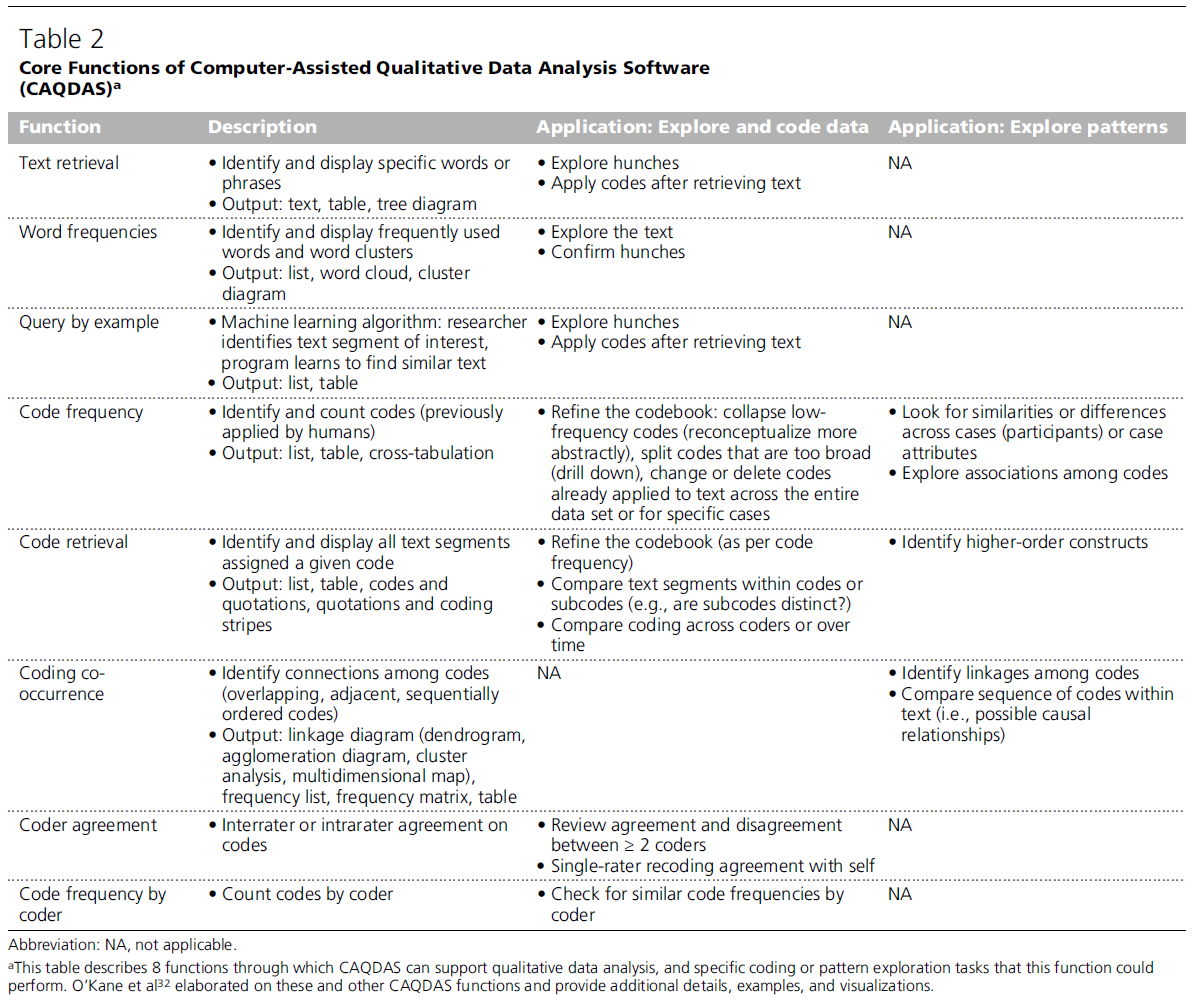
표 2 - 컴퓨터 보조 질적 데이터 분석 소프트웨어(CAQDAS)의 핵심 기능 (Core Functions of Computer-Assisted Qualitative Data Analysis Software [CAQDAS])
이 목록은 CAQDAS가 질적 데이터 분석을 지원할 수 있는 8가지 기능과 해당 기능이 수행할 수 있는 구체적인 코딩 또는 패턴 탐색 과업을 설명합니다.
- 텍스트 검색 (Text retrieval)
- 설명: 특정 단어 또는 구문(specific words or phrases)을 식별하고 표시함.
- 출력물: 텍스트(text), 표(table), 트리 다이어그램(tree diagram).
- 적용 (데이터 탐색 및 코딩): 직감(hunches)을 탐색함; 텍스트 검색 후 코드 적용.
- 적용 (패턴 탐색): 해당 없음(NA).
- 단어 빈도 (Word frequencies)
- 설명: 자주 사용된 단어 및 단어 군집(word clusters)을 식별하고 표시함.
- 출력물: 목록(list), 워드 클라우드(word cloud), 군집 다이어그램(cluster diagram).
- 적용 (데이터 탐색 및 코딩): 텍스트를 탐색함; 직감(hunches)을 확인함.
- 적용 (패턴 탐색): 해당 없음(NA).
- 예시를 통한 질의 (Query by example)
- 설명: 머신러닝 알고리즘(Machine learning algorithm): 연구자가 관심 있는 텍스트 세그먼트(text segment of interest)를 식별하면, 프로그램이 유사한 텍스트(similar text)를 찾도록 학습함.
- 출력물: 목록(list), 표(table).
- 적용 (데이터 탐색 및 코딩): 직감(hunches)을 탐색함; 텍스트 검색 후 코드 적용.
- 적용 (패턴 탐색): 해당 없음(NA).
- 코드 빈도 (Code frequency)
- 설명: 코드(이전에 인간에 의해 적용된)를 식별하고 계산함(Identify and count codes).
- 출력물: 목록(list), 표(table), 교차 분석표(cross-tabulation).
- 적용 (데이터 탐색 및 코딩): 코드북 정제(Refine the codebook): 낮은 빈도의 코드를 병합(더 추상적으로 재개념화), 너무 광범위한 코드를 분할(세분화[drill down]), 전체 데이터셋 또는 특정 사례에 대해 이미 텍스트에 적용된 코드를 변경하거나 삭제함.
- 적용 (패턴 탐색): 사례(참여자)들 또는 사례 속성(case attributes) 간의 유사점이나 차이점을 찾음; 코드 간의 연관성(associations)을 탐색함.
- 코드 검색 (Code retrieval)
- 설명: 주어진 코드가 할당된 모든 텍스트 세그먼트(text segments)를 식별하고 표시함.
- 출력물: 목록(list), 표(table), 코드와 인용문(codes and quotations), 인용문과 코딩 스트라이프(coding stripes).
- 적용 (데이터 탐색 및 코딩): 코드북 정제(코드 빈도와 동일); 코드 또는 하위 코드(subcodes) 내의 텍스트 세그먼트를 비교함(예: 하위 코드가 구별되는가?); 코더(coder) 간 또는 시간에 따른 코딩을 비교함.
- 적용 (패턴 탐색): 상위 구성개념(higher-order constructs)을 식별함.
- 코딩 동시 발생 (Coding co-occurrence)
- 설명: 코드 간의 연결(connections among codes)을 식별함(중복[overlapping], 인접[adjacent], 순차적으로 정렬된 코드[sequentially ordered codes]).
- 출력물: 연결 다이어그램(linkage diagram: 덴드로그램, 집괴 다이어그램, 군집 분석, 다차원 지도), 빈도 목록, 빈도 매트릭스, 표.
- 적용 (데이터 탐색 및 코딩): 해당 없음(NA).
- 적용 (패턴 탐색): 코드 간의 연결 고리(linkages)를 식별함; 텍스트 내 코드의 순서(sequence)를 비교함(즉, 가능한 인과 관계[causal relationships]).
- 코더 일치도 (Coder agreement)
- 설명: 코드에 대한 평가자 간(Interrater) 또는 평가자 내(intrarater) 일치도.
- 적용 (데이터 탐색 및 코딩): 2명 이상의 코더 간의 일치 및 불일치(agreement and disagreement)를 검토함; 단일 평가자의 자가 재코딩 일치도(recoding agreement with self)를 확인함.
- 적용 (패턴 탐색): 해당 없음(NA).
- 코더별 코드 빈도 (Code frequency by coder)
- 설명: 코더별로 코드를 계산함(Count codes by coder).
- 적용 (데이터 탐색 및 코딩): 코더별로 유사한 코드 빈도(similar code frequencies)가 있는지 확인함.
- 적용 (패턴 탐색): 해당 없음(NA).
- 텍스트 검색 (Text retrieval): 문서 내의 특정 단어 또는 구문(specific words or phrases)의 식별.
- 단어 빈도 (Word frequencies): 문서 내의 단어와 단어 군집(word clusters)을 세고 이를 표시하는 것.
- 예시를 통한 질의 (Query by example): 연구자가 관심 있는 텍스트 세그먼트(text segments of interest)를 식별하면, 컴퓨터가 유사한 텍스트(similar text)를 인식하도록 학습하는 것(지도 머신러닝[supervised machine learning]).
- 코드 빈도, 검색, 및 동시 발생 (Code frequency, retrieval, and co-occurrence): 인간이 문서를 코딩(code)한 후, 컴퓨터가 코드를 세거나, 주어진 코드가 할당된 텍스트 세그먼트를 표시하거나, 코드 간의 연결(connections among codes, 예: 중복되거나 인접한 텍스트)을 식별하는 것.
- 코더 일치도 (Coder agreement): 평가자들이 문서에 루브릭(rubric)을 적용할 때 얼마나 자주 일치하는지에 대한 통계적 계산(statistical computation).
AI가 지원하는 QDA는 새로운 것이 아님 (AI-supported QDA is not new)
우리는 주제 범위 문헌 고찰에서 또 다른 교훈(lesson)을 얻었습니다: QDA를 위한 AI의 사용은 새로운 것이 아닙니다(not new). 사실(True), 2022년 11월 챗GPT(ChatGPT) 출시 이후, 여러 인기 있는 CAQDAS 제품들이 AI 도구를 적극적으로 홍보(actively promoted)했습니다. 이러한 도구 중 일부는 새로운 것이지만, 많은 경우 단순히 기존 능력(existing capabilities)에 대한 홍보 우선순위를 재조정한 것(reprioritized promotion)을 반영할 뿐입니다.
사실, AI는 25년 이상 QDA를 지원하는 데 사용되어 왔습니다.
- Qualrus(현재 이용 불가)와 DiscoverText는 초기의 목적 맞춤형 도구(purpose-built tools) 중 하나였으며;
- 챗GPT 이전에 존재했던(predating) 다른 도구들로는 Wordstat, QDA Miner, Leximancer가 있습니다.
- 더욱이, 현대의 프로그래밍 플랫폼(programming platforms)은 서술형 텍스트 분석(analysis of narrative text)을 지원하는 전체 라이브러리(entire libraries)를 보유하고 있습니다(예: Python의 NLTK, SpaCy, TextBlob; R의 tm, text2vec, lda, spacyr, quanteda).
- 챗GPT 출시에 따른 소동(furor)은 입증된 QDA 기능성(demonstrated QDA functionality)이라기보다는 주로 인식(awareness), 사용자 친화성(user-friendliness), 그리고 추측되는 이점(conjectured benefits)의 결과인 것으로 보입니다.
기술이 QDA를 혁신(revolutionize)하겠다고 약속한(누군가는 위협했다[threatened]고 말할 수도 있는) 것은 이번이 처음이 아닙니다.
- 40년 전, 휴대용 카세트 녹음기(portable cassette recorder)의 발명은 유사한 격변(upheaval)을 일으켰습니다. 이전까지의 데이터 수집은 필기 노트(written notes)에 의존했고, 민족지학적 관찰(ethnographic observation)이 지배적이었습니다. 갑자기, 기술은 대화의 축어적 기록(verbatim recording)을 가능하게 했습니다.
- 이것은 새로운 분석 기법(new analysis techniques, 예: 대화 분석[conversation analysis]),
- 그에 상응하는 해결책을 필요로 하는 새로운 문제들(new problems with corresponding solutions, 예: 전사[transcription]의 필요성),
- 그리고 데이터 소싱의 새로운 위계(new hierarchies in data sourcing, 예: 민족지학을 대체하는 인터뷰와 포커스 그룹)로 이어졌습니다.
그렇긴 하지만(That said), 현재의 "AI 혁명(AI revolution)"은 과거의 변혁(transformations)과는 다를 수 있습니다.
- 첫째, 이것은 졸졸 흐르는 물(trickle)이 아니라 "해일(tidal wave)"이며, 추측(speculation), 약속(promises), 그리고 제품들(검증된 것과 시도되지 않은 것 모두)의 홍수(deluge)가 거의 하룻밤 사이에 나타나고 있습니다.
- 둘째, 사람들이 연구 커뮤니티 밖에서(outside the research community) 이 기술을 사용하고 있습니다—잠재적 연구 참여자와 연구자 자신들 모두 일상생활에서 AI를 사용합니다.
