Nat Med. 2026 May 22. doi: 10.1038/s41591-026-04438-y. Online ahead of print.
AI-induced never-skilling in medical education
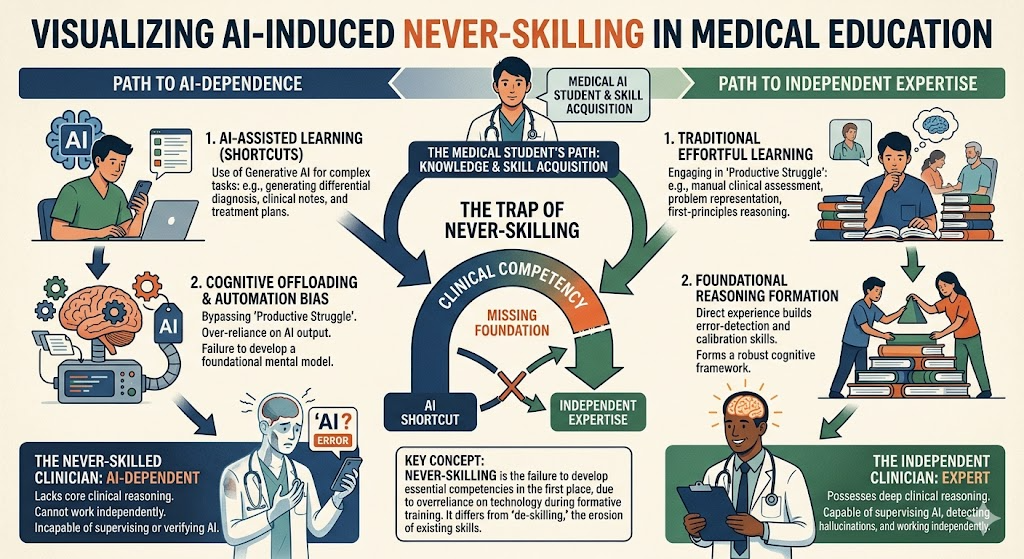
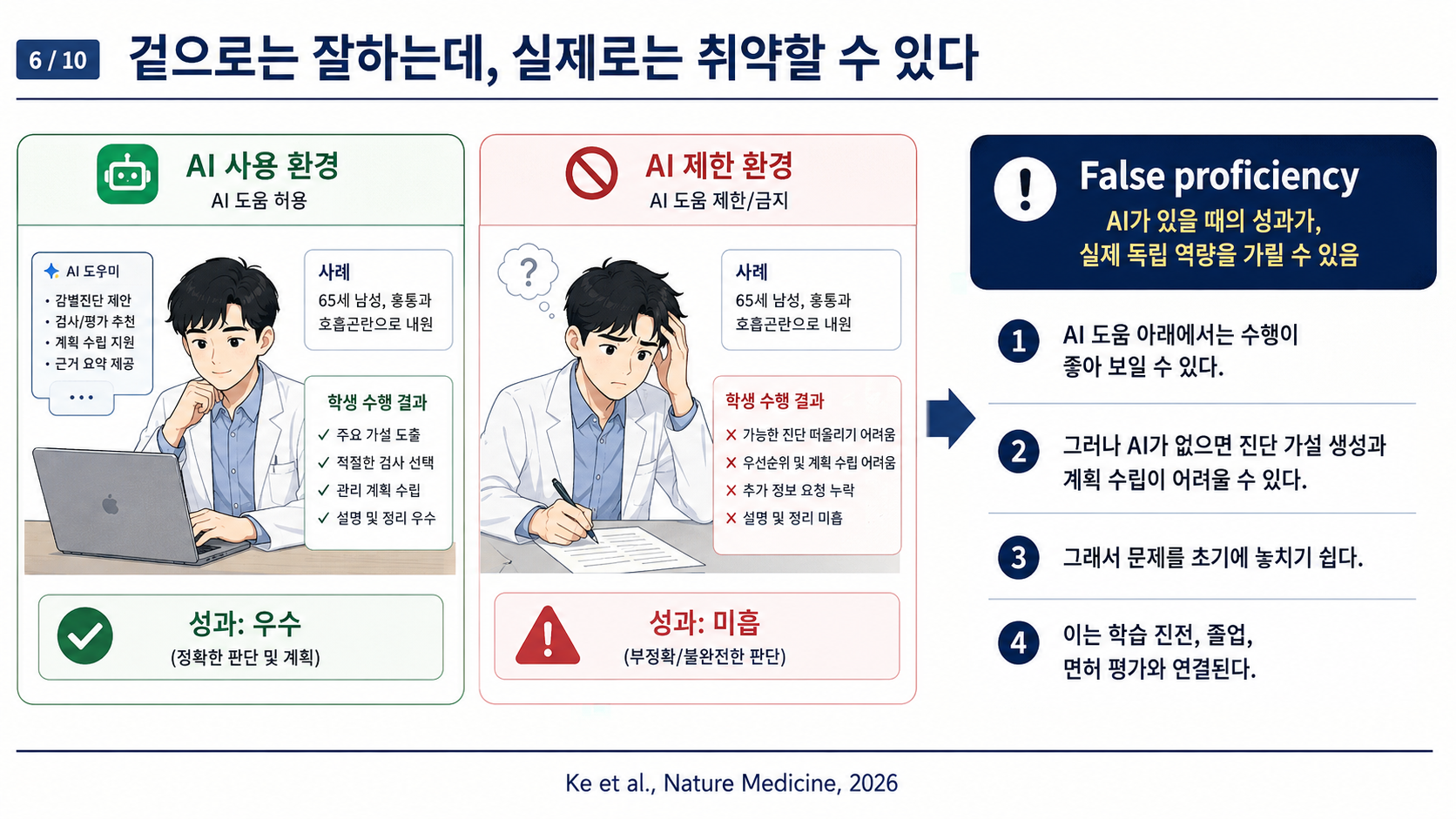
🤖 AI가 의대생의 실력 형성 자체를 막는다? — 'Never-Skilling' 개념의 등장
Ke Y. et al. (2026). AI-induced never-skilling in medical education. Nature Medicine. https://doi.org/10.1038/s41591-026-04438-y
들어가며
요즘 의료 현장이나 교육 현장에서 AI 얘기를 빼놓기가 힘들죠. 진단 보조, 처방 검토, 임상 의사결정 지원까지 — AI는 빠르게 의학의 일부가 되고 있어요. 그런데 최근 Nature Medicine에 흥미로운 Perspective 논문이 한 편 실렸습니다. 핵심 질문은 이거예요:
"AI를 너무 일찍, 너무 많이 쓰면, 의대생들이 애초에 임상 추론 능력을 개발하지 못하는 건 아닐까?"
이 논문에서 저자들은 이 현상을 'never-skilling(네버-스킬링)' 이라고 부릅니다. 생소한 용어인데, 읽다 보면 꽤 섬뜩한 개념이에요. 한번 차근차근 살펴볼게요.
📌 핵심 개념 정리 — 세 가지 위험을 구분하자
저자들은 AI가 의학 교육에 가져올 수 있는 위험을 세 가지로 나눠서 설명해요.
1. Deskilling (탈숙련화)
이미 역량을 갖춘 임상의가 AI에 지나치게 의존하다가 기존에 갖고 있던 능력이 퇴화하는 현상이에요. "쓰지 않으면 녹슨다"는 원리와 같죠. 예를 들어, AI 보조 대장내시경을 쓰던 숙련 내시경 의사가 AI 없이 하면 선종 발견율이 떨어지는 것처럼요.
2. Mis-skilling (오숙련화)
AI가 틀린 정보를 냈는데 이를 비판적으로 검토하지 않고 그냥 받아들이다 보면 잘못된 임상 추론 패턴이 자리를 잡는 현상이에요. AI의 오류가 머릿속에 '사실'로 굳어버리는 거죠.