- 셋째, LLM과 다른 떠오르는 AI 도구들은 진정으로 변혁적인 잠재력(truly transformative potential)을 가진 능력들(다양한 과업 수행, 지시와 데이터 해석, 콘텐츠 생성)을 가지고 있습니다.
- 넷째, AI는 끊임없이 그리고 빠르게 진화하고 있습니다(constantly and quickly evolving, 예: 카세트 녹음기와 대조적으로). 각 반복(iteration)마다 어떤 문제들은 해결되지만, 다른 문제들은 고조되고(escalate), 새로운 문제들이 등장합니다.
- 다섯째, AI 혁명과는 별개로, 학계에서는 "출판하지 않으면 도태된다(publish or perish)"는 압력이 증가하고 있습니다. 떠오르는 AI 도구들이 빠르고 대량의 연구(rapid, high-volume research)를 촉진할 수 있다는 제안(proposition)은 이들의 수용(embrace)을 고조시킬 수 있습니다
약속: AI가 어떻게 도울 수 있는가? (The promise: How can AI help?)
AI는 특정 과업(tasks)을 더 잘 수행함으로써("존속적[sustaining]" 혁신) 그리고 해결책(solutions)을 더 접근 가능하게 만듦으로써("파괴적[disruptive]" 혁신) 도울 수 있습니다. 현대의 AI 도구들은 이용 가능한 CAQDAS 도구들이나 인간 연구자들보다 일부 QDA 과업을 더 잘(better) 수행합니다. 이는 전사(transcription)와 언어 번역(language translation)에 있어 사실인데, 현재의 AI 도구들은 비용의 일부(fraction of the cost)만으로 숙련된 인간(skilled humans)에 필적하는(rival) 산출물을 생성합니다. AI는 또한 텍스트 내의 패턴을 식별하고(identifying patterns), 발췌문을 추출하고(extracting excerpts), 요약을 생성하는(generating summaries) 데 있어 전통적인 CAQDAS를 넘어설 수도 있습니다.
다른 과업들에 대해서는, AI가 인간이나 기존 도구들보다 실제로 더 나쁠(worse) 수도 있습니다. 그러나, AI는 여전히 파괴적 혁신(disruptive innovation)을 통해 중요한 기여(important contributions)를 할 수 있습니다. 어떤 파괴적 혁신이든, 현재의 성능(current performance)은 다른 (이상화된) 접근법들보다 덜 효과적(less effective)이지만, 새로운 접근법은 더 큰 사용자 집단에게 훨씬 더 접근 가능(more accessible)합니다. 비용(cost), 훈련(training), 언어(language)와 같은 장벽(barriers)을 낮춤으로써 달성된 그러한 향상된 접근성(enhanced accessibility)은 감소된 효과성(reduced effectiveness)을 무색하게 만들고(overshadows) 순 승리(net win)라는 결과를 낳습니다. 챗GPT(ChatGPT)와 같은 거대 언어 모델(LLMs)들은 비록 현재로서는 많은 목적 맞춤형 CAQDAS나 AI 접근법들보다 덜 효과적일지라도, 언어, 교육, 경제, 문화의 장벽을 초월하는(transcends) 지식과 전문성의 전 지구적 민주화(global democratization)를 가능하게 할지도 모릅니다.
귀납적 및 연역적 텍스트 분석을 위한 AI (AI for inductive and deductive text analysis)
QDA는 흔히 귀납적 분석(inductive analysis)—질적 데이터로부터 새로운 코드(novel codes)와 패턴을 개방적이고 탐색적으로 식별하는 것(open, exploratory identification)—을 포함합니다.
- 비록 많은 연구자가 이 과업을 즐겁게 생각하지만, 그럼에도 불구하고 이는 노력이 들고(effortful), 어렵고, 지저분하며(messy), 시간 소모적입니다.
- 연구자들은 향상된 효율성(enhanced efficiency)을 바랄 뿐만 아니라, 일부는 불완전한 연구(imperfect research)에 대한 죄책감(guilt)이나 두려움(분석을 "제대로" 했는가?)을 경험하거나, 혹은 자신의 관점(viewpoint: 렌즈[lens], 위치성[positionality], 또는 개인적 관점[personal perspective])이 무심코 중요한 무언가를 놓치거나 오해하게 만들었는지(inadvertently miss or misinterpret) 궁금해합니다.
- 그들은 데이터를 조직화(organizing) 및 시각화(visualizing)하고, 주제를 강조(highlighting themes)하며, 새로운 통찰을 식별(또는 확인)하는 데 있어 지원(support)을 원합니다.
QDA는 또한 흔히 연역적 분석(deductive analysis)—정의된 코드(defined codes: 선험적으로[a priori] 선택되거나 초기 단계에서 귀납적으로 식별된)를 서술형 데이터셋(narrative dataset)에 적용하는 것—을 포함합니다.
- 이 또한 지루하고(tedious) 시간 소모적일 수 있습니다.
- 게다가, 많은(전부는 아니지만) 연구 프로토콜은 인간 코더들이 코드에 일치(agree on codes)할 것을 요구하는데, 이는 신뢰도(reliability), 편향(bias), 독립성(independence), 협업(collaboration), 갈등 탐지(conflict detection), 합의 구축(consensus building)에 대한 우려를 제기합니다.
- 일부 저자들은 또한 연구 팀 내에 존재하는 거의 피할 수 없는 위계(inevitable hierarchies)를 고려할 때 합의가 냉철할(dispassionate) 수 있는지 의문을 제기합니다.
우리는 QDA 연구자들이 AI에게 데이터셋을 맡기고(take their dataset, 혹은 더 나아가 데이터셋을 자동으로 수집하여) 연구 질문에 답하도록 자율적으로 분석(autonomously analyze)하게 요청하고 싶은 유혹(lure)을 느낄 수 있음을 이해합니다(appreciate). 이것은 위에 나열된 힘들고 지루한 단계들을 우회하고(bypass) 잘 만들어진 최종 답변(final well-crafted answer)을 내놓을 것입니다. 그러나, 우리는 이것이 가능할지라도, 실제로는 바람직하지 않다(undesirable)고 주장합니다. 이 "이상적인" 세계는 유토피아적이라기보다는 디스토피아적(dystopian)입니다.
- 그것은 순진하게도(naively) AI에게 책임을 맡겨(puts AI in charge), 인간을 루프에서 제거(removing the human from the loop: 통제와 감독[control and oversight]을 포기함)합니다.
- 그것은 또한 연구자를 분석으로부터 거리 두게(distances) 합니다—그들은 더 이상 데이터에 몰입(immersed)하지 않고, 참여자들과 협력하여 의미를 공동 구성(co-constructing meaning)하지 않으며, 해석을 맥락화(contextualize interpretations)할 능력이 떨어지게 됩니다.
- 그러나, 우리가 단점(disadvantages)을 완화하면서 장점(advantages)을 활용한다면, AI는 그러한 분석에 대해 실질적인 지원(support)을 제공할 수 있습니다.
AI는 귀납적 분석(텍스트에서 코드와 주제를 추론[inferring])과 연역적 분석(기존 코드를 텍스트에 적용) 모두를 지원할 수 있지만, 한계(limitations)가 있습니다.
- 놀랍게도, 일부 AI 도구들은 키워드 식별 및 계산(keyword identification and counting), 코드 검색(code retrieval), 데이터 시각화(data visualization)와 같은 "기초적인(basic)" CAQDAS 과업들을 잘 수행하지 못합니다(do poorly). 예를 들어, 챗GPT(ChatGPT)와 같은 현재의 LLM들은 계산이나 다단계 지시(multistep instructions)에 어려움을 겪습니다(struggle).
- 대조적으로, LLM은 텍스트 요약 생성(generating summaries)에 탁월합니다(excel). LLM과 토픽 모델링(topic modeling: 자주 함께 등장하는 단어들을 식별하는 것)과 같은 다른 AI 접근법들은 귀납적으로 잠재적 주제(potential themes)나 코드를 식별하고 해당하는 텍스트 발췌문을 연결할 수 있습니다.
- AI는 주어진 텍스트의 특징(features)을 분석할 수 있습니다; 예를 들어, Python과 R의 도구들은 정확한 감성 분석(sentiment analysis: 진술이 감정적으로 긍정적인지 부정적인지 결정하는 것)을 제공합니다. AI는 지정된 코딩 루브릭(coding rubric)과 일치하는 텍스트 영역을 식별할 수 있습니다(연역적 분석). 일부 질적 연구는 비텍스트 데이터(nontext data: 예, 이미지, 비디오)를 분석하는데, AI는 잠재적으로 이것 또한 도울 수 있습니다.
이론적으로, AI는 주제나 테마를 가로지르는 분석(축 코딩[axial coding])으로부터 유용한 통찰을 추론(infer)할 수 있습니다; 그러나 이 과업은 경험적 데이터(empirical data)가 연구 맥락(study context), 문제 공간(problem space), 관련 이론(relevant theory), 개인적 경험(personal experience)과 병합될 것을 요구합니다. 그러한 복잡성을 고려할 때, 우리는 축 코딩이 당분간(for the foreseeable future) 인간의 영역(purview)으로 남을지 궁금해합니다.
우리는 "전통적인" CAQDAS와 AI 사이의 흐릿한 경계(blurry line)를 인정합니다. 과업이 점차 더 복잡해짐에 따라(successively more complex: 예, 키워드 계산, 텍스트 마이닝, 의미론적 분석[semantic analysis], 감성 분석, 주제 분석, 주제 간 추론, 이론의 통합, 깊은 이해의 점진적 난해함), "지능(intelligence)"에 대한 요구는 꾸준히 증가합니다.
(오직) 팀의 일원 ([Only] a member of the team)
이러한 각 과업에 대해, AI는 팀의 필수적인 일원(integral member)으로 간주될 수 있지만—오직 일원일 뿐(only a member, 팀 전체가 아님), 게다가 주니어 일원(junior member)입니다. 모든 AI 전반에 걸쳐 보편적인—"인간을 루프 안에(human in the loop)" 두라는 강력한 권고(strong admonition)는 유효합니다(holds true). 사실(Indeed), 우리는 인간이 루프를 책임져야 한다(remain in charge)고 주장합니다. 대부분의 질적 연구는 한 명 이상의 연구자를 포함하며, AI가 지원하는 QDA에서 AI는 연구 책임자(primary investigator)라기보다는 연구 보조원(research assistant)으로 보는 것이 가장 좋습니다.
- 한 저자가 언급했듯이, AI는 "연구자의 판단(judgement), 성찰성(reflexivity), 창의성(creativity), 경험(experience), 세계관(worldviews), 문화적 신념(cultural beliefs), 직관(intuitions), 그리고 편향(biases)조차" 대체할 수 없습니다.
- 또 다른 저자는 논평했습니다, "분석을 아웃소싱(Outsourcing)하는 것은... 연구 품질에 영향을 미치고... [연구자들에게서] 데이터와의 정서적 연결(emotional connection)—친밀감(intimacy), 자부심(pride), 주인의식(ownership)—을 앗아갑니다(robs)."
- 그러나, AI는 "가상 동료(virtual colleague), 초심자(novice)... 그럼에도 유용한 기여를 할 수 있는" 역할을 수행할 수 있습니다.
- AI의 기여가 제한적임을 인정하며, 또 다른 저자는 "불완전한 제안(imperfect suggestions)조차 도움이 될 수 있다"고 강조했습니다.
이론 주도적 QDA는 어떠한가? (What about theory-driven QDA?)
일부 질적 분석은 결과(result, 산출물[product])로서 이론과 개념적 틀(conceptual frameworks)을 개발합니다; AI는 이론 개발적(theory-developing)인 귀납적 또는 연역적 분석을 분명히 지원할 수 있습니다. 대조적으로, 이론 주도적(theory-driven) 분석은 특정 이론이나 틀을 특정 현상(phenomenon)을 연구하기 위한 렌즈(lens)로서 사용합니다. 후자의 접근법에서, 이론은 연구 질문을 정의하고, 관련 데이터의 선택과 수집을 안내하며, 데이터를 해석(interpreting)하는 데 중요한 역할을 할 수 있습니다.
- 해석 단계(interpretive phase)에서, 연구자는 이론이 제공하는 개념(theory-provided concepts)이라는 렌즈를 통해 데이터를 끊임없이 심문(interrogates)합니다. 그들의 목적은 현상에 대해 가능한 모든 것을 배우는 것이 아니라, 오히려 이 렌즈를 통해 확대되고 초점이 맞춰진(magnified and focused) 현상의 측면들을 더 잘 이해하거나, 렌즈 자체를 정제(refine)하는 것입니다.
AI가 그러한 분석을 수행하려면,
- 먼저 이론의 핵심 요소(key elements)를 학습해야 하고,
- 그런 다음 이 렌즈를 통해 데이터를 해석할 능력(capacity to interpret: 즉, 데이터가 그 이론의 특정 교리[tenet]를 지지하거나 지지하지 않는 사례를 찾는 것)을 가져야 합니다.
이것은 어려울(challenging) 뿐만 아니라, 현재의 AI 모델들이 이론의 요소를 통합하기 위해 원래의 데이터를 조작(fabricate)하거나 수정(modify)할("환각[hallucinate]") 위험이 있습니다. 비록 미래의 AI 기술들이 이론 주도적 QDA를 지원할 수 있을지라도, 현재로서는(for the moment) 우리는 그것이 주로 인간의 통찰(predominantly human insights)을 필요로 한다고 믿습니다.
구체적인 AI-QDA 적용과 접근법 (Specific AI-QDA applications and approaches)
AI 지원 분석 (AI-supported analysis). 저자들은 몇 가지 AI 지원 QDA 접근법(AI-supported QDA approaches)에 대해 상세히 설명해 왔습니다(elaborated). 아래에서 우리는 4가지 구체적인 접근법(주제 분석[thematic analysis], 계산적 근거 이론[computational grounded theory], 담론 분석[discourse analysis], 대규모 데이터셋 분석[analysis of large datasets])과 QDA를 지원하는 여러 다른 AI 기능들을 다룹니다.
주제 분석 (Thematic analysis). 우리가 찾은 문헌은 브라운과 클라크(Braun and Clarke)의 주제 분석 접근법을 자주 인용했습니다. 다음의 단계들과 그에 상응하는 AI의 기여(AI contributions)는 다음과 같습니다:
- 데이터와 친숙해지기 (Familiarize with data): 텍스트 또는 여러 텍스트의 요약 생성(generate a summary); 전사본(transcripts) 정리를 지원함.
- 코드 생성 (및 적용) (Generate [and apply] codes): 텍스트로부터 후보 코드(candidate codes)를 귀납적으로 식별함(inductively identify); 후보 코드 목록을 정제(refine: 압축[condense], 병합[merge])함; 코드의 설명(정의)을 생성하고 코딩을 뒷받침할 예시 인용문(example quotes)을 식별함; 코딩 루브릭(coding rubric)을 텍스트에 적용함.
- 후보 주제 구성 (Construct candidate themes): 더 긴 코드 목록과 코드 설명으로부터 주제 목록(list of themes)을 생성함.
- 후보 주제 검토 (Review candidate themes): 후보 주제를 수집되고 코딩된 텍스트 세그먼트(text segments)와 대조(contrast)함 (모든 세그먼트가 주어진 주제와 관련이 있는지, 그리고 이 세그먼트들의 모든 중요한 개념이 해당 주제에 반영되었는지 확인함); 코드나 텍스트 세그먼트가 두 개 이상의 주제에서 얼마나 자주 나타나는지 탐색(explore)함 (일치하는 세그먼트는 고유하지 않은 주제[nonunique themes]를 시사함).
- 주제 정의 및 명명 (Define and name themes): 각 주제에 대한 잠정적 정의(tentative definitions)와 라벨을 생성함.
- 보고서 작성 (Produce the report): 각 주제를 예증(illustrate)할 인용문을 식별함; 선택된 인용문을 편집(단축[shorten])함; 보고서 작성 자체를 지원함 (단, 과학적 글쓰기[scientific writing]에 AI를 사용할 때의 중요한 윤리적 고려사항[important ethical considerations]에 유의).
미묘한(nuanced) 인간 분석의 필요성을 강조하며, 브라운과 클라크는 "코딩 신뢰도(coding reliability)" 주제 분석과 "성찰적(reflexive)" 주제 분석을 구별했습니다.
- 코딩 신뢰도 접근법은 코딩을 하나의 과정(process)으로 강조하고 코딩의 정확성(accuracy)을 우선시합니다(코더의 주관성[coder subjectivity] 제한). 주제는 일반적으로 연구자에 의해 "발견되는(discovered)" 토픽이나 토픽 요약을 나타내며, 이것들은 흔히 데이터 수집 질문들과 밀접하게 매핑됩니다. 많은 AI 중심 접근법들—자동화된(automated), 정형화된(routinized), 그리고 토픽을 식별하기 위해 단어 동시 발생(co-occurring words)에 의존하는—은 코딩 신뢰도와 일치할 것입니다.
- 브라운과 클라크가 우월하다고 주장하는 성찰적 주제 분석(Reflexive thematic analysis)은 인간이 "데이터와의 깊고 장기적인 관여(deep and prolonged engagement)"에 몰입할(immerse) 것을 요구합니다.
- 인간이 주 도구(primary tool)이며, 주관성(subjectivity)은 문제가 아니라 자원(resource)입니다(다른 저자가 말했듯이, "불확실성(Uncertainty)은 질적 연구에서 버그가 아니라 기능(feature)입니다.").
- 주제는 토픽이나 요약이라기보다는 의미의 패턴(patterns of meaning)입니다; 그것들은 데이터가 해석됨에 따라 진화(evolve)하며 연구자에 의해 생산되는(produced) 것이지 ("발견되거나[discovered]" "식별되는[identified]" 것이) 아닙니다.
- 데이터 분석은 예술(art)이며, 창의성(creativity)과 뜻밖의 발견(serendipity)이 소중히 여겨지고, 연구자의 주관성과 성찰성(reflexivity)이 성공의 열쇠입니다. AI가 이러한 형태의 QDA를 확실히 지원할 수는 있겠지만, 가정(assumptions), 과정(processes), 그리고 AI의 역할은 매우 다를 것입니다.
계산적 근거 이론 (Computational grounded theory). 근거 이론(Grounded theory)은 주어진 현상(예: 사회적 경험)의 어떤 측면을 설명하는 모델이나 이론을 귀납적으로 식별(inductively identify)하고자 합니다. Nelson은 AI를 사용하여 근거 이론 분석을 대규모 데이터셋으로 확장하고 과정의 감사 가능성(auditability)과 투명성(transparency)을 높이는 "계산적 근거 이론(computational grounded theory)"을 위한 모델을 제안했습니다. 그녀의 3단계 모델(다소 실증주의적[positivist] 또는 후기 실증주의적[postpositivist] 패러다임을 반영하는)은 "인간이 제공하는 텍스트를 전체론적으로 해석하는 우월한 능력(superior abilities to interpret text holistically)을 보존(preserv[es])하면서, 컴퓨터 보조 방법의 공식적 엄격성(formal rigor), 신뢰도(reliability), 재현성(reproducibility)을 통합(incorporat[es])"합니다.
- 1단계, 패턴 탐지(pattern detection)는 "비지도 머신러닝(unsupervised machine learning)과 단어 점수(word scores) 같은 기법을 사용하여 연구자들이 데이터에서 새로운 패턴(novel patterns)을 보도록 돕는 텍스트의 귀납적 계산 탐색(inductive computational exploration)"을 포함합니다. 단어 비율 분석(word proportion analysis)과 토픽 모델링(topic modeling, Python과 R에서 이용 가능) 같은 AI 기법은 "복잡하고 지저분한 텍스트를 더 단순하고 해석하기 쉬운 단어 목록이나 네트워크로 축소(reduc[e])... 결과물은 여전히 인간에 의해 해석되어야 하지만, 계산적 탐색 분석은 연구자가 이전에 고려하지 못했던 범주(categories)를 제안할 수 있고... 연구자가 자신의 편향(biases)을 피하도록 도울 수 있습니다."
- 2단계, 패턴 정제(pattern refinement)는 "[인간의] 질적 심층 읽기(qualitative deep reading)를 통해 데이터와의 해석적 관여(interpretive engagement)로 돌아갑니다." "계산적으로 유도된 심층 읽기(computationally guided deep reading)"에서, 연구자는 1단계에서 식별된 패턴의 타당성(plausibility)을 확인하고, 인간의 해석을 추가하며, "데이터에 대한 인간적이고 전체론적인 읽기(human, and holistic, reading)에 더 잘 맞도록" 패턴을 수정(modifies)합니다.
- 3단계, 패턴 확인(pattern confirmation)은 "추가적인 계산 및 자연어 처리(natural language processing) 기법을 사용하여 귀납적으로 식별된 패턴을 평가(assesses)합니다." 이것은 "이러한 패턴들이 말뭉치(corpus) 전체에 걸쳐 유지되는지 연역적으로 테스트(deductively tests)"합니다.
담론 분석 (Discourse analysis). 담론 분석(Discourse analysis)은 언어가 사회적 현실(social realities)과 권력 역학(power dynamics)을 형성하는 방식을 비판적으로 검토합니다(critically examines). Jacobs와 Tschötschel은 AI가, 특히 헤게모니(hegemony)—다른, 덜 특권적인 해석들보다 어떤 말하기와 행동 방식을 더 관습적(conventional)이고, 용인 가능하며(acceptable), 겉보기에 논리적(seemingly logical)인 것으로 만드는 "세상을 이해하는 지배적이고(dominant), 정상화된(normalized) 방식"—에 대한 연구를 어떻게 지원할 수 있는지 설명합니다. 따라서, 특정 단어는 다른 맥락과 다른 사람들에게 다른 의미를 가질 수 있습니다(다의성[polysemy]의 개념).
- 그들은 토픽 모델링(topic modeling)이라는 AI 기법이 인간 의사소통 과정을 역전시킨다(reverses)고 관찰합니다.
- 말하거나 쓸 때, 인간은 먼저 주제(topic)를 선택하고, 말하는 방식(양식[mode])을 선택한 다음, 구체적인 단어(specific words)를 선택합니다.
- 대조적으로 토픽 모델링은 구체적인 단어를 분석하고 "말뭉치 전체에 걸친 단어의 관찰된 분포(observed distributions)를 사용하여 공통적으로 사용되는 비배타적 군집(non-exclusive clusters)—각각이 특정 [주제]에 대한 화법의 양식을 나타내는—을 추론(infer)"합니다.
- 토픽 모델링은 "각 단어의 주제별 의미(topic-specific meaning)와 각 주제의 맥락적 의미(contextual meaning)"를 포착합니다. 즉, 텍스트 내 의미의 다의성과 관계적 본성(relational nature)을 독특하게 강조할 수 있으며—이는 담론 분석의 원칙과 메타 이론적(meta-theoretical) 및 인식론적(epistemological) 적합성을 나타냅니다.
이 저자들은 (1) 잘 구획된 주제와 단일 장르(single genre)의 텍스트에 집중하고 (2) 많은(large) 수의 주제를 요청하는 토픽 모델링을 사용하는, AI 지원 담론 분석 접근법을 제안합니다. 결과적으로, "대부분의 주제는 더 이상 말뭉치에서 다루는 다양한 테마나 주제를 나열하는 것이 아니라, 대신 언어 사용의 더 세밀하고 미묘한 측면(fine-grained and nuanced aspects)을 포함할 것입니다."
그들은 헤게모니 연구에 있어 토픽 모델링의 독특한 이점을 강조합니다. 전통적인 담론 분석은 헤게모니가 무너지는 사례를 찾습니다. 대조적으로, 대규모 데이터셋을 이용한 토픽 모델링은 "우리가 소수의 매우 통찰력 있는 사례들을... 헤게모니가 문제없이(without a hitch) 재생산되는 수많은 정상적이고(normal), 예외적이지 않으며(unexceptional), 개별적으로는 유익하지 않은(individually uninstructive) 사례들로 보완(complement)하게 해줍니다." 연구자는 "정상적인 것으로 간주될 수 있는 것에 대한 선험적 가정(a priori assumptions) 없이 말뭉치 전체를 탐색"할 수 있습니다. "이것은 우리가 그렇지 않았으면 발견하지 못했을 루틴과 정상화된 논리(normalized logics)를 찾는 데 도움을 줍니다."
- 비유하자면(By analogy), 전통적인 담론 분석은 희귀한 검은 백조(예외)의 검은색을 사용하여 흰 백조(헤게모니)의 하양을 눈에 띄게 만듭니다. AI-QDA 토픽 모델링은 99%의 흰 백조(헤게모니 그 자체)에 대한 더 깊은 이해를 가능하게 합니다.
1. 교통 흐름의 비유 (교통사고 vs. CCTV 분석)
2. 건강 검진의 비유 (질병 vs. 빅데이터)
3. 물고기와 물의 비유 (물 밖으로 튀어 오름 vs. 물속 생활)
4. 공기 청정기의 비유 (먼지 센서 vs. 대기 분석)
|
대규모 데이터셋 분석 (Analysis of large datasets). QDA의 노력과 복잡성은 데이터셋의 크기에 따라 기하급수적으로(exponentially) 증가합니다. AI는 확장 가능(scalable)하여, 매우 큰 실제 데이터셋(real-world datasets)의 효율적 분석을 가능하게 합니다. 이 기능은 짧은 텍스트(short texts)를 대량으로 분석할 때 특히 유용합니다(예: 대규모 강의 평가의 코멘트, 국가적 설문조사, 소셜 미디어 게시물, 제품 리뷰, 뉴스 헤드라인). 다른 대규모 데이터셋은 출판된 저작물(예: 저널이나 신문 기사, 책)이나 긴 인터뷰로 구성될 수 있습니다. (참고로, LLM은 유한한 컨텍스트 윈도우(context window)—응답을 생성하는 동안 처리할 수 있는 정보[데이터와 지시사항을 합친]의 총량—를 가지고 있어, 현재로서는 제한적인 확장성[limited scalability]을 가짐 [비록 이것이 빠르게 증가하고 있지만]. 맞춤형 기법[Bespoke techniques, 예: Python이나 R 사용]과 목적 맞춤형 상용 QDA 제품들은 덜 제약적입니다.)