3. ⚠️ Never-skilling (역량 미형성) — 이 논문의 핵심
앞의 두 개념과 결정적으로 다른 건 never-skilling입니다.
"Never-skilling refers to the failure to develop foundational competencies during formative training when AI substitutes a majority of the cognitive effort required to build independent clinical reasoning."
"never-skilling이란, AI가 독립적인 임상 추론을 구축하는 데 필요한 인지적 노력의 대부분을 대체할 때, 교육의 형성기 동안 핵심 역량 자체를 개발하지 못하는 현상을 말한다."
즉, deskilling은 갖고 있던 능력을 잃는 것이고, never-skilling은 처음부터 그 능력을 갖추지 못하는 것이에요. 의대생, 전공의 초기처럼 임상 추론 능력이 형성되는 시기에 AI가 그 과정을 대체해버리면, 나중에 AI 없이 혼자서는 제대로 된 진단도, 치료 계획도 세우지 못하는 의사가 탄생할 수 있다는 겁니다.
🔍 왜 AI는 기존 의료기술과 다른가?
"CT가 나왔을 때도, 전자의무기록(EMR)이 나왔을 때도 다들 걱정했잖아요. 근데 별로 문제 없었잖아요?" — 이런 반론이 당연히 나오겠죠.
저자들도 이 질문에 정면으로 답합니다.
"Prior technologies shifted the type of cognitive work required but preserved its presence... AI can, by contrast, execute the entire diagnostic chain autonomously. This is not a shift in cognitive work. It is a substitution for it."
"기존 기술들은 필요한 인지적 작업의 종류를 바꿨을 뿐, 인지적 작업 자체는 여전히 존재했다... 반면 AI는 진단 과정 전체를 자율적으로 수행할 수 있다. 이건 인지적 작업의 전환이 아니라, 대체다."
CT는 보여줄 뿐이에요 — 의사가 해석해야 하죠. 검사 수치도 임상 상황과 연결해서 판단해야 해요. EMR은 데이터를 정리해줄 뿐, 진단 결론을 내려주지 않아요. 하지만 LLM(대형 언어 모델)은 입력을 받으면 진단부터 치료 계획까지 전 과정을 알아서 해줄 수 있어요. 인지적 노력을 줄이는 게 아니라, 없애버리는 거죠.
두 번째 차이는 노출 시점이에요. 영상의학 장비의 과의존은 주로 이미 기초 역량을 갖춘 임상의에게서 나타났어요. 반면 AI는 의대 첫날부터 쓸 수 있어요. 임상 추론의 틀이 아직 형성되기도 전에요.
🧠 교육학 이론이 뭐라고 하나?
논문에서 흥미로운 점은, 아직 직접적인 임상 증거가 없는데도 교육학 이론을 근거로 이 위험을 설득력 있게 전개한다는 거예요.
- 바람직한 어려움 이론(Desirable difficulties theory) 단기적으로 학습을 어렵게 만드는 조건이 장기적으로는 더 견고한 기억과 전이를 만들어낸다고 해요. AI가 답을 즉시 줘버리면, 지식이 장기 기억으로 굳어질 인지적 노력이 사라지는 거예요.
- 의도적 연습 이론(Deliberate practice theory) 전문가적 추론은 노력이 필요하고 피드백이 풍부한 문제 해결 경험을 통해 만들어져요. AI에게 진단을 맡기면 시간은 쌓이는데 그 시간이 만들어야 할 인지적 투자는 이루어지지 않는 셈이죠.
- 인지부하 이론(Cognitive load theory) 임상 추론의 기반이 되는 '스키마(schema)' 형성은 작업 기억 속에서의 노력 있는 처리를 필요로 해요. AI가 이 처리를 건너뛰게 해주면, 스키마 자체가 만들어지지 않을 수 있어요.
- 전문성 역전 효과(Expertise reversal effect) 초보자에게 도움이 되는 교수 지원이 전문가에겐 중립적이거나 오히려 해롭다는 이론이에요. AI 지원이 초보자와 숙련 임상의에게 다른 영향을 미칠 수 있다는 이론적 근거가 되죠.
📊 초기 경험적 신호들
직접적인 임상 증거는 아직 없지만, 간접적인 신호들이 있어요.
- Budzyń 등(2025): AI 보조 대장내시경을 일상적으로 쓰던 숙련 내시경 의사들이 이후 비보조 시술에서 선종 발견율이 6% 낮았어요 — deskilling의 신호.
- Kosmyna 등(2025): LLM 보조 글쓰기를 지속적으로 쓰면 뇌 신경 연결성이 약해지고, 자신이 생성한 내용을 더 잘 기억하지 못하는 것과 연관됐어요.
- Bastani 등(2025): 고등학생 무작위 연구에서, AI 튜터에 무제한 접근한 학생들은 보조 연습 중엔 성과가 좋았지만, 이후 비보조 수학 시험에서 17% 점수 하락이 나타났어요. 특히 기초 학력이 낮은 학생들에서 더욱 두드러졌어요.
"The central prediction of the never-skilling hypothesis is that AI-assisted performance during training may create a period of false proficiency: apparent competency that depends on AI availability and does not persist when that support is withdrawn or becomes unavailable."
"never-skilling 가설의 핵심 예측은, 훈련 중 AI 보조 성과가 '거짓 숙련(false proficiency)'의 기간을 만들 수 있다는 것이다 — AI가 있을 때만 나타나는 겉보기 역량으로, AI 지원이 사라지면 유지되지 않는다."
⚙️ 세 가지 메커니즘: 어떻게 역량이 형성되지 못하나?
저자들은 never-skilling이 일어난다면 세 가지 경로를 통할 거라고 제안해요.
1. 역량 획득 실패 (Competency acquisition failure)
- 스키마 형성은 노력 있는 인지 처리를 필요로 해요. AI가 답을 먼저 줘버리면 그 형성 과정이 차단됩니다. 당뇨성 케톤산증을 AI 도움으로 진단한 학생이, 비전형적 발현을 혼자서 인식하는 능력을 갖추지 못했을 수 있어요.
2. 교정 역설 (Calibration paradox)
- AI를 언제 믿고, 언제 의심하고, 언제 무시해야 하는지 판단하는 능력 — 보정(calibration) — 은 AI 노출만으로 생기지 않아요. 독립적인 문제 해결, 오류 인식, 피드백의 반복 사이클을 통해서만 길러지죠. 그런데 AI에 처음부터 의존하면 이 사이클 자체가 끊겨요.
"A trainee without an independent clinical architecture cannot verify, only accept. Every AI interaction becomes a leap of faith that foundational competency is supposed to eliminate."
"독립적인 임상 추론 구조가 없는 수련생은 검증할 수 없고, 그저 수용할 수밖에 없다. 모든 AI 상호작용이 기초 역량이 제거해줘야 할 믿음의 도약이 되어버린다."
3. 메타인지 및 전문직 정체성 훼손 (Metacognitive and professional identity deficit)
- AI가 일상적으로 진단 처방과 치료 계획을 제시하면, 수련생들은 자신을 '자율적 추론자'가 아닌 'AI 출력을 중계하는 중간자' 로 이해하게 될 수 있어요. 이건 전문직 정체성 형성(PIF, professional identity formation)의 문제이기도 하죠.
🗺️ 저자들이 제안하는 3단계 프레임워크
논문이 좋은 이유 중 하나는, 문제 제기에서 그치지 않고 실천 가능한 프레임워크를 제안한다는 점이에요.
Phase 1: 기초 역량 단계 (AI 없는 구간)
- 초기 임상 교육에는 AI 없이 사고하는 구조화된 문제 중심 학습(PBL) 구간이 명시적으로 포함되어야 해요. AI를 완전히 금지하는 게 아니라, 학생이 구축해야 할 추론을 AI가 대신 내놓는 방식은 안 된다는 거예요.
- 평가 방법도 바뀌어야 해요: 구술 시험, 직접 관찰 임상 수행, 답만이 아니라 추론 과정을 설명해야 하는 케이스 과제 등이 있어요.