- 대규모 표본 외에도, 지저분한 실제 데이터셋(messy, real-world datasets)의 장점은 다음을 포함합니다:
- 자기 보고(self-report: 예, 의도된 사용, 인터뷰 진술) 대신 참여자의 실제 행동(real behaviors: 예, 실제 소셜 미디어 게시물, 실제 웹사이트 사용)을 포착,
- 실험실 환경 대신 실제 사회적 환경의 맥락을 보존,
- 다양한 참여자 특성에 걸친 샘플링, 그리고
- 데이터 및 도구의 연구 협력과 공유 장려.
- 진정성 있는 맥락(authentic context)은 또한 부채(liability)입니다:
- 데이터가 일반적으로 연구 목적으로 의도되지 않았기 때문에 데이터 품질이 가변적(variable)이고,
- 타당성 증거(validity evidence)가 일반적으로 이용 불가능하며,
- 핵심 정보와 관계없는 정보(salient and extraneous information)가 흔히 뒤얽혀 있습니다.
- 추가적으로, 소스에서 정보를 추출하는 것이 어려울 수 있습니다(비록 AI가 "스크래퍼[scraper]" 도구와 데이터 클리닝 등으로 이를 도울 수 있지만).
- 또한 문제가 되는 윤리적 이슈(problematic ethical issues)가 있으며, 우리는 아래에서 이를 상세히 설명합니다.
QDA를 지원하는 다른 AI 기능들 (Other AI functions to support QDA)
AI는 공식적인 분석(formal analysis) 이외의 방법으로 QDA를 지원할 수 있습니다.
연구 컨설턴트로서 조언 제공 (Offering advice as a research consultant).
- AI 대화형 에이전트(AI conversational agents, 예: LLM)는 "연구 컨설턴트(research consultant)"의 기능을 포함하여 전통적인 CAQDAS를 넘어서는 기능을 제공합니다. 연구자가 경험 많은 인간 동료와 아이디어를 상의할(bounce ideas off) 수 있는 것처럼, 대화형 에이전트는 잠재적 방법론(potential methods), 개념적 틀(conceptual frameworks), 문헌 출처(literature sources), 구조적 위치화(structural positioning), 성찰성(reflexivity), 그리고 한계점(limitations)을 포함하여 연구 계획(study planning) 및 해석(interpretation)에 관한 제안을 위해 질의(queried)될 수 있습니다. 당연히, AI와 인간 모두의 제안은 기계적 수용(rote adoption)보다는 사려 깊은 고려(thoughtful consideration)를 필요로 합니다.
데이터 수집 및 선택 (Data collection and selection).
- 많은 연구는 소셜 미디어, 기타 인터넷 사이트, 지역 아카이브(local archives)와 같은 공공 및 민간 사이트에서 데이터를 찾습니다. 컴퓨터 구동 "스크래퍼(scrapers)"는 그러한 출처에서 데이터를 수집합니다. AI는 관련 출처(relevant sources)를 식별하고, 다수의 출처로부터 데이터를 취합(pool)하며, 주변 텍스트(peripheral text)로부터 핵심 인용문(salient quotations)을 추출하고, 분석을 위해 데이터를 조직화(organize)하는 데 도움을 줄 수 있습니다.
- AI는 표집(sampling, 즉 더 큰 모집단이나 말뭉치[corpus]로부터 풍부한 데이터와 독특한 통찰을 기여하는 참여자나 데이터의 하위 집합[subset]을 선택하는 것)을 도울 수 있습니다. 질적 연구에서의 표집은 "편의(convenient)" 표집(가장 덜 선호되는 접근법)이거나 무작위(random)일 수 있지만, "의도적(purposeful)" 표집이 종종 이상적입니다. 의도적 표집은 공통적이거나 중심적인 주제보다는 의도적으로 광범위한(전체적인) 범위의 반응과 패턴을 나타내는 데이터 소스(예: 인터뷰 참여자, 데이터 스크래핑을 위한 웹사이트)를 찾습니다. AI는 의도적 표집을 안내하는 데 유용할 수 있는 데이터 소스의 특성(characteristics)을 식별하고, 이러한 특성과 일치하는 참여자나 소스를 식별하는 데 도움을 줄 수 있습니다.
- AI는 또한 대규모의 기존 데이터셋에서 핵심 정보를 선택할 수 있으며, 단순히 중심(center)뿐만 아니라 가장자리 및 불일치 사례(edge and disconfirming cases, AI 분석에서의 "꼬리와 치우침[tails and skews]")를 의도적으로 표집할 수 있습니다. 대안적으로, AI는 인간이 다룰 수 있는 것보다 훨씬 더 큰 모집단이나 데이터셋의 분석을 지원할 수 있습니다; 이 경우, 규범(norms, 중심 경향[central tendencies])과 가장자리(예외[exceptions]) 모두가 대표될 수 있습니다.
인터뷰 지원 (Interview support).
- AI의 강력한 언어 능력(language skills)은 연구자가 유창하지 않은 언어를 사용하는 참여자들과의 인터뷰를 위한 실시간 번역(live translation)을 지원할 수 있습니다. 이것은 전 세계적으로 소외된 및 소수자 집단(marginalized and minority populations)과의 연구를 크게 확장할 수 있습니다. AI는 또한 코더 훈련(coder training)이나 지도 머신러닝(supervised machine learning)을 위한 모의 인터뷰 전사본(mock interview transcripts)을 생성할 수 있습니다.
데이터 준비 (Data preparation).
- AI 기반 언어 번역 도구(language translation tools)는 수년 전부터 Google, Microsoft 및 다양한 상용 제품에서 이용 가능했습니다. 챗GPT(ChatGPT)와 같은 새로운 도구들과 함께, 이것들은 원본 문서(source documents)와 인터뷰 전사본의 빠르고 쉬운 번역을 지원합니다. 우리는 주제 범위 문헌 고찰을 위해 여러 논문(스페인어, 타갈로그어, 중국어)을 번역하는 데 AI를 사용했습니다.
- AI는 또한 데이터 정제(data cleaning: 부정확하고, 일관성 없고, 손상되고[corrupted], 잘못된 형식의, 중복된 데이터 수정)를 도울 수 있습니다.
오디오 녹음의 전사 (Transcription of audio recordings).
- AI는 전사(transcription)의 부담을 덜어줄 뿐만 아니라, 실시간(in real time) 전사를 지원하여 세션 직후(또는 심지어 도중에) 전사본을 이용할 수 있게 합니다. 이것은 데이터 수집과 데이터 분석을 통합(integrating)하려는, 자주 추구되지만 거의 실현되지 않는 목표의 달성을 크게 촉진합니다. AI 전사는 연구자가 대화가 생생할(fresh) 때 전사본을 검토할 수 있게 하며, 추가적인 인상(additional impressions)을 정제하고(refine), 공고히 하고(solidify), 문서화할 전례 없는 기회를 만듭니다. 일부 질적 접근법에서는, 연구 참여자가 수정(correct), 수정(amend), 그리고 심지어 추가적인 아이디어로 부연 설명(elaborate)해달라는 요청과 함께 전사본 사본을 받는 것이 적절할 수 있습니다. 시기적절한 전사는 인터뷰 가이드(interview guide)의 시기적절한 수정을 추가로 지원합니다. 그러나, 전사 과정에서 연구자를 제거하는 것에는 위험(risk)이 따릅니다(아래 참조). 이 논문을 준비하면서, 우리는 유튜브 비디오로만 이용 가능한 2개의 웨비나를 전사하는 데 AI를 사용했습니다.
이미지 및 비디오 분석 (Analysis of images and video).
- AI는 또한 1차 데이터 소스(primary data source)로서 이미지와 비디오를 준비하고 나중에 분석하는 것을 돕는 데 있어 가능성(promise)을 보여줍니다.
인간-인간 협업 (Human-human collaborations).
- 한 연구 그룹은 인간-인간 코딩 팀(human-human coding teams)이 직면한 과제들을 식별하기 위해 인터뷰를 수행했는데, 여기에는 평가자 독립성(rater independence) 보존, 평가자 조정(rater calibration) 및 코딩 해석의 변동(variation), 사전 정의된 코드북(predefined codebook)의 진화 및 정제, 그리고 갈등 해결(conflict resolution)이 포함되었습니다. 그 후 그들은 이러한 과제들을 완화(mitigate)하기 위해 새로운 AI 지원 시스템을 개발하고 테스트하여 어느 정도 성공을 거두었습니다.
함정: QDA를 위한 AI에 대한 우려 (Pitfalls: Apprehensions about AI for QDA)
문헌 검토와 팀 내 논의(within-team discussions)를 통해, 우리는 AI 지원 QDA에 대한 몇 가지 우려(concerns)를 확인했습니다.
연구자들은 그들이 사용하는 기술—즉 "내부 작동 원리(under the hood)"—를 이해해야 합니다. 가장 중요한 것은, AI는 확률적(probabilistic)이며 의미를 생성하는 것(meaning-making)이 아니라는 점입니다. 기본적으로, AI는 빈도가 높은 사건(high-frequency events)과 광범위한 패턴에 초점을 맞춥니다; 명시적인 계획(explicit planning) 없이는, 가장자리 사례(edge cases), 예외(exceptions), 불일치 사례(disconfirming examples), 희귀한 사건(rare events)을 놓칠 것입니다. 더욱이, "인공지능"은 능력, 강점, 한계가 매우 다양한 다수의 도구와 기법을 포괄합니다. 우리는 연구자들이 이용 가능한 다양한 옵션(range of options)을 충분히 고려하지 않고 편리하거나 인기 있는 도구(현재의 LLM과 같은)에만 집중할까 봐 우려합니다. LLM과 다른 생성형 AI 도구들은 강력하지만 상당한 한계(significant limitations)를 가지고 있습니다(부록 1), 여기에는
- 제한적인 맥락 이해(limited contextual understanding),
- 불완전한 지식 기반(incomplete knowledge base),
- 사실적으로 정당화되지 않은 응답("환각[hallucinations]"),
- 편향된 응답(biased responses),
- 제한된 컨텍스트 윈도우(limited context window),
- 빈약한 추론 능력(poor reasoning capabilities)이 포함됩니다.
한 저자가 언급했듯이, LLM은 유창한 언어의 "소리를 내지만(pronounce the sounds)" 의미를 이해하거나 불어넣지는(imbue) 못합니다. 다른 AI 도구들(예: 상용 제품에 내장된 도구, Python과 R의 툴킷)은 그들만의 한계를 가지고 있습니다.
AI는 게으르고, 세련되지 못한 분석(lazy, unsophisticated analysis)을 초래할 수 있습니다. 컴퓨터 통계 패키지들은 정량적 연구에서 유사한 문제를 일으켰습니다:
- 사용자 친화적이고 쉽게 접근 가능한 도구들은 가정(assumptions), 전제 조건(preconditions), 적절한 적용(appropriate applications), 해석에 대한 훈련이나 지도가 부족한 사용자들의 손에 고급 분석 기법을 쥐어주었습니다. 이는 잘못된 통계 검정의 사용, 가정 충족 실패, 세련되지 못한 탐색적 검정("p-해킹[p-hacking]"), 결과의 오해석(misinterpretation)으로 이어집니다. 현대의 CAQDAS 패키지들이 이미 QDA를 접근 가능하게 만드는 것을 목표로 하고 있지만, AI는 이를 훨씬 더 쉽게 만들며—따라서 문제의 범위를 확장합니다. 연구자들은 이러한 강력한 도구들에 대한 세련되지 못한("무작정 대입하기[plug and chug]") 적용이나 의존을 피해야 합니다.
- AI 팀원(AI teammate)에 대한 의존은 또한 인간-인간 QDA 협업(human-human QDA collaborations)을 줄여, 잠재적으로 분석의 미묘함(nuance)에 부정적인 영향을 미칠 수 있습니다.
- 쉬운 답변은 위험할 수 있습니다: 좋은 답변(완전히 발전된 통찰)은 좋고, 유용하지 않은 답변은 감지하기 쉽지만, 빠른 "그럭저럭 괜찮은(good-enough)" 답변은 연구자가 의미에 대한 더 심층적인 탐색(more in-depth search for meaning)을 하지 못하게 주의를 분산시킨다면 위험할 수 있습니다.
- 피상적인 답변(superficial answer)은 형식적인 만족감(perfunctory satisfaction)을 자극하여 데이터에 대한 더 깊은 탐구를 미연에 훼방(forestall)할 수 있습니다. 세련되지 못한 분석은 또한 예외(exceptions)에 의해 제안된 통찰을 탐색하기보다는 다수의 의견(majority opinions)에 초점을 맞출 수 있습니다.
- 쉽고, 빠르고, 자동화된 AI는 연구자들을 데이터에 대한 강렬하고 장기적인 몰입(intense prolonged immersion)으로부터 제거합니다; 그들은 개인적인 "의미 만들기(sense-making)"와 미묘한 의미 생성의 기회를 놓치게 됩니다.
- 요컨대, QDA는 노력이 들고, 신중하며, 능숙한 계획(effortful, deliberate, adroit planning)을 요구합니다—단지 앉아서 AI 인터페이스와 잡담하는 것(chatting)이 아닙니다. 탁월한 연구 질문을 던지고 탁월한 질적 연구를 설계하고 수행하기 위해서는 전문성(Expertise)—훈련과 경험—이 필요할 것입니다.
우리는 종종 질적 연구의 분석 단계에 초점을 맞추지만, 데이터 수집(data collection)도 동등하게 중요합니다. 많은 질적 연구에서, 연구자가 곧 데이터 수집 도구(instrument)입니다. 연구자는 참여자들로부터 데이터를 추출(extracting)하기보다는 그들과 함께(with) 데이터를 구성(constructs)합니다. 이는 친밀한 상호작용(intimate interaction), 내부자적 이해(insider understanding), 신뢰(trust), 효과적인 의사소통 기술을 필요로 합니다. 따라서, AI 지원 데이터 수집이 유용한 이점을 제공하지만, 감소된 연구자 관여(reduced researcher involvement)로 인해 발생하는 트레이드오프(trade-off)를 고려해야 합니다.
AI의 해석은 단순히 틀리거나 오해의 소지가 있을(wrong or misleading) 수 있습니다. 질적 연구에 단 하나의 "정답(correct)" 결과는 없지만, 명백히 틀릴(blatantly wrong) 가능성은 있으며—AI는 이에 취약합니다.
- 첫째, 일부 AI 기법(GPT와 같은 LLM 포함)은 데이터에 실제로 존재하지 않는 정보를 발명(invent, 예: 인용문이나 저널 인용)하거나 데이터를 수정(modify, 종종 프롬프트 자체에서 끌어옴)할 수 있습니다. 이러한 "환각(hallucinations)"은 확률적 모델링에서 비롯됩니다: 발명된 인용문은 이 맥락에서 그럴듯합니다(probable).
- 둘째, AI는 의미를 오해석(misinterpret)할 수 있으며, 특히 언어가 미묘할 때(nuanced) 그렇습니다;
- 이는 빈정거림(sarcasm, 긍정적인 진술이 실제로는 정반대를 의미함), 은유(metaphor), 전문 어휘(specialized vocabulary), 그리고 참여자들이 베일에 싸인 언어(veiled language)로 그들의 진짜 의도를 가장할 때("행간에 숨겨진[hidden between the lines]";
- 예를 들어, "좋은" 학생 평가는 종종 실제로는 "열등한 수행[inferior performance]"을 의미함) 발생할 수 있습니다.
- AI는 결코 실천적 지혜(practical wisdom)를 소유하지 못할 것입니다. 더 모호한 "틀림(wrongness)"은 AI가 깊거나 층위가 있는 의미(deep or layered meaning)를 이해하지 못할 때, 관련 이론이 무시되거나 잘못 적용될 때, 또는 형식적인 분석이 새로운 통찰을 간과할 때 발생할 수 있습니다: 여기서 결론은 부정확하지는 않지만, 연구 중인 현상을 완전히 포착하는 데 실패합니다. 이는 연구자가 분석으로부터 거리 두어졌을 때(필요에 의해[극도로 큰 데이터셋] 또는 선택에 의해) 특히 문제가 됩니다. 그러나, 연구자가 친밀하게 관여된 상태라 하더라도, 그들은 "제안을 보지 않았던 것으로 할 수 없으며(cannot unsee a suggestion)," 결론은 부정확한 AI 해석에 의해 영구적으로 오염될(permanently tainted) 수 있습니다.
AI는 일반적인 연구(질적 연구에 국한되지 않음)에 몇 가지 문제를 도입합니다.
- 첫째, AI는 엄격함이나 권위(aura of rigor or authority)를 부여하는데, 이는 인간 연구자들을 평가절하하고 궁극적으로 대체(displace)할 수 있습니다.
- 둘째, 생성형 AI 도구(LLM 같은)는 매우 읽기 쉽고 대단히 그럴듯한 텍스트를 생성하지만, 그럼에도 불구하고 "진실 같은(truth-y)" 헛소리(nonsense)일 수 있습니다.
- 셋째, AI는 오해의 소지가 있는 결과를 내놓도록 조작될 수 있으며(의도적이든 우발적이든), 단순히 틀릴 수도 있습니다. 그러한 거짓 결과(false findings)는 진실로 유포될 것이며—아무도 그것을 알거나 억제할 수 없을 것입니다.
- 넷째, AI 지원 지식 창출이 반향실(echo chamber)의 일종(사람이 자신의 의견을 강화하는 정보만 접하게 되는 상황)을 만들 위험이 있습니다: AI에 의해 선택된 질문들이 AI에 의해 수집된 데이터를 사용하여 AI에 의해 답변되고 AI 지원 검토를 거쳐 출판되는 것입니다(이것은 "모델 붕괴[model collapse]"라는 더 큰 문제의 한 가지 징후입니다).
- 물론, 거짓 결과의 위험은 이미 존재합니다(예: 과학적 부정행위); AI와의 구별되는 차이점은 그것이 더 많아질 것이고, 컴퓨터는 권위의 아우라를 가지며, 정직한 과학자들조차 무심코 결함 있는 결과(flawed findings)를 출판할 수 있다는 것입니다. 이러한 문제들은 집합적으로 지식과 전문성 민주화의 어두운 면(dark side)을 구성합니다.
- 우리는 궁금해합니다: 만약 이러한 문제들이 구체화된다면, 그것이 사람들로 하여금 QDA를 전반적으로 불신하게(distrust) 만들 수 있을까요?
AI-QDA가 더 빠르고 쉬울 것이라는 약속은 어떨까요? 더 쉬운 것이 더 좋은 것은 아닐 수 있습니다(Easier might not be better). 사실, 더 적은 연구자 노력은 아마도 더 적은 통찰(fewer insights)로 이어질 것입니다; 더 깊은 의미를 명료화하기(elucidate) 위해 추가적인 작업을 하는 것은 가치가 있을 수 있습니다. 더욱이, 여러 연구는 AI가 실제로 시간이나 노력을 절약해주지 않고 오히려 AI 분석을 해석하거나 AI가 생성한 코드북을 정제하는 것과 같이 인간의 노동을 단순히 다른 활동으로 재분배(redistributes)한다는 것을 시사합니다. 한 연구는 GPT가 새로운 데이터가 축적됨에 따라 코딩 주제(coding themes)를 계속 추가하여, 결과적으로 인간의 업무량(human workload)을 지속적으로 확장시킨다는 것을 발견했습니다.
일부 AI 접근법은 매우 재현 가능(reproducible, 반복하면 분석이 같은 답을 산출함)하지만, 다른 것들은 그렇지 않습니다. 특히 LLM은 비재현적("비결정론적[non-deterministic]") 결과를 생성합니다: 동일한 데이터셋과 프롬프트를 다시 제출해도 동일한 결과가 나오지 않을 것입니다. 이것은 저주이자 축복(curse and a blessing)입니다. 당연히, 비재현성은 결과의 신뢰성(trustworthiness)에 대한 의문을 제기합니다. 그러나, 인간의 분석 또한 개인 간 또는 개인 내에서조차 재현 가능하지 않으며, AI의 가변성(variability)은 인간의 창의성을 모방합니다. 더욱이, 여러 반복된, 일관성 없는 분석에 걸친 결과를 종합(synthesizing)하는 것은 최종 결론을 풍부하게 만들 수 있습니다.
AI는 필연적으로 노동 인력의 변화(shifts in the workforce)로 이어질 것입니다.
- AI는 일반적으로 주니어 연구자들에게 위임되는 과업들(전사 및 예비 분석 같은)을 쉽게 수행합니다. 이는 그러한 과업들로부터 얻어지는 경험적 학습(experiential learning)과 문화적 적응(acculturation)을 감소시킬 수 있으며, 궁극적으로 시니어 연구자들의 수와 자격 요건에 영향을 미칠 수 있습니다. 일자리 대체(Job displacement)는 이미 초급 은행 전문가나 프리랜서 작가와 같은 다른 분야에서 관찰되었습니다.
- AI는 또한 훈련 중인 연구자들을 위한 새로운 목표와 역량(competencies)을 필요로 할 것이며, 커리큘럼의 수반되는 변화를 가져올 것입니다. 마지막으로, AI에 대한 과도한 의존은 시니어 연구자들 사이에서 기술, 통찰력(perceptivity), 창의성, 또는 이론적 민감성(theoretical sensitivity)의 상실로 이어질 수 있습니다.
현재 LLM의 인기를 고려하여, 우리는 이 접근법에 특유한 과제들을 강조합니다(부록 1).
- 첫째, 우리는 현재의 LLM이 유용한 "즉시 사용 가능한(out-of-the-box)" 해결책을 제공하는지 의심합니다(우리의 개인적 경험을 보십시오). 산출물은 비결정론적이며 환각에 취약합니다. 그들은 겉보기에 단순한 과업들을 잘 수행하지 못하며 다단계 지시(multistep instructions)를 따르지 않습니다.
- 둘째, 효과적인 프롬프트(지시와 동반 데이터)를 엔지니어링하는 것은 쉽지 않으며, 우리의 경험상 이것은 만족스러운 결과를 제공하는 데 실패했습니다. 다른 저자들도 마찬가지로 QDA를 위한 효과적인 LLM 프롬프트 생성의 어려움을 언급했습니다.
- 셋째, LLM은 컨텍스트 윈도우(context window)에 의해 제한됩니다. 현재, 전형적인 컨텍스트 윈도우는 무료 LLM의 경우 약 12,000단어, 유료 버전의 경우 100,000단어입니다. 작은 컨텍스트는 적당한 데이터셋(예: 각 8,000단어의 20개 전사본은 160,000단어임)의 분석조차 가로막습니다(preclude). 한 가지 해결책은 데이터셋을 더 작은 하위 집합(smaller subsets)으로 나누는 것이지만, 이는 자연히 분석 결과에 영향을 미칩니다. 이 문제는 LLM 기술이 향상됨에 따라 사라질 수 있습니다.
마지막으로, AI는 다수의 윤리적 우려(ethical concerns)를 제기합니다. 비록 많은 소셜 미디어가 공공 영역(public domain)으로 간주되지만, 사용자 허가 없이 데이터가 연구에 사용될 때 윤리적 및 법적 과제가 발생해왔습니다.
- LLM을 포함한 상용 제품들은 참여자들이 동의(consented)했을 때조차 데이터 기밀성(confidentiality), 프라이버시, 보안에 대한 추가적인 우려를 제기합니다. LLM에 제출된 각 프롬프트(데이터 포함)는 기본적으로 미래의 응답을 생성하는 데 사용되는 모델의 영구적인 일부가 됩니다(모델 "학습"). 안전한 저장과 내부 분석을 위해 의도된 인터뷰 인용문은 일단 LLM에 제출되면 그 이후로는 잠재적으로 공개적으로 이용 가능하게 됩니다. 물론, 이것이 개인에게 역추적될 가능성은 희박하지만—기밀성에 대한 철학적 위반(philosophical breach)은 남습니다.
- 일부 연구자들은 또한 AI 회사들이 이윤 창출 벤처를 위해 그들의 데이터에 기생한다(parasitize)는 것을 알고 분개하기도 합니다. 대부분의 현대 LLM들은 이제 학습을 끄는 옵션을 제공합니다. 다른 상용 제품들의 데이터 보안 또한 고려되어야 하며, 특히 점점 더 흔해지는 보안 위반(security breaches)에 비추어 볼 때 그렇습니다. 여러 국가가 데이터 보안 및 사용을 규제하는 법률을 가지고 있습니다. 우리는 계획된 또는 잠재적 AI 사용과 관련 경고(caveats)가 프로토콜과 동의 절차(consent procedures)에서 명시적으로 인정될 것을 권장합니다.
- AI는 또한 연구자의 안일함(complacency, 불완전한 분석), 부풀려진 생산성(inflated productivity, 질보다 양), 그리고 노골적인 사기(outright fraud)를 조장할 수 있습니다. 마지막으로, 원고 작성(writing manuscripts)에 있어 AI의 역할에 대해 최근 많은 글이 쓰였습니다.
성찰성은 어떠한가? (What about reflexivity?)
모든 연구는 관련된 연구자들의 가정과 경험에 의해 형성되며, 또 그것을 형성합니다. 성찰성(Reflexivity)은 연구자들이 이러한 피할 수 없는 주관성(subjectivity)—즉, "연구자가 자신의 주관성과 맥락이 연구 과정에 어떻게 영향을 미치는지 자의식적으로 비판하고, 평가하고, 판단하는 지속적이고, 협력적이며, 다면적인 실천들(practices)"—을 다루는 활동입니다. 성찰성은 크게 4가지 방식으로 분류될 수 있습니다.