Phase 2: 안내된 통합 단계 (학습 모드)
- 기초 역량이 확립된 뒤에는 AI를 교정(calibration) 을 목표로 도입해요. 핵심은 '적대적 접근(adversarial pedagogy)' — 학생들에게 의도적인 오류가 심어진 AI 생성 임상 추론을 주고, 오류를 찾아내고 설명하고 수정하는 능력을 평가하는 거예요.
- 이때 DEFT-AI 프레임워크(Diagnosis/Discussion, Evidence, Feedback, Teaching, recommendation for AI use)가 교수자용 도구로 제안돼요.
Phase 3: 통합 실습 단계 (협력 모드)
- 전공의 교육 단계에서 적용돼요. EPA(Entrustable Professional Activities) 프레임워크에 AI 통합 과제 평가를 접목하고, 학생이 AI가 접근할 수 없는 맥락적 추론 — 환자의 서술, 신체 검진 소견, 개별 가치 — 을 기여하는 역량을 개발하는 게 목표예요.
"A copilot is only useful if trainees first learn how to be pilots."
"부조종사는 훈련생들이 먼저 조종사가 되는 법을 배웠을 때만 유용하다."
💬 AI가 학습을 촉진할 수도 있다 — 균형 잡힌 시각
논문은 AI가 무조건 나쁘다고 하지 않아요. 어떻게 설계하느냐가 핵심이라는 거죠.
| 답 전달 모드 (never-skilling 위험) | 학습 모드 (잠재적으로 유익) |
| 설명 없이 진단/감별 진단을 직접 제공 | 소크라테스식 질문으로 학생의 추론 유도 |
| 정당화 없이 치료 권고 전달 | 추론 과정 피드백과 함께 임상 시나리오 제시 |
| 진단 과제에서 인지적 노력 제거 | 지속적인 스키마 형성을 위한 의도적 인지 마찰 추가 |
학생이 AI를 '검색 도구'나 '소크라테스식 대화 상대'로 쓰는 건 괜찮아요. 하지만 학생이 고민해야 할 임상 추론을 AI가 대신 내놓는 건 위험해요.
🌍 한국 의학교육에 던지는 질문
이 논문은 한국 상황에서도 시사하는 바가 많아요.
- ASK 2026 인증 준비 중인 학교들이라면: 현재의 역량 기반 의학교육(CBME) 프레임워크가 AI 도구 존재를 얼마나 명시적으로 다루고 있나요? AI 독립적 역량(AI-independent competency)을 졸업 요건으로 구체화한 학교가 국내에 있을까요?
- 임상 교육 환경에서: 스마트폰으로 언제든 GPT나 Claude에 접근할 수 있는 의대생들이 PBL 케이스를 풀 때 실제로 무엇을 하고 있을까요? 교수자들은 이 현실을 얼마나 인식하고 있을까요?
- Meddy 같은 AI 튜터 개발자 입장에서는: "답을 알려주는 AI"와 "추론을 훈련시키는 AI"의 설계 철학이 얼마나 다른지, 이 논문이 명확하게 보여줘요. AI 튜터가 어떤 모드로 작동하느냐가 학습 결과를 완전히 바꿀 수 있어요.
🔬 앞으로의 연구 과제
저자들이 솔직하게 한계를 인정하는 점도 인상적이에요. Never-skilling은 아직 확인된 현상이 아니라 위험 모델이에요. 직접적인 인과 증거는 없어요. 그래서 논문은 네 가지 연구 의제를 제안해요:
- 기초 연구: AI 보조 학습이 핵심 역량을 실제로 저해하는지 종단 무작위 대조 연구
- 커리큘럼 개발: 도구 검증 — 역량 평가 도구, 적대적 케이스 라이브러리 등
- 구현 및 평가: 3단계 프레임워크의 파일럿 적용과 효과 측정
- 정책 번역: 면허 기준, 인증 요건, 글로벌 자격 이동성 기준 수립
마치며
이 논문이 주는 핵심 메시지는 이렇게 정리할 수 있어요:
AI가 의학교육에 나쁜 게 아니라, AI를 언제, 어떤 방식으로 쓰느냐가 문제다.
아직 임상 근거는 부족하지만, 교육학 이론과 인접 분야 신호들은 충분히 주의를 기울일 이유를 줘요. 그리고 한 번 코호트 규모에서 자리 잡히면 감지하기도, 되돌리기도 어렵다는 게 더 무서운 부분이죠.
"The risks of never-skilling warrant attention before the evidence of harm is conclusive."
"never-skilling의 위험은 해악의 증거가 결정적으로 나오기 전에 주의를 기울일 가치가 있다."
조종사가 오토파일럿을 믿기 전에 먼저 수동 조종을 배워야 하듯, 우리 의대생들도 AI와 협력하기 전에 먼저 혼자 날 수 있어야 하지 않을까요? 🛫
대규모 언어모델(large language models, LLMs), 컴퓨터 비전 시스템(computer vision systems), 그리고 AI 기반 임상의사결정지원 시스템(AI-based clinical decision-support systems)은 여러 의학 전문분야(medical specialties) 전반에서 상당한 임상적 가치(clinical value)를 입증해 왔다1–4. 이러한 기술은 진단 정확도(diagnostic accuracy), 약물 안전(medication safety), 업무흐름 효율성(workflow efficiency), 그리고 전문 진료 접근성(access to specialist care)을 향상시켜 왔다5,6. 이러한 발전은 AI와 효과적으로 협업하는 능력이 미래 의사(future physicians)에게 핵심 역량(key competency)이 될 것임을 시사한다. 그러나 중요한 질문은 다음과 같다.
- 안전하고 회복탄력적인 진료(safe and resilient practice)에 필요한 독립적 임상추론(independent clinical reasoning)을 약화시키지 않으면서, AI를 의학교육(medical education)과 초기 전공의 훈련(early residency training)에 어떻게 통합할 수 있는가?
그 함의는 교육 기준(educational standards)을 넘어 환자안전(patient safety), 면허(licensing), 그리고 의료인력 안정성(workforce stability)에까지 확장된다. 만약 훈련생들이 AI의 도움 없이 임상추론을 입증할 수 없다면, 면허 및 자격인증 절차(licensing and credentialing processes)는 실제 역량과 불일치하게 될 수 있다. 그 결과 AI 지원이 있을 때는 잘 기능하지만 시스템이 실패하거나 그러한 도구를 사용할 수 없을 때는 어려움을 겪는 임상의가 배출될 수 있다. 이러한 역학이 대규모로 발생하면 감독(supervision)과 법적 책임(liability)의 부담이 증가하고, 의료인력이 AI 의존 임상의(AI-dependent clinicians)와 AI 비의존 임상의(AI-independent clinicians)로 양분되며, AI 인프라 수준이 서로 다른 의료체계(healthcare systems) 간 격차가 확대될 수 있다.
의학 훈련에서 AI 통합은 역량 발달(competency development)에 세 가지 구분되는 위험을 도입할 수 있다. 탈숙련화(deskilling), 오숙련화(mis-skilling), 그리고 비숙련화(never-skilling)이다.