- 첫째, 연구자들은 자신의 주관성을 중립화(neutralize)하거나 제쳐두려고 노력할 수 있습니다—개인적 관점을 "괄호 치기(bracketing)"하고 분석에 "백지 상태(blank slate)"로 접근하려고 시도합니다.
- 둘째, 연구자들은 자신의 관점을 인정(acknowledge)하되, 해석이나 영향의 완화 없이 단순히 나열할 수 있습니다.
- 셋째, 연구자들은 자신의 관점이 분석에 어떻게 영향을 미칠 수 있는지 설명할 수 있는데, 흔히 부정적인 것(즉, "편향[bias]")으로 표현됩니다.
- 넷째, 아마도 가장 강력하게, 연구자들은 긍정적인 입장을 취할 수 있습니다—자신의 관점을 강점(strength)으로 틀 짓고 주관성을 의미 만들기(meaning-making)의 중요한 원천으로 활용하는 것입니다.
AI를 사용하는 QDA에 성찰성이 어떻게 통합될 수 있을까요? 중립화하거나 설명하는 입장이 표면적으로는(ostensibly) 가장 적절해 보입니다—AI의 영향을 괄호 치기 하거나 방어하고 인간의 역할을 주장하는 것입니다. 그러나, AI의 일부 특징들이 방어적인 자세를 요구함에도 불구하고, 우리는 완전한 성찰성(full reflexivity)은 그것의 긍정적인 기여 또한 고려해야 한다고 제안합니다.
이를 탐구하기 위해, 우리는 AI를 연구팀의 독립적인 구성원(independent member)으로 상상하고(AI를 의인화하는 것에 대한 논란을 인식하면서), AI의 "경험"이 분석에 어떻게 영향을 미칠 수 있을지 4가지 렌즈—개인적(personal), 대인적(interpersonal), 방법론적(methodological), 맥락적(contextual)—를 통해 고찰했습니다( 표 3 참조).
- 개인적 렌즈는 모델을 훈련시키는 데 사용된 방법을 강조합니다: 훈련 데이터의 폭, 깊이, 대표성(representativeness)은 훈련 알고리즘과 마찬가지로 불가피하게 AI 산출물을 좌우(dictate)할 것입니다.
- 대인적 렌즈는 연구 참여자와 다른 연구팀 구성원을 포함하여 AI와 인간 간의 상호작용을 강조합니다. 이러한 상호작용은 대안적으로 분석을 확언(affirm)하거나 방향 전환(redirect)할 수 있습니다—연구자의 기존 신념, 편향, 가정, 경험을 증폭하거나 도전하면서 말입니다.
- 방법론적 렌즈는 연구 패러다임, 이론, 방법의 영향을 강조합니다. 여기에는 사용자에게 종종 불투명한(opaque), AI가 내리는 분석적 "선택들(choices)"이 포함됩니다. 예시를 들자면, 누군가 인터넷을 검색하기 위해 구글을 사용할 때 구글이 정보를 식별하고 우선순위를 매기는 과정을 거의 숙고하지 않습니다. 본질적으로, 구글의 끊임없이 진화하는 AI 알고리즘은 매일 우리 삶에 영향을 미치는 보이지 않는 손(invisible hand)을 구성합니다. 유사하게, 연구자들이 복잡한 모델(LLM이나 다른 딥러닝 모델 같은)이나 정형화된 레시피(예: 토픽 모델링용)를 사용할 때 그들은 보이지 않는 손에 동의(accede)하는 것입니다.
- 마지막으로, 맥락적 렌즈는 AI가 분석을 수행하고 제시하는 역사적, 문화적 맥락의 영향을 강조합니다. 기본적으로 이것은 한계가 될 수 있지만, 전략적으로 사용된다면 AI는 연구자들이 고려하지 못한 맥락(예: 소외된 공동체)을 식별하는 데 도움을 줄 수 있습니다.
1. 개인적 (Personal) 관점👉 AI의 "출신 성분"과 "과거 경험" (학습 데이터)
2. 대인적 (Interpersonal) 관점👉 AI와 "인간(연구자/참여자)" 사이의 관계와 상호작용
3. 방법론적 (Methodological) 관점👉 AI의 "일하는 방식"과 "도구적 한계"
4. 맥락적 (Contextual) 관점👉 AI의 "눈치(맥락 파악 능력)"와 "사회적 배경지식"
|

표 3 - 성찰성: 질적 데이터 분석에서 AI의 영향 고찰 (Reflexivity: Contemplating the Influence of AI in Qualitative Data Analysis) 이 표는 성찰성에 대한 4가지 접근법과 그에 따른 AI의 특징이 분석 결과에 미칠 수 있는 영향을 정의합니다. 이 고찰들은 AI를 마치 "관점"을 가진 것처럼 연구팀의 독립적인 구성원으로 위치시키고, 특정 모델이나 접근법의 경험, 분석 과정, 선택, 편향이 분석 산출물에 어떻게 영향을 미칠지 고려합니다.
- 개인적 (Personal)
- 정의: "연구 프로젝트를 형성하는 태도와 기대... 개인의 연구에 영향을 미치는 가정(assumptions), 기대(expectations), 반응(reactions), 무의식적 반응."
- 분석 결과에 영향을 미칠 수 있는 AI 특징: 모델을 훈련시키는 데 사용된 방법에서 발생하는 AI의 관점(부정적 [편향] 또는 호의적) - 훈련 데이터셋, 훈련 모델, 훈련 알고리즘(AI의 "과거 경험") 포함.
- 예시: 분석을 특정 집단이나 사고방식으로 편향되게 하는 훈련 데이터, 특정 통찰을 식별하는 능력은 향상시키지만 다른 것들은 무심코 제약할 수 있는 특수한 훈련 데이터, 지도 vs 비지도 학습 알고리즘의 본질과 범위, 훈련을 위해 라벨링된 예시(labeled exemplars)가 생성되는 방식.
- 대인적 (Interpersonal)
- 정의:
- "연구자와 참여자 간의 관계... 데이터 수집의 대화적 성격과 이것이 요구하는 윤리적 의무를 인식하는 것; 그리고 내재된 권력 역학(implicit power dynamics)을 드러내기 위해 '사후에' [분석 중] 대화를 면밀히 조사하는 것." /
- "참여자의 고유한 지식과 관점을 인식하고 인정하는 것... 그들이 우리의 질문을 어떻게 해석하는지. 반대로, 참여자가 공유한 정보와 통찰은 연구자의 결정과 결과에 직접적인 영향을 미칠 것이다." /
- "연구팀 구성원 간의 관계."
- 분석 결과에 영향을 미칠 수 있는 AI 특징:
- AI와 연구 참여자 간의 상호작용: AI가 개입되었다는 것을 아는 것이 참여자의 응답에 어떻게 영향을 미칠 수 있는지, 미묘한 인간-인간 권력 역학에 대한 AI의 (둔)감성([in]sensitivity), 초기 인간 반응에 의해 AI 분석이 어떻게 형성되는지(혹은 안 되는지).
- AI와 연구팀의 인간 구성원 간의 상호작용: 전체적인 연구 설계(계획에서의 선택)에 미치는 AI 행동 유도성(affordances)의 영향, 분석 과정에서 AI를 안내할 때 인간이 내리는 재량적 선택(discretionary choices), 연구자가 AI 산출물을 신뢰하는 정도, AI 분석 결과가 후속 분석 선택에 미치는 영향. 이러한 선택에는 모델; 훈련 예시의 성격과 수(있다면); 프롬프트, 지시사항, 컴퓨터 코드의 구체화 및 순서; 그리고 분석을 지속할지, 전환(pivot)할지, 중단할지 여부가 포함됨.
- 정의:
- 방법론적 (Methodological)
- 정의:
- "각 연구 프로젝트를 둘러싼 이론적 헌신(Theoretical commitments)... 프로젝트가 수행되는 이론적 접근법의 경계 또는 한계." /
- "패러다임적 지향(Paradigmatic orientation)." /
- 매 순간의 결정과 반응이 "윤리적이고, 엄격하며, 패러다임적으로 일치"한다는 보증.
- 분석 결과에 영향을 미칠 수 있는 AI 특징: 알고리즘이나 분석 접근법(AI에 의해 내려진 "선택들")에서 발생하는 AI의 관점(부정적 [편향] 또는 호의적); 무대 뒤의 "보이지 않는 손(invisible hand)."
- 예시: 주어진 접근법(예: 토픽 모델링, 거대 언어 모델, 연역적 분석을 위한 지도 학습)의 행동 유도성과 제약, 이론이나 패러다임을 분석에 통합하는 AI의 능력(즉, AI가 근거 이론 vs 현상학 vs 담론 분석; 또는 후기 실증주의 vs 구성주의 패러다임을 얼마나 의미 있게 그리고 진정성 있게 구현하는지의 정도).
- 정의:
- 맥락적 (Contextual)
- 정의:
- "주어진 연구를 문화적, 역사적 환경(milieu) 속에 위치시키는 것; ... 특정 현상이 나타나는 맥락뿐만 아니라 주어진 연구의 배경," 물리적 맥락(위치)을 포함. /
- "연구 질문과 그 답은 가정과 실천의 사회적 장(social field) 안에 묻혀 있고 그 영향을 받는다... 연구는 [또한] 사회적 장 [자체]를 변형시킨다."
- 분석 결과에 영향을 미칠 수 있는 AI 특징: 응답을 더 큰 문화적, 물리적, 또는 역사적 맥락과 사회적 장(social field) 안에 위치시키는 AI의 능력.
- 예시: 참여자의 문화나 물리적 위치(예: 그들의 집, 병원, 또는 연구 인터뷰실)의 영향을 고려하거나, 기존의 사회 이론과 연구를 식별하고 분석에 통합하는 능력(또는 그 결여).
- 정의:
우리는 성찰성의 이러한 각 특징이 강점이자 약점이 될 수 있음을 주목하며, 이러한 특징들을 비난하기보다는 활용(capitalizing on)하는 것의 바람직함을 강조합니다. 우리는 또한 이 주제에 대한 우리의 고찰이 미완성(unfinished nature)임을 강조하며, 다른 이들이 이 도입적인 노력을 부연 설명해 주기를 바랍니다.
무엇이 가능해질까? 추가적인 약속들 (What will become possible? Additional promises)
위의 많은 내용은 이미 존재하는 QDA 접근법을 지원하기 위해 AI를 사용하는 것에 초점을 맞추고 있습니다. 우리는—휴대용 카세트 녹음기가 40년 전 QDA를 변화시켰던 것처럼—AI가 현재는 꿈꾸지 못한(undreamt) 새로운 접근법들을 영감을 주고 가능하게 할 것을 예상하고, 희망하며, 기대합니다. 우리는 코딩 루브릭의 연역적 적용, 대규모 데이터셋의 귀납적 분석, 예외뿐만 아니라 헤게모니에 초점을 맞춘 담론 분석과 같은 초기 가능성(early promise)을 이미 보았습니다. 세련된(sophisticated) 질적 연구자들이 강점과 한계를 충분히 인식한 상태에서 AI를 연구 파트너로서 사려 깊고, 창의적으로 사용함에 따라, AI 도구들은 그들이 더 많은 질문에 답하고, 더 높은 효율성과(또는) 더 깊은 통찰력으로 답할 수 있도록 도울 잠재력을 가지고 있습니다.
맺음말 (Final Thoughts) 우리가 이것을 해야 할까요? 이 질문은 아마 너무 늦었을 것입니다—이 분야는 25년 이상 QDA를 지원하기 위해 AI를 사용해 왔습니다! 아마 더 나은 질문은, "단점을 최소화하면서 AI의 장점을 어떻게 활용할 수 있을까?"일 것입니다. 우리는 3가지 답변을 제안합니다.
첫째, 연구자들은 이러한 기술들—그 한계와, 아마도 더 중요하게는, 이용 가능한 옵션의 다양성(diversity of options) 및 각 옵션의 강점을 잠금 해제하는 방법("AI 리터러시[AI literacy]")을 이해할 필요가 있습니다. 이러한 기술들은 목적 맞춤형 AI QDA 도구와 맞춤형 제작 AI 절차(예: LLM, Python, R 사용)를 모두 포함합니다. 더욱이, 이러한 기술들은 끊임없이 움직이는 과녁(moving target)입니다: GPT(및 다른 LLM)의 최신 버전들은 이미 이용 가능하며, 급격한 변화가 새로운 표준(new normal)입니다. CAQDAS 도구(AI 포함)를 선택하는 데 도움을 구하는 연구자들에게, CAQDAS 네트워킹 프로젝트(CAQDAS Networking Project, surrey.ac.uk/computer-assisted-qualitative-data-analysis)는 훌륭한 자원을 제공합니다.
둘째, 연구자들은 그들의 데이터에 몰입(immersed)하고 의미 만들기 분석에 친밀하게 관여(intimately involved)된 상태를 유지해야 합니다. AI는 노력이 들고, 신중하며, 세련된 데이터 수집 및 분석의 필요성을 덜어주지(offload) 않을 것이며—덜어주어서도 안 됩니다. 인간은 QDA에서 주 도구(primary tool)로 남습니다. "인간이 루프 안에(human in the loop)" 있어야 할 뿐만 아니라, 인간이 루프를 책임져야(in charge) 합니다. 연구 책임자가 완전하고 최종적인 책무성(accountability)을 보유합니다.
셋째, 우리는 AI의 변혁적 잠재력(transformative potential)을 찾고, 인식하고, 포용해야 합니다. AI는 새로운 행동 유도성(novel affordances)을 제공합니다—우리는 무엇을 얻을까요? 2002년에, Gibbs 등은 언급했습니다, "CAQDAS의 깊은 수용을 위한 결정적 테스트(acid test)는 연구자들이 소프트웨어의 기능을 사용하여 전통적이고 수동적인 기법으로는 고려조차 할 수 없었던 분석을 수행하기 시작할 때가 될 것입니다... 연구자들이 연필과 종이의 과거에는 생각조차 하지 못했던 새로운 형태의 데이터와 새로운 유형의 분석을 사용할 때 말입니다." 우리는 AI 지원과 함께, 그날이 마침내 도래할지 궁금해합니다.
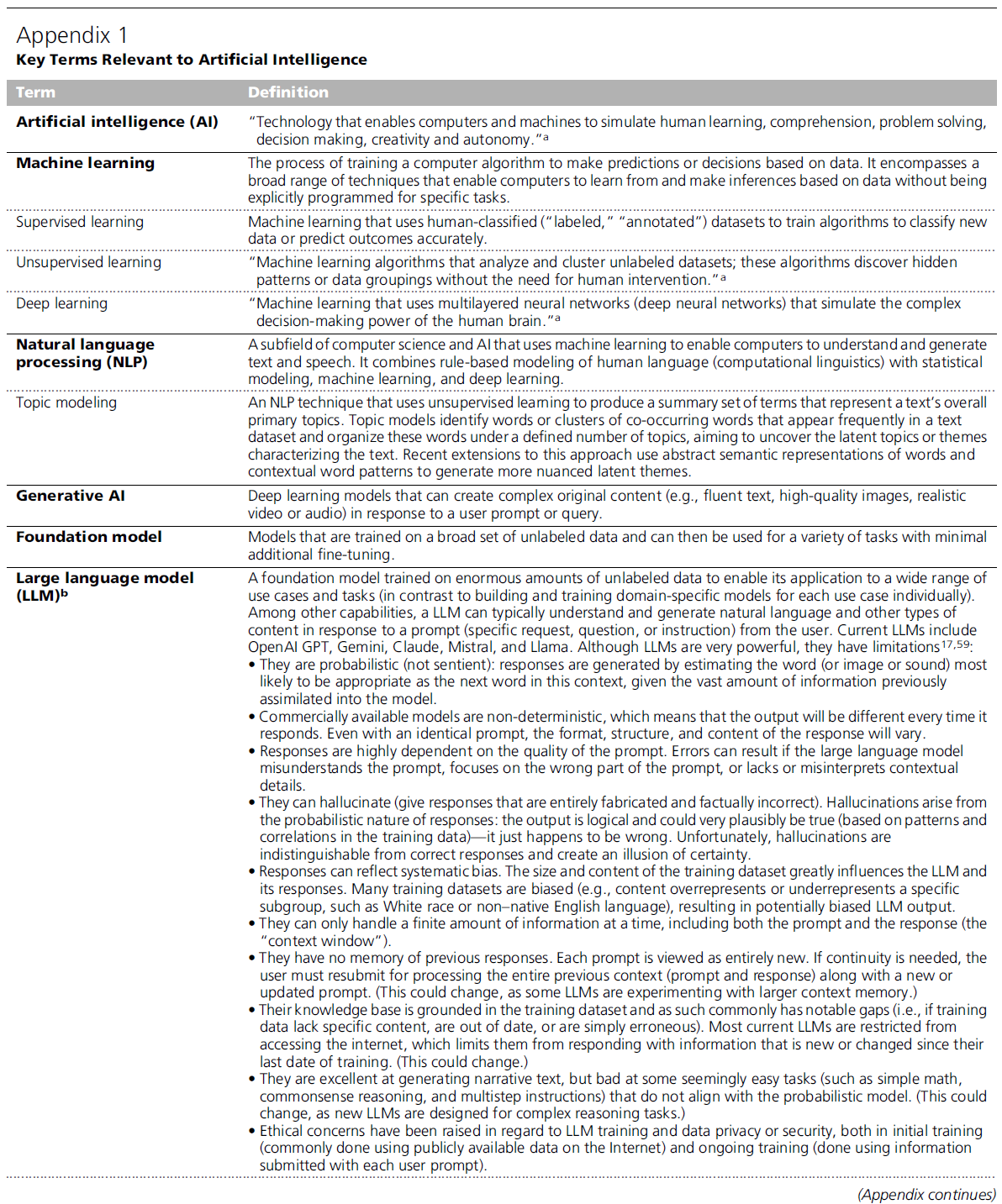

부록 1 - 인공지능과 관련된 핵심 용어 (Appendix 1 - Key Terms Relevant to Artificial Intelligence)
- 인공지능 (Artificial intelligence [AI])
- 정의: "컴퓨터와 기계가 인간의 학습(learning), 이해(comprehension), 문제 해결(problem solving), 의사 결정(decision making), 창의성(creativity), 그리고 자율성(autonomy)을 시뮬레이션할 수 있게 하는 기술." a
- 머신러닝 (Machine learning)
- 정의: 데이터에 기초하여 예측(predictions)이나 결정(decisions)을 내리도록 컴퓨터 알고리즘을 훈련시키는 과정. 이는 컴퓨터가 특정 과업(specific tasks)을 위해 명시적으로 프로그래밍되지 않고도(without being explicitly programmed) 데이터로부터 학습하고 추론(make inferences)할 수 있게 하는 광범위한 기법들을 포괄합니다.
- 지도 학습 (Supervised learning)
- 정의: 새로운 데이터를 분류(classify)하거나 결과를 정확하게 예측하도록 알고리즘을 훈련시키기 위해 인간이 분류한("라벨링된[labeled]", "주석이 달린[annotated]") 데이터셋을 사용하는 머신러닝.
- 비지도 학습 (Unsupervised learning)
- 정의: "라벨링되지 않은 데이터셋(unlabeled datasets)을 분석하고 군집화(cluster)하는 머신러닝 알고리즘; 이 알고리즘들은 인간의 개입(human intervention) 없이 숨겨진 패턴(hidden patterns)이나 데이터 그룹핑을 발견합니다." a
- 딥러닝 (Deep learning)
- 정의: "인간 뇌의 복잡한 의사 결정 능력(complex decision-making power)을 시뮬레이션하는 다층 신경망(심층 신경망[deep neural networks])을 사용하는 머신러닝." a
- 자연어 처리 (Natural language processing [NLP])
- 정의: 컴퓨터가 텍스트와 말(speech)을 이해하고 생성할 수 있게 하기 위해 머신러닝을 사용하는 컴퓨터 과학 및 AI의 하위 분야. 이는 인간 언어의 규칙 기반 모델링(계산 언어학[computational linguistics])을 통계적 모델링(statistical modeling), 머신러닝, 딥러닝과 결합합니다.
- 토픽 모델링 (Topic modeling)
- 정의: 텍스트의 전반적인 주요 토픽(primary topics)을 나타내는 용어 세트(summary set of terms)를 생성하기 위해 비지도 학습을 사용하는 NLP 기법. 토픽 모델은 텍스트 데이터셋에서 자주 등장하는 단어 또는 함께 발생하는 단어들의 군집(clusters of co-occurring words)을 식별하고, 텍스트를 특징짓는 잠재된 토픽(latent topics)이나 테마를 밝해내기 위해 정의된 수의 토픽 하에 이 단어들을 조직화합니다. 이 접근법의 최근 확장판들은 더 미묘한 잠재적 테마(nuanced latent themes)를 생성하기 위해 단어의 추상적 의미론적 표현(abstract semantic representations)과 맥락적 단어 패턴(contextual word patterns)을 사용합니다.
- 생성형 AI (Generative AI)
- 정의: 사용자 프롬프트나 질의(query)에 반응하여 복잡한 독창적 콘텐츠(complex original content, 예: 유창한 텍스트, 고품질 이미지, 현실적인 비디오나 오디오)를 생성할 수 있는 딥러닝 모델.
- 기반 모델 (Foundation model)
- 정의: 광범위한 라벨링되지 않은 데이터(broad set of unlabeled data)로 훈련되어 최소한의 추가 미세 조정(minimal additional fine-tuning)만으로 다양한 과업에 사용될 수 있는 모델.
- 거대 언어 모델 (Large language model [LLM]) b
- 정의: 광범위한 사용 사례(use cases)와 과업에 적용할 수 있도록 엄청난 양의 라벨링되지 않은 데이터로 훈련된 기반 모델(각 사용 사례별로 도메인 특화 모델[domain-specific models]을 개별적으로 구축하고 훈련하는 것과 대조됨). 다른 능력들 중에서도, LLM은 일반적으로 사용자로부터의 프롬프트(구체적 요청, 질문, 또는 지시)에 반응하여 자연어(natural language)와 다른 유형의 콘텐츠를 이해하고 생성할 수 있습니다. 현재의 LLM에는 OpenAI GPT, Gemini, Claude, Mistral, Llama가 포함됩니다. LLM은 매우 강력하지만, 한계(limitations)를 가지고 있습니다:
- 그들은 확률적(probabilistic)입니다(지각이 있는 것[sentient]이 아님): 응답은 모델에 이전에 동화된(assimilated) 방대한 양의 정보를 고려할 때, 이 맥락에서 다음 단어로서 가장 적절할 것 같은(likely to be appropriate) 단어(또는 이미지나 소리)를 추정함으로써 생성됩니다.
- 상업적으로 이용 가능한 모델들은 비결정론적(non-deterministic)인데, 이는 반응할 때마다 산출물이 다를 것임을 의미합니다. 동일한 프롬프트(identical prompt)라도, 응답의 형식, 구조, 내용은 달라질 것입니다.
- 응답은 프롬프트의 품질(quality of the prompt)에 크게 의존합니다. 거대 언어 모델이 프롬프트를 오해하거나, 프롬프트의 잘못된 부분에 집중하거나, 맥락적 세부사항(contextual details)이 부족하거나 이를 잘못 해석할 경우 오류(Errors)가 발생할 수 있습니다.
- 그들은 환각(hallucinate)을 일으킬 수 있습니다(완전히 조작되고[fabricated] 사실적으로 부정확한 응답을 제공함). 환각은 응답의 확률적 본성(probabilistic nature)에서 발생합니다: 산출물은 논리적이며(logical) 매우 그럴듯하게 사실일 수 있지만(plausibly be true, 훈련 데이터의 패턴과 상관관계에 기초하여)—단지 틀렸을 뿐입니다. 불행히도, 환각은 올바른 응답과 구별할 수 없으며 확실성의 환상(illusion of certainty)을 만듭니다.
- 응답은 체계적 편향(systematic bias)을 반영할 수 있습니다. 훈련 데이터셋의 크기와 내용은 LLM과 그 응답에 지대한 영향을 미칩니다. 많은 훈련 데이터셋이 편향되어 있어(예: 백인 인종이나 비원어민 영어와 같은 특정 하위 집단[specific subgroup]을 과대 대표하거나 과소 대표함), 잠재적으로 편향된 LLM 산출물을 초래합니다.
- 그들은 한 번에 유한한 양의 정보(finite amount of information)만 처리할 수 있으며, 여기에는 프롬프트와 응답이 모두 포함됩니다("컨텍스트 윈도우[context window]").
- 그들은 이전 응답에 대한 기억(memory)이 없습니다. 각 프롬프트는 완전히 새로운 것으로 간주됩니다. 연속성(continuity)이 필요하다면, 사용자는 전체 이전 맥락(프롬프트와 응답)을 새롭거나 업데이트된 프롬프트와 함께 처리를 위해 다시 제출해야 합니다. (일부 LLM이 더 큰 맥락 기억[context memory]을 실험하고 있으므로 이는 바뀔 수 있습니다.)
- 그들의 지식 기반(knowledge base)은 훈련 데이터셋에 기반을 두고(grounded) 있으므로 흔히 주목할 만한 격차(gaps)를 가집니다(즉, 훈련 데이터에 특정 내용이 없거나, 구식이거나, 단순히 오류가 있는 경우). 대부분의 현재 LLM은 인터넷 접속이 제한되어 있어, 마지막 훈련 날짜 이후의 새롭거나 변경된 정보로 응답하는 데 제약이 있습니다. (이는 바뀔 수 있습니다.)
- 그들은 서술형 텍스트(narrative text)를 생성하는 데는 탁월하지만, 확률적 모델과 일치하지 않는 겉보기에 쉬운 과업들(예: 간단한 수학, 상식적 추론[commonsense reasoning], 다단계 지시[multistep instructions])에는 서툽니다(bad). (새로운 LLM들이 복잡한 추론 과업을 위해 설계되고 있으므로 이는 바뀔 수 있습니다.)