Table 1 | 핵심 개념과 정의 (Core concepts and definitions)
| 개념(Concept) | 정의(Definition) | 예시적 발현(Example manifestations) |
| Never-skilling | 과도한 AI 대체(excessive AI substitution)가 인지적 노력(cognitive effort)을 대신함으로써 형성기 훈련(formative training) 동안 기초 임상추론 역량(foundational clinical reasoning competencies)을 발달시키지 못하는 것. 그 결과 진급(progression), 졸업(graduation), 또는 면허(licensure)에 필요한 AI 비의존 역량(AI-independent competence)을 입증하지 못하게 된다. | AI 프롬프트 없이 감별진단(differential diagnoses)을 생성하지 못함; AI 제한 환경(AI-restricted settings)에서 관리계획(management plans)을 수립하지 못함; AI 비의존 진급 요건(AI-independent progression requirements)을 충족하지 못함; 주로 초기 기술습득(initial skill acquisition) 단계의 학습자에게 영향을 미침 |
| Deskilling | 장기간 AI 의존(prolonged AI reliance)으로 인해 이미 훈련된 임상의(already trained clinicians)의 확립된 역량(established competencies)이 저하되는 것. 사용하지 않아 기존 신경 경로(existing neural pathways)가 약해지지만, 기초 구조(foundational architecture)는 남아 있다. | 이전에 숙달한 과업에서 측정 가능한 수행 저하(performance decline); 도움 없이 수행할 때 처리 속도 저하와 정확도 감소; 독립적 추론을 통해 사례를 관리할 수 있는 기초 능력(baseline ability)은 보유; 확립된 기초 역량을 가진 숙련된 임상의에게 영향을 미침 |
| Mis-skilling | 오류가 있거나 편향된 AI 산출물(erroneous or biased AI outputs)을 비판 없이 채택함으로써 부정확한 임상추론 패턴(incorrect clinical reasoning patterns)을 습득하는 것. 임상 스키마(clinical schemas)가 AI 오류 또는 편향으로 오염되어 진단 또는 관리추론(diagnostic or management reasoning)이 체계적으로 왜곡된다. | AI 산출물과 일치하는 확신에 찬 부정확한 감별진단(confidently incorrect differential diagnoses); 편향된 진단 연관성(biased diagnostic associations), 예컨대 인종 또는 성별 편향의 내면화; 독립적 추론에서 AI 생성 오류를 반복적으로 재생산; AI 산출물을 검증 없이 수용할 때 모든 훈련 단계에서 발생 |
| Metacognitive calibration | 자신의 역량 경계(competence boundaries)에 대한 정확한 내적 모델링(internal modeling), 그리고 주관적 확신(subjective confidence)과 객관적 수행(objective performance)의 정렬. 이를 통해 적절한 도움 요청(help-seeking behavior)이 가능해진다. | 확신 판단(confidence judgments)이 실제 수행과 일치함; 역량 한계에 가까워질 때 자문(consulting)을 구함; 실행 전 추론 오류를 탐지함; 기술 수준에 맞는 사례를 선택하고 능력을 넘어서는 사례는 거절함 |
| Automation bias | 자동화된 의사결정지원 시스템(automated decision-support systems)에 과의존하여, 모순되는 임상근거(contradictory clinical evidence)가 있어도 그 산출물을 비판 없이 수용하는 경향. AI 권고를 평가하는 데 필요한 기초 스키마(foundational schemas)가 부족한 초보자에게서 취약성이 높아진다. | 병력 또는 신체진찰 소견과 충돌하는데도 AI 생성 진단을 수용함; 실행 전 AI 권고를 독립적으로 검증하지 않음; 반복 노출 후 AI 산출물 감시에 대한 경계심 감소; 숙련된 임상의보다 초기 훈련생에게 불균형적으로 큰 영향 |
| False proficiency | AI 보조 임상추론이 훈련 중에는 충분해 보이는 일시적 수행 상태(transient performance state). 그러나 그 이면의 독립적 역량(independent competency)이 부재하며, 이는 AI 지원이 철회되거나 사용할 수 없게 될 때에야 드러난다. | AI가 가능한 직무기반평가(workplace assessments)에서는 높은 수행을 보이지만 AI 비의존 면허시험(AI-independent licensing examinations)에서는 낮은 결과; AI 지원 없이 임상결정에 대한 자신감이 급격히 붕괴; 감독된 AI 풍부 환경(AI-rich)과 감독되지 않은 AI 없는 환경(AI-free)에서의 임상수행 불일치; AI 지원 결론 뒤의 추론 경로(reasoning pathway)를 설명하는 데 어려움 |
이러한 위험은 훈련 단계(training stages)에 따라 다르게 나타난다.
- 의과대학 교육(medical school education)에서 never-skilling은 학생들이 진급(advancement)에 필요한 독립적 추론(independent reasoning)을 발달시키지 못할 경우 진급 자체를 위협할 수 있다.
- 전공의 훈련(residency training)에서는 우려가 더 미묘하다. 여러 관할권(jurisdictions)의 공식 면허시험(formal licensing examinations)은 대체로 고부담(high-stakes)·표준화 평가(standardized assessments)이며, 여전히 명시적으로 도움 없는 임상추론(unaided clinical reasoning)을 평가하도록 설계되어 있다.
- 그러나 임상 로테이션(clinical rotations)과 직무기반평가(workplace-based assessments)는 AI 도구가 쉽게 이용 가능하고 흔히 사용되는 환경에서 점점 더 많이 이루어진다. 그 결과 훈련생은
- AI가 가능한 임상환경(AI-enabled clinical environments)에서는 적절히 수행하는 것처럼 보이지만,
- AI가 제한된 고부담 평가(AI-restricted, high-stakes assessments)에서 요구되는 독립적 역량(independent competence)을 입증하지 못할 수 있다.
- AI 노출과 임상역량의 약화(erosion of clinical competency)를 직접적으로 연결하는 인과적 근거(direct causal evidence)는 아직 제한적이지만, 초기 신호(early signals)가 나타나기 시작하고 있다8,9.
이러한 우려는 AI가 의학교육(medical education)과 임상진료(clinical care) 모두에서 제공하는 실질적 이점(genuine benefits)과 함께 고려되어야 한다.
- 교육 환경에서는 잘 구조화된 AI 학습 도구(well-structured AI learning tools)가 시험 수행(examination performance)을 향상시키는 것으로 나타났으며10, 더 빠른 피드백 순환(faster feedback cycles), 더 넓은 사례 노출(broader case exposure), 그리고 규모화된 개인맞춤형 연습(personalized practice at scale)을 제공할 수 있다11.
- 임상진료에서는 AI 시스템이 당뇨망막병증 선별(diabetic retinopathy screening)에 대한 접근성을 확대했고12, 의사결정지원 도구(decision-support tools)를 통해 약물 안전(medication safety)을 향상시켰다6,13.
중요한 점은 이러한 시스템의 성공이 AI 산출물(AI outputs)을 비판적으로 평가하고 필요할 때 이를 무시하거나 재정의할 수 있는(override) 충분한 기초 전문성(foundational expertise)을 갖춘 임상의에게 달려 있다는 것이다. 그러나 도입(adoption)은 교육적 준비(educational preparation)보다 빠르게 진행되고 있다. 2024년에 미국 의사의 3분의 2가 AI를 사용한다고 보고한 반면(ref. 14), 공식적 전문성(formal expertise)을 보고한 학생과 교수는 15% 미만이었다15. AI가 흔히 선의의 ‘부조종사(copilot)’16,17로 묘사되지만, 부조종사는 훈련생이 먼저 조종사(pilot)가 되는 법을 배울 때에만 유용하다. 따라서 AI가 임상 전문성(clinical expertise)의 발달을 지원하거나 약화시키는 조건은 여전히 충분히 규명되지 않았다. 바로 이 공백이 아래에서 제시하는 우리의 프레임워크가 다루고자 하는 지점이다.
이 Perspective는 특히 의학 훈련의 형성기(formative stages), 그중에서도 의과대학생과 초기 훈련생(early trainees)을 중심으로, 현장 진료(point-of-care)에서의 진단추론(diagnostic reasoning)을 위해 LLM을 사용하는 문제에 초점을 맞춘다. 이 집단은 AI 대체(AI substitution)가 기초 임상기술(foundational clinical skills) 발달에 미치는 영향에 가장 취약할 수 있다. 우리는 행정 업무(administrative tasks), 문서화(documentation), 또는 과학적 발견(scientific discovery)을 위한 AI 사용은 다루지 않는다. 이러한 영역은 서로 다른 인지적 요구(cognitive demands)와 학습과정(learning processes)을 수반하기 때문이다.