- LLM 훈련과 데이터 프라이버시(data privacy) 또는 보안(security)과 관련하여 윤리적 우려(Ethical concerns)가 제기되어 왔으며, 이는 초기 훈련(흔히 인터넷상의 공개적으로 이용 가능한 데이터를 사용하여 수행됨)과 지속적인 훈련(각 사용자 프롬프트와 함께 제출된 정보를 사용하여 수행됨) 모두에 해당합니다.
- 정의: 광범위한 사용 사례(use cases)와 과업에 적용할 수 있도록 엄청난 양의 라벨링되지 않은 데이터로 훈련된 기반 모델(각 사용 사례별로 도메인 특화 모델[domain-specific models]을 개별적으로 구축하고 훈련하는 것과 대조됨). 다른 능력들 중에서도, LLM은 일반적으로 사용자로부터의 프롬프트(구체적 요청, 질문, 또는 지시)에 반응하여 자연어(natural language)와 다른 유형의 콘텐츠를 이해하고 생성할 수 있습니다. 현재의 LLM에는 OpenAI GPT, Gemini, Claude, Mistral, Llama가 포함됩니다. LLM은 매우 강력하지만, 한계(limitations)를 가지고 있습니다:
- 사전학습 트랜스포머 (Pretrained transformer)
- 정의: 이전의 신경망보다 훨씬 빠른 학습을 가능하게 하는 딥러닝 모델의 유형. 2017년 기술된 이후, 이는 신경망, NLP, 생성형 AI에 있어 혁명적 진보(revolutionary advance)를 구성했습니다. 구별되는 기본 원칙은 위치 인코딩(positional encoding, 문장 내 각 단어["토큰"]에 고유한 번호를 할당함)과 셀프 어텐션(self-attention, 문장 내의 모든 단어[순서 내의 토큰]에 다른 단어들과의 관계에 따라 가중치를 할당함)입니다. 이러한 기법들은 이미지를 "패치(patches)"로 나누거나(또는 오디오 신호를 "스펙트로그램[spectrograms]"으로 나누어) 이것들을 순서 내의 토큰으로 취급함으로써 이미지와 소리에 적용될 수 있습니다. 따라서 트랜스포머 모델은 순서상 나타날 가능성이 있는 토큰(단어, 패치, 또는 스펙트로그램)을 예측하도록 "학습"하고, 이로부터 새로운 콘텐츠를 생성합니다.
- 프롬프트 (엔지니어링) (Prompt [engineering])
- 정의: 프롬프트는 생성형 AI 모델에 제출되는 지시(instructions), 질문(questions), 또는 요청(requests)입니다. 형편없이 형성된 프롬프트(Poorly formed prompts)는 부정확하고, 편향되거나, 목표를 벗어난 응답을 초래할 수 있습니다. 프롬프트 엔지니어링은 생성형 AI 모델이 원하는 응답(desired response)을 제공하도록 프롬프트를 반복적으로 정제(iteratively refining)하는 과정입니다.
a 따옴표 안의 정의는 www.ibm.com/topics 에서 가져왔습니다. 이 주제에 대해 더 많은 정보를 찾는 독자들은 이 자원이 도움이 될 수 있습니다. b LLM에 대한 상세한 정보는 현재의 인기와 능력 때문에 제공되었습니다.

부록 2 - 질적 데이터 분석을 위해 챗GPT를 사용한 저자들의 첫 노력에 대한 사례 연구 연대기, 2024년 2월 (Appendix 2 - Case Study Chronicle of the Authors’ First Efforts Using ChatGPT for Qualitative Data Analysis, February 2024) a
데이터셋 1 (의대생 30명의 학습 목표, 각 2개의 응답, 1,380단어) b
- 챗GPT-4.0에게 각 응답 내에서 학생들 간의 공통 주제(common themes)를 식별하고, 그것을 세고(count), 그러고 나서 이 응답들 전반에 걸친 공유된 주제를 찾도록 요청하는 프롬프트가 생성되었습니다. 결과:
- 요청된 대로 주제의 유병률(prevalence)을 계산하지 않았습니다.
- 구체적으로 돌아가서 유병률을 세라고 요청했을 때, 모든 데이터를 단일 주제("기타[other]")로 군집화하고 유병률을 보고했습니다(N = 30).
- 설문지의 항목 전반에 걸쳐 특정 개인의 응답 내 패턴을 찾지 않았습니다.
- 프롬프트는 요청을 점진적으로 명확히 하고 단순화(clarify and simplify)하기 위해 여러 반복(iterations)을 거쳐 수정되었습니다. 결과:
- 챗GPT는 지시사항을 앵무새처럼 되뇌었지만(parroted back) 원래의 (결함 있는) 분석을 반복해서 진행했습니다.
- 상당한 수의 인용문(20%–77%)을 일관되게 "기타(other)"로 코딩했습니다.
- "기타" 사용을 피하라고 요청했을 때, 단순히 그 범주를 "일반적 개선(general improvement)"으로 라벨을 다시 붙였고(relabeled), 이후 "일반적 개선"을 "구체적 기술 향상(specific skill enhancement)"으로 라벨을 다시 붙였습니다.
데이터셋 2 (의사 211명의 설문조사, 각 1개의 응답, 7,419단어) c
- 공통 주제를 찾고, 주제 빈도(theme frequency)를 세고, 각 주제에 대한 예시적인 인용문(exemplary quotations)을 제공하도록 챗GPT에 요청하는 3단계 프롬프트가 생성되었습니다. 결과:
- 또다시 "기타(other)"라는 주제를 과도하게 사용(overused)했습니다—이 주제가 215회 발생했다고 언급했습니다(이는 응답자 수보다 많음). 다른 주제들의 빈도는 3회에서 55회 사이였습니다.
- 인용문은 종종 주제를 뒷받침하지 못했고(not supportive), 동일한 인용문이 1개 이상의 주제를 뒷받침하는 데 사용되었습니다.
- 프롬프트는 요청을 점진적으로 명확히 하고 단순화하기 위해 여러 반복을 거쳐 수정되었습니다. 결과:
- "기타" 범주를 재분석(reanalyze)하라고 요청했을 때, 챗GPT는 성공을 주장했지만 (215개의 코드 중) 오직 2개의 새로운 주제만을 식별했습니다: 이것들은 각각 데이터셋에서 단 한 번 발생했으며, 그중 하나는 단순히 "잡다한(miscellaneous)"으로 라벨링되었습니다.
- 챗GPT에게 각 인용문의 간략한 요약(brief summary)을 제공하고 그것의 감성(sentiment: 긍정, 부정, 중립)을 기록하도록 요청하며 프롬프트가 수정되었습니다. 결과:
- 개별 인용문의 의미 있는 요약을 생성하는 데 실패했습니다—대신 원래 인용문을 4~6단어 뒤에서 잘라내어(truncation) 축어적으로 반복(verbatim repetition)하거나, 여러 인용문에 걸쳐 적용된 토픽(일반적인 코드나 주제)을 제공했습니다.
- 감성 분류(sentiment classifications)는 원래 인용문의 정서적 어조(emotional tone)와 거의 관계가 없어 보였습니다.
데이터셋 3 (연구자 3명의 인터뷰, 19,207단어) d
- 챗GPT는 전체 데이터셋(30개의 인터뷰, 각각 약 6,000단어)을 분석할 수 없었는데, 왜냐하면 그것의 컨텍스트 윈도우(context window)가 한 번에 약 24,000단어로 분석을 제한했기 때문입니다. 그래서 전체 데이터셋의 하위 집합(subset)이 선택되었습니다.
- 이 분석은 단일 지시 세트로 전체 주제 분석을 완료하려고 시도하기보다는 특정 CAQDAS 기능에 초점을 맞추었습니다. 분석은 워드 클라우드(word cloud)를 생성하는 아마도 단순한 과업으로 시작되었습니다. 결과:
- 워드 클라우드에 대한 초기 요청은 토픽과는 관련이 있지만 실제 데이터셋 내에서는 발견되지 않는 단어들을 보여주는 그림을 초래했습니다.
- 프롬프트는 워드 클라우드에 대한 상세한 설명을 포함하도록 수정되었고, 이후 몇 번의 추가적인 반복을 거쳐 점진적으로 수정되었습니다. 결과:
- 두 번째 요청은 표준적인 워드 클라우드를 초래했지만, 가장 빈번한 단어들은 참여자 이름이나 익명화된 식별자(anonymized identifiers), 그리고 "yeah", "okay", "basically"와 같은 채움말(filler words)이었습니다.
- 이러한 단어들을 제거하라는 반복된 요청은 대체로 성공적이지 못했습니다. 챗GPT는 단어들을 제거했다고 주장했지만, 결과적인 워드 클라우드에는 여전히 그 단어들이 존재했습니다.
핵심 통찰 및 교훈 (Key insights and lessons learned) 요약하자면, 챗GPT는 서술형 텍스트의 정확하고 간략한 요약을 쉽게 생성했습니다. 시도된 다른 모든 과업에 대해서, 초기 프롬프트는 원하는 결과를 산출하는 데 실패했습니다. 반복적인 프롬프트 엔지니어링(iterative prompt engineering) 후, 일부 과업(키워드 계산, 요약)은 성공적이었으나 다른 것들은 결코 만족스러운 결과를 생성하지 못했습니다. 추가적으로 우리는 챗GPT-4에 대해 다음을 배웠습니다:
- 길고, 다단계 프롬프트(multistep prompts)를 따를 수 없었습니다.
- 제한된(24,000단어) 컨텍스트 윈도우 때문에 대규모 데이터셋을 분석할 수 없었습니다(이 한계는 현재의 거대 언어 모델들이 훨씬 더 큰 컨텍스트 윈도우를 가지고 있으므로 덜 제약적입니다).
- 유창한 텍스트를 생성했지만 단순한 수학(simple math, 주제 세기 같은)에는 형편없었습니다(lousy).
- 종종 지시사항을 앵무새처럼 되뇌었지만(parroted back) 그 지시사항을 따르는 데는 실패했습니다.
- 종종 요청된 산출물을 제공했다고 주장했지만 실제 산출물은 그 주장과 일치하지 않았습니다(자신이 한 일에 대해 틀렸음).
- 주제를 기억할 만한 뒷받침 인용문(memorable supportive quotations)과 연결하는 데 어려움을 겪었습니다(Struggled).
- 가끔(드물게) 데이터셋에서 나오기보다는 일반적으로 이용 가능한 지식, 논리, 또는 그럴듯한 세계관에 기반을 둔 결과를 "식별"했습니다.
- 대규모 데이터셋을 포괄적으로 나타내는 공통 주제를 식별할 수 없었고(적어도, 단일 단계 요청에 대한 반응으로는) "기타(other)" 분류를 과도하게 사용(인용문의 최대 50%까지)하며 피상적인 주제(superficial themes)를 식별하는 경향이 있었습니다.
- 자신이 식별한 주제에 대해 유용한 정의(useful definitions)를 제공했습니다.
- 워드 클라우드 생성과 같은 "단순한" CAQDAS 과업을 완료하는 데 어려움을 겪었습니다.
- 한 번 실행할 때와 다음 실행할 때 널리 다른 결과(divergent results, 내용과 형식 모두에서)를 제공했습니다.
약어: CAQDAS, 컴퓨터 보조 질적 데이터 분석 소프트웨어 (computer-assisted qualitative data analysis software).
a 이 부록은 챗GPT-4(2024년 2월)가 3개의 기존 데이터셋을 재분석하는 데 사용된 짧은 사례 연구의 행동, 결과, 통찰을 간략히 요약합니다. 추가 디지털 부록 1은 축어적 프롬프트를 포함한 추가 세부 사항을 제공합니다. b 데이터셋 1은 30명의 3학년 의대생들의 임상실습 전 학습 목표를 포함하는 작은 데이터셋(1,380단어)이었습니다. 2개의 열(설문지 항목)—"목표"와 "목표의 이유"—이 있었습니다. 이 응답들의 분석은 미출판 상태입니다(원고 준비 중). c 데이터셋 2는 유지 보수 인증(maintenance of certification) 주제에 대한 211명의 설문 응답자(개원 의사)들의 자유 텍스트 코멘트를 포함하는 더 큰 데이터셋(7,419단어)이었습니다. 이 설문조사의 정량적 결과는 이전에 출판되었으나, 이 자유 텍스트 응답의 분석은 미출판 상태입니다. d 데이터셋 3은 질적 데이터 재사용을 위한 데이터 큐레이션 주제에 대한 3명과의 인터뷰 전사본 3개(19,207단어)로 구성되었습니다. 챗GPT-4가 분석 용량을 약 24,000단어로 제한하는 32,000 "토큰"의 "컨텍스트 윈도우"를 가지고 있었기 때문에, 이 전사본들은 30개 인터뷰의 더 큰 데이터셋에서 선택되었습니다. 데이터셋은 오픈 소스 데이터 저장소에서 얻었으며, 이 데이터셋의 분석은 대학원 논문으로 출판되었습니다.