이 맥락에서 우리는 never-skilling을 확립된 경험적 현상(established empirical phenomenon)이 아니라 개념적 위험 모델(conceptual risk model)로 제시한다. 적절한 조건하에서 AI 통합은 인지적 노력을 더 고차원적 추론(higher-order reasoning)으로 전환시키거나, 기계 생성 산출물(machine-generated outputs)을 평가하는 능력과 같은 새로운 역량(new competencies)의 발달을 지원할 수도 있다. 그러나 AI가 풍부한 환경(AI-rich environments)에서 훈련받은 학습자들의 독립적 임상역량(independent clinical competency)을 추적한 종단 근거(longitudinal evidence)는 대체로 부재하다. 따라서 이 Perspective는 AI를 의학 훈련에 안전하고 효과적으로 통합하는 것을 지원하면서도 기초 임상역량(foundational clinical competence)을 보존하기 위한 예방적 프레임워크(precautionary framework)를 제안한다.
근거 기반: 이론적 토대와 초기 신호 (Evidence base: theoretical grounding and early signals)
AI와 이전 의학기술 (AI and prior medical technologies)
새로운 기술은 의학에서 인지적 의존(cognitive dependency)에 대한 우려를 반복적으로 불러일으켜 왔다. 영상의학(imaging)의 도입은 신체진찰 기술(physical examination skills)을 대체한다고 여겨졌다. 전자의무기록(electronic health records)은 임상기억(clinical memory)을 약화시킨다는 비판을 받았다. 계산기(calculators)는 수리능력(numeracy)을 약화시킨다고 여겨졌다. 대부분의 경우, 이러한 불안은 지속적인 해로움(lasting harm)에 대한 근거로 입증되지 않았다. 그렇다면 AI는 왜 다른가?
우려의 핵심은 AI가 기술습득(skill acquisition)과 관련하여 이전 기술들과 두 가지 측면에서 다르다는 데 있다.
- 첫째, 이전 기술들은 요구되는 인지작업(cognitive work)의 유형을 변화시켰지만 그 존재 자체는 보존했다.
- CT 스캔은 해부학적 영상(anatomical images)을 제공하지만, 이를 해석하기 위해서는 전문적인 해부학 지식(expert anatomical knowledge)이 필요하다.
- 검사실 수치(laboratory values)는 임상양상(clinical presentation)과 통합되어야 한다. 전자의무기록은 자료를 조직하지만 진단 결론(diagnostic conclusions)을 생성하지는 않는다.
- 반면 AI는 전체 진단 사슬(entire diagnostic chain)을 자율적으로 수행할 수 있다. 이것은 인지작업의 전환이 아니다. 그것은 인지작업의 대체(substitution)이다.
- 둘째, 노출 시점(timing of exposure)이 다르다18.
- Meshaka와 Arthurs19는 영상에 대한 과의존(overreliance)이 주로 기초 기술을 이미 보유한 훈련된 임상의(trained clinicians)에게서 문서화되었다고 지적한다.
- 그러나 AI는 의과대학 첫날부터 사용할 수 있으며, 이는 임상추론 구조(clinical reasoning architecture)가 아직 형성되기 전이다. 이 맥락에서 질문은 훈련생이 기술을 획득한 뒤 그것을 잃는가가 아니라, 그 기술을 애초에 획득하는가이다.
이 구분은 문제를 어떻게 프레이밍할 것인가에 중요하다. 의학에서 기술로 유발된 일부 의존성(technology-induced dependencies)은 해롭지 않다. 복강경(laparoscopy)이 널리 도입된 이후 훈련받은 외과의는 복강경 없이 수술하는 법을 배우지 않았다. 그럴 필요가 없기 때문이다. 관련된 질문은 AI가 훈련생에게 의존성을 만드는가가 아니다. 아마 그럴 것이다. 핵심 질문은 어떤 의존성은 해롭고, 어떤 의존성은 합리적 위임(rational delegation)을 나타내는가이다.
이에 대한 잠정적 답을 제안할 수 있다. 모든 진료 환경(practice settings), 특히 자원이 제한된 환경(resource-limited settings)에서도 환자안전(patient safety)의 토대가 되는 역량은 독립적 숙달(independent mastery)을 요구한다. 여기에는 병력청취(clinical history taking), 신체진찰(physical examination), 진단가설 생성(diagnostic hypothesis generation), 그리고 불확실성하의 관리계획 수립(management planning under uncertainty)이 포함된다. 반면 모든 현대적 진료 환경에서 일상적으로 기술의 지원을 받는 역량은 위임의 후보가 될 수 있다. 이 구분은 경험적 조사를 필요로 하며, 가정되어서는 안 된다.
중요한 점은 일부 전통적 기술(traditional skills)의 숙련도 감소가 반드시 해로움(harm)을 의미하지는 않는다는 것이다. 예를 들어, 전흉부 청진기(precordial stethoscope)는 카프노그래피(capnography)와 맥박산소측정법(pulse oximetry)이 널리 사용되기 전까지 마취 중 심음과 호흡음을 감시하기 위해 일상적으로 사용되었다. 오늘날 이 청진기는 지속적 전자감시(continuous electronic monitoring)로 대체되면서 일상 마취진료에서 거의 사용되지 않는다20. 그 감소는 임상역량의 상실이 아니라 기술적 진보(technological progress)를 반영한다. AI에도 같은 논리가 적용된다.
- 일부 형태의 AI 의존성은 효율성과 안전성을 향상시키는 새로운 도구에 대한 적절한 적응(appropriate adaptation)일 수 있다.
- 다른 일부는 AI 시스템을 사용할 수 없거나 잘못되었을 때 환자안전에 대한 진정한 위협(genuine threat)이 될 수 있다.
- 따라서 이 가능성들을 구분하는 것이 중요하며, 이를 위해서는 영역별 경험적 연구(domain-specific empirical study)가 필요하다.
이론적 토대 (Theoretical grounding)
교육과학(educational science)은 직접적인 임상 근거와는 별개로, 형성기 훈련에서 AI 대체(AI substitution)를 우려할 수 있는 원리적 기반을 제공한다.
- 바람직한 어려움 이론(desirable difficulties theory)은 단기적으로 학습을 더 어렵게 만드는 조건이 장기적으로 더 지속적인 파지(retention)와 전이(transfer)를 만들어내는 경향이 있다고 본다21. 정답을 쉽게 사용할 수 있게 만드는 것은 지식이 공고화(consolidated)되는 데 필요한 인지적 노력(cognitive effort)을 제거한다. 이 이론은 AI의 정답 제공(answer delivery)이 훈련 중에는 겉보기 수행 향상(apparent performance gains)을 만들어낼 수 있지만, 그것이 독립적 역량(independent competency)으로 전환되지 않을 수 있음을 예측한다.
- 의도적 연습 이론(deliberate practice theory)은 노력과 피드백이 풍부한 문제해결(effortful, feedback-rich problem-solving)이 전문가적 추론(expert reasoning)이 발달하는 기제라고 본다22. 훈련생이 임상 진단을 독립적으로 구성하는 대신 AI를 사용해 생성한다면, 그들은 경험 시간(experience hours)을 축적할 수는 있지만 그 시간이 산출하도록 설계된 인지적 투자(cognitive investment)는 축적하지 못할 수 있다.
- 인지부하 이론(cognitive load theory)은 임상추론의 토대인 스키마 구성(schema construction)이 작업기억(working memory)에서의 노력적 처리(effortful processing)에 달려 있다고 제안한다23. 이 처리를 우회하는 AI 도구는 스키마 구성을 지원하기보다는 방해할 수 있다. 그 결과 훈련생은 AI 산출물과 상호작용하는 데는 능숙하지만, AI 없이 추론하는 데 필요한 기저 인지구조(underlying cognitive structures)를 구축하지 못할 수 있다.
- 전문성 역전 효과(expertise reversal effect)는 특히 중요하다24. 초보 학습자(novice learners)에게 도움이 되는 교수적 지원(instructional support)이 전문가에게는 중립적이거나 해로울 수 있다. 전문가는 추가 안내를 중복되게 만드는 기존 스키마(existing schemas)를 가지고 있기 때문이다. 이는 AI 지원이 초보자와 숙련된 임상의에게 서로 다르게 작용할 수 있음을 예측하며, 사용 패턴에 따라 증강(augmentation)과 저하(degradation)의 가능성이 모두 존재함을 시사한다. 초보자에게 AI는 기초 스키마를 구축하는 과정을 대체할 수 있다. 숙련된 임상의에게 AI는 이미 확립된 추론을 증강할 수 있지만, 과도하게 의존할 경우 탈숙련화의 위험도 있다. 이것은 발달 단계별 프레임워크(developmental stage-specific framework)를 위한 이론적 토대를 제공한다.
초기 경험적 신호 (Early empirical signals)
임상 훈련생(clinical trainees)에서 never-skilling에 대한 직접 근거는 현재 부족하다. 필요한 종단 연구(longitudinal studies)가 아직 수행되지 않았기 때문이다. 이용 가능한 근거는 간접적이지만 시사적이다.
- Budzyń et al.8은 AI 보조 대장내시경(AI-assisted colonoscopy)을 일상적으로 사용한 숙련된 내시경 의사(experienced endoscopists)가 이후 AI 없이 시행한 절차에서 선종 발견율(adenoma detection rate)이 6% 낮았다고 보고했으며, 이는 훈련된 임상의에서 잠재적 탈숙련화(potential deskilling)와 일치한다.
- 임상 맥락 밖에서 Kosmyna et al.9은 LLM 보조 글쓰기(LLM-assisted writing)의 지속적 사용이 AI 도움 없이 글을 쓰는 경우와 비교해 더 약한 신경 연결성(neural connectivity)과 자기 생성 내용(self-generated content)에 대한 더 낮은 회상(poorer recall)과 관련됨을 관찰했다9.
- 종합하면, 이러한 결과는 확정적 근거(definitive evidence)가 아니라 예비 신호(preliminary signals)로 해석되어야 한다.
교육 분야의 실험 연구는 그럴듯한 기제(plausible mechanism)에 대해 더 직접적인 지지를 제공한다.
- 고등학생을 대상으로 한 무작위 연구에서 Bastani et al.25은 AI 튜터(AI tutor)에 대한 제한 없는 접근이 보조 연습(assisted practice) 중 수행을 향상시켰지만, 이후 AI 도움 없이 폐쇄형 책상시험(unaided, closed-book mathematics examination)에서 정규화 점수(normalized scores)가 상대적으로 17% 감소한 것과 관련되었다고 보고했다(0–1 척도에서 평균 차이: −0.054). 가장 큰 손상은 기초 성취도(baseline achievement)가 낮은 학생들에게서 관찰되었다.
- 이 연구는 의학 훈련 밖에서 수행되었지만, AI 지원이 기저 역량(underlying competence)의 결손을 가리면서 지속적이고 독립적인 기술 발달(durable independent skill development)을 저해할 수 있음을 보여주는 가장 명확한 실험적 예시를 제공한다.
- Gerlich et al.26의 추가적인 상관 근거도 있다. 이들은 성인 666명을 조사하여 AI 도구 사용과 비판적 사고능력(critical thinking ability) 사이에 음의 관련성이 있으며, 이 관련성이 인지적 오프로딩(cognitive offloading)에 의해 매개되고 젊은 참여자에서 가장 두드러진다고 보고했다. 전반적으로, 비임상 집단(nonclinical populations)에서의 이러한 결과는 임상교육(clinical education)에 대한 우려가 그럴듯하다는 점을 시사하지만, 아직 입증된 것은 아니다. 임상 훈련생에서 never-skilling에 대한 직접 근거는 여전히 부재하다.
이러한 여러 근거의 흐름은 훈련 중 AI 노출의 시점(timing of AI exposure)이 중요할 수 있음을 시사한다. 핵심 역량(core competencies)을 개발한 후 AI 도구가 도입되는 임상의는 때때로 탈숙련화를 경험할 수 있다. 반면 형성기 학습(formative learning) 중 AI에 노출되는 훈련생은 이러한 역량을 완전히 획득하지 못할 위험이 있다. never-skilling 가설의 핵심 예측은 훈련 중 AI 보조 수행(AI-assisted performance)이 거짓 숙련감(false proficiency)의 시기를 만들어낼 수 있다는 것이다. 즉, 역량이 있는 것처럼 보이지만, 실제로는 AI 가용성(AI availability)에 의존하고 그 지원이 철회되거나 사용할 수 없게 되었을 때 지속되지 않는 역량이다.
학습 촉진제로서의 AI에 대한 주장 (The case for AI as a learning accelerant)
상당한 검토가 필요한 그럴듯한 대안적 관점이 있다. AI 도구가 정답 제공(answer delivery)이 아니라 학습(learning)을 위해 의도적으로 설계될 때, 그것은 기초 역량 발달(foundational competency development)을 가속화할 수 있다.
- 적응형 AI 튜터(adaptive AI tutors)는 단일 훈련기관(single training site)이 제공할 수 있는 것보다 더 넓은 범위의 임상 사례(clinical cases)에 학습자를 노출시킬 수 있다. 또한 추론 과정(reasoning processes)에 즉각적 피드백(immediate feedback)을 제공하고, 학습자의 현재 수준에 맞게 사례 난이도(case difficulty)를 조정할 수 있다. 이러한 조건은 교육과학 분야에서 효과적인 기술 발달(effective skill development)과 관련된 것으로 알려져 있다.
- 최근 근거도 이를 지지한다. Leong et al.10은 특화된 교육용 챗봇(specialized educational chatbot)이 대학원 의학시험(postgraduate examination) 준비에서 표준 챗봇(standard chatbot)보다 전공의들에게 더 유용하고 효율적인 것으로 인식되었음을 보여주었다.
- Wang et al.27은 답을 제공하는 대신 질문을 던지는 소크라테스식 AI 튜터(Socratic AI tutor)를 표준 AI와 비교했으며, 소크라테스식 조건에서 더 높은 임상추론 참여(clinical reasoning engagement)가 나타났다고 보고했다. 이러한 결과는 AI 설계(AI design)가 교육성과(educational outcomes)를 형성한다는 점을 보여준다.
- Never-skilling의 위험은 AI 그 자체의 위험이 아니라, 인지구조(cognitive architecture)가 아직 발달 중인 시기에 AI를 정답 제공 방식(answer-delivery mode)으로 사용하는 데 따른 위험이다.
우리는 AI가 해로울 수 있는 경우와 도움이 될 수 있는 경우를 명확히 하기 위해 하나의 구분을 제안한다(Table 2). 임상 환경(clinical environments)에 배치되는 대부분의 AI 도구는 정답 제공 방식(answer-delivery mode)으로 작동한다. 이는 그 의도된 목적에는 적절하다. 우려는 훈련생들이 형성기 훈련 동안, 학습 방식의 참여(learning-mode engagement)가 가장 유익할 수 있는 바로 그 발달 단계에서, 주로 정답 제공 방식의 AI(answer-delivery mode AI)를 접하게 될 수 있다는 점이다.
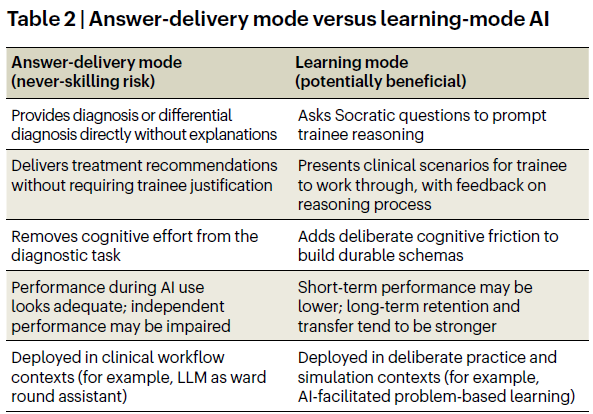
Table 2 | 정답 제공 방식과 학습 방식의 AI (Answer-delivery mode versus learning-mode AI)
| 정답 제공 방식(Answer-delivery mode) - never-skilling 위험 | 학습 방식(Learning mode) - 잠재적으로 유익 |
| 설명 없이 진단 또는 감별진단(diagnosis or differential diagnosis)을 직접 제공한다. | 훈련생의 추론을 촉진하기 위해 소크라테스식 질문(Socratic questions)을 던진다. |
| 훈련생의 정당화(trainee justification)를 요구하지 않고 치료 권고(treatment recommendations)를 제공한다. | 훈련생이 해결해 나갈 임상 시나리오(clinical scenarios)를 제시하고, 추론 과정에 대한 피드백을 제공한다. |
| 진단 과제(diagnostic task)에서 인지적 노력(cognitive effort)을 제거한다. | 지속 가능한 스키마(durable schemas)를 구축하기 위해 의도적인 인지적 마찰(deliberate cognitive friction)을 추가한다. |
| AI 사용 중 수행은 적절해 보일 수 있으나, 독립적 수행(independent performance)은 손상될 수 있다. | 단기 수행(short-term performance)은 낮을 수 있으나, 장기 파지(long-term retention)와 전이(transfer)는 더 강해지는 경향이 있다. |
| 임상 업무흐름 맥락(clinical workflow contexts)에 배치된다. 예: 병동 회진 보조자(ward round assistant)로서의 LLM. | 의도적 연습(deliberate practice)과 시뮬레이션 맥락(simulation contexts)에 배치된다. 예: AI 촉진 문제기반학습(AI-facilitated problem-based learning). |
기전 경로: AI 대체에서 역량 위험으로 (The mechanistic pathway: from AI substitution to competency risk)
Never-skilling이 발생한다면, 그것은 세 가지 상호 관련된 기제(interrelated mechanisms)를 통해 작동할 가능성이 있다. 역량 획득 실패(competency acquisition failure), 보정 결손(calibration deficit), 그리고 메타인지 침식(metacognitive erosion)이다. 각각은 가설이며, 여기서는 이를 조사를 위한 프레임워크(framework for investigation)로 제시한다. 위험의 정도는 임상 영역(clinical domains)과 기초 임상기술(foundational clinical skills)에 따라 상당히 다를 가능성이 있다.
- 방사선과(radiology), 병리학(pathology), 피부과(dermatology)와 같은 패턴 인식 전문과목(pattern-recognition specialties)은
- 수술(surgery)이나 응급의학(emergency medicine)처럼 체화된 기술(embodied skills)과 실시간 의사결정(real-time decision-making)이 핵심인 절차 중심 분야(procedural fields)와는 다른 AI 대체 역학(AI substitution dynamics)을 마주할 수 있다.
임상추론 내에서도 일부 인지기능(cognitive functions)은 다른 기능보다 대체에 더 취약할 수 있다. 이러한 변이는 영역별 연구설계(domain-specific research designs)에 통합되어야 한다.
역량 침식의 핵심 기제 (Core mechanisms of competency erosion)
- 역량 획득 실패(Competency acquisition failure).
- AI 시스템이 형성기 훈련 동안 답을 제공하면, 임상추론 스키마(clinical reasoning schemas)의 구성을 방해할 수 있다. 스키마 형성(schema formation)은 노력적 처리(effortful processing)를 필요로 한다23. AI 도움으로 당뇨병성 케톤산증(diabetic ketoacidosis)을 올바르게 진단한 학생은, 비전형적 양상(atypical presentations)을 독립적으로 인식할 수 있게 하는 패턴 인식(pattern-recognition) 및 병태생리학적 추론망(pathophysiological reasoning networks)을 구축하지 못했을 수 있다.
- 생산적 실패 이론(productive failure theory)은 해결책을 받기 전에 문제와 씨름하는 것이, 해결책을 먼저 받는 것보다 장기적 개념 이해(long-term conceptual understanding)를 더 잘 만들어낸다고 예측한다28. 이를 임상 훈련에 적용하면, 훈련생이 스스로 진단을 시도하기 전에 AI 시스템이 진단을 제공하는 것은, 제공된 진단이 정확하더라도 지속 가능한 학습(durable learning)을 위한 인지적 조건(cognitive conditions)을 약화시킬 수 있음을 시사한다.
- 초기 훈련 동안 인지구조(cognitive architecture)가 불완전하게 형성된다면, 그 결과로 나타나는 결손(deficit)은 탐지하기 어려울 수 있다. AI 보조 수행은 AI 없는 수행(unaided performance)이 상당히 손상되어 있더라도 적절해 보일 수 있다. 이러한 결손이 되돌리기 어려워지는 임계점(threshold)은 알려져 있지 않다. 신경가소성(neural plasticity)은 늦은 교정(late remediation)을 가능하게 할 수 있다. 그러나 나중의 훈련 단계에서의 교정이 동일하게 효과적인지는 열려 있는 경험적 질문(open empirical question)이다.
- 보정 역설(Calibration paradox).
- 효과적인 AI 감독(AI oversight)은 보정(calibration), 즉 언제 AI 산출물을 신뢰하고, 질문하고, 또는 무시/재정의할지(override) 아는 능력을 요구한다. 이 능력은 AI 노출만으로 생기지 않는다. 그것은 자신의 지식의 한계(limits of one’s knowledge)에서 독립적 문제해결(independent problem-solving), 오류 인식(error recognition), 피드백(feedback)의 순환을 통해 발달한다. 그런데 이 순환이 바로 비판 없는 AI 사용(uncritical AI use)에 의해 방해받는다. 임상추론 스키마를 구축하기 전에 AI를 접하는 훈련생은 AI 산출물에 익숙해질 수는 있지만, 그것을 평가하는 데 필요한 기초(foundation)는 갖추지 못할 수 있다. 그 결과는 인지적 도덕적 해이(cognitive moral hazard)이다. 인식론적 책임(epistemic responsibility)이 포기되는데, 이는 위임(delegation)이 적절하기 때문이 아니라 훈련생이 적절한 위임과 비판 없는 수용(uncritical acceptance)을 구분하지 못하기 때문이다29.
- 이 취약성은 LLM의 구조적 특성(structural property)에 의해 증폭된다. LLM은 부정확한 결론에 대해서도 높은 확신(high confidence)을 표현할 수 있으며, 이는 전문 임상의는 종종 탐지할 수 있지만 초보자는 탐지하지 못하는 전문성의 환상(illusion of expertise)을 만들어낸다30. 항공(aviation), 원자력(nuclear power), 마취과(anesthesiology) 전반의 근거는 자동화된 모니터링(automated monitoring)이 인간의 경계심(human vigilance)을 낮추며, 초보자가 전문가보다 더 취약하다는 점을 일관되게 보여준다31. 의학교육에서 AI 지원을 통해 가장 큰 이득을 얻을 수 있는 비전문가(nonspecialists)는 동시에 과의존(overreliance)에 가장 취약한 사람들이다32,33.
- Abdulnour et al.7은 이 문제의 구조적 성격을 ‘검증하고 신뢰하기(verify and trust)’ 패러다임을 통해 명확히 한다. 임상의는 AI 산출물을 신뢰하기 전에 자신의 독립적 임상추론(independent clinical reasoning)과 외부 근거(external evidence)에 비추어 검증해야 한다. 검증에는 대조할 수 있는 인지적 기준(cognitive standard)이 필요하다. 독립적인 임상 구조(independent clinical architecture)가 없는 훈련생은 검증할 수 없고, 오직 수용할 수 있을 뿐이다. 모든 AI 상호작용은 기초 역량이 제거해야 할 믿음의 도약(leap of faith)이 된다. 따라서 보정 결손(calibration deficit)은 단순히 AI를 지나치게 신뢰하는 위험이 아니라, 검증이 요구하는 기반구조(infrastructure)가 부재한 상태이다(Fig. 1). 우리는 인간-AI 협력(human–AI collaboration)이 본질적으로 해롭다고 주장하지 않는다. 협력적 수행(collaborative performance)에 대한 근거는 다양하며34,35, AI 증강(AI augmentation)은 명확하게 정의된 과업(well-defined tasks)에서 임상능력을 의미 있게 확장할 수 있다. 핵심 기술은 AI가 가치를 더하는 맥락과 그렇지 않은 맥락을 구분하는 데 있으며, 이 역시 비판 없는 AI 사용이 약화시키는 독립적 추론의 산물이다.
- 메타인지 및 전문직 정체성 결손(Metacognitive and professional identity deficit).
- 의학 훈련은 기술적 역량(technical competency)뿐 아니라 메타인지적 성숙(metacognitive maturity)을 발달시키는 것을 목표로 한다. 이는
- 자신의 추론을 감시하고(monitor one’s own reasoning),
- 불확실성을 인식하며(recognize uncertainty),
- 모호성을 견디고(tolerate ambiguity),
- 지적 겸손(intellectual humility)을 유지하는 능력이다36.
- 이러한 속성은 쉬운 답이 없는 어려운 문제와의 지속적 관여(sustained engagement)를 통해 발달할 수 있다37.
- AI 시스템이 진단적 구성(diagnostic formulations)과 관리 결정(management decisions)을 일상적으로 제공할 때, 그것은 훈련생이 자신의 전문직 역할(professional role)을 이해하는 방식을 재형성할 수 있다. 훈련생은 자율적 추론자(autonomous reasoners)로 발달하기보다 AI 산출물을 해석하고 전달하는 중개자(intermediaries)로 자신을 이해하게 될 수 있다38. 이러한 전문직 정체성(professional identity)의 변화가 실제로 발생하는지, 그리고 그것이 임상수행(clinical performance)에 측정 가능한 결과를 갖는지는 경험적 질문이다.
- 의학 훈련은 기술적 역량(technical competency)뿐 아니라 메타인지적 성숙(metacognitive maturity)을 발달시키는 것을 목표로 한다. 이는
Fig. 1 | AI 대체에서 임상역량 위험으로 이어지는 기전 경로
(The mechanistic pathway from AI substitution to clinical competency risk)
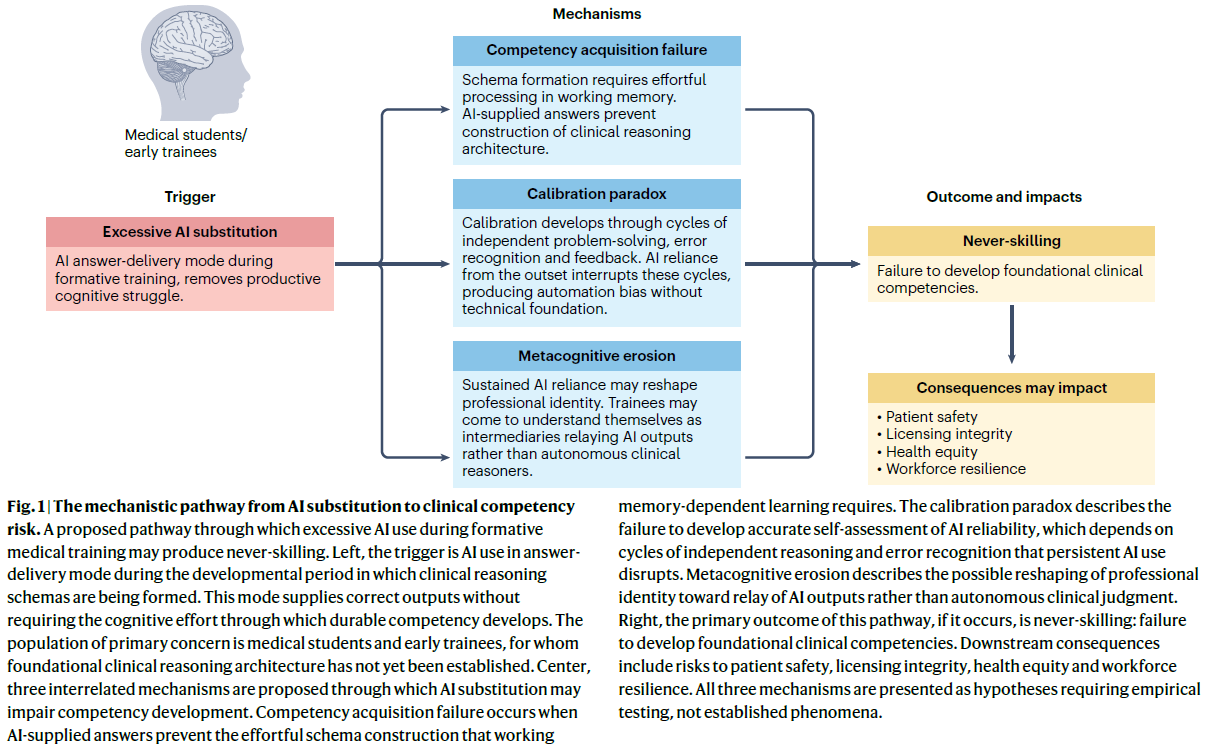
- 의학 훈련의 형성기 동안 과도한 AI 사용(excessive AI use)이 never-skilling을 만들어낼 수 있는 제안된 경로이다.
- 왼쪽에서 촉발 요인(trigger)은 임상추론 스키마(clinical reasoning schemas)가 형성되는 발달 시기(developmental period)에 AI를 정답 제공 방식(answer-delivery mode)으로 사용하는 것이다.
- 이 방식은 지속 가능한 역량(durable competency)이 발달하는 데 필요한 인지적 노력(cognitive effort)을 요구하지 않고 정확한 산출물(correct outputs)을 제공한다. 주요 관심 집단(population of primary concern)은 아직 기초 임상추론 구조(foundational clinical reasoning architecture)가 확립되지 않은 의과대학생과 초기 훈련생이다.
- 가운데에는 AI 대체가 역량 발달(competency development)을 손상시킬 수 있는 세 가지 상호 관련 기제가 제안되어 있다.
- 역량 획득 실패(competency acquisition failure)는 AI가 제공한 답이 작업기억 의존 학습(working memory-dependent learning)이 요구하는 노력적 스키마 구성(effortful schema construction)을 방해할 때 발생한다.
- 보정 역설(calibration paradox)은 AI 신뢰성(AI reliability)에 대한 정확한 자기평가(self-assessment)가 발달하지 못하는 것을 설명한다. 이는 독립적 추론과 오류 인식의 순환에 달려 있지만, 지속적인 AI 사용이 이 순환을 방해한다.
- 메타인지 침식(metacognitive erosion)은 전문직 정체성(professional identity)이 자율적 임상판단(autonomous clinical judgment)이 아니라 AI 산출물의 전달(relay of AI outputs) 쪽으로 재형성될 가능성을 설명한다.
- 오른쪽에서 이 경로가 발생할 경우의 주요 결과(primary outcome)는 never-skilling, 즉 기초 임상역량(foundational clinical competencies)을 발달시키지 못하는 것이다.
- 하류 결과(downstream consequences)는 환자안전(patient safety), 면허의 완전성(licensing integrity), 건강 형평성(health equity), 의료인력 회복탄력성(workforce resilience)에 대한 위험을 포함한다. 세 가지 기제 모두 확립된 현상이 아니라 경험적 검증(empirical testing)이 필요한 가설(hypotheses)로 제시된다.
의학교육을 넘어선 never-skilling의 결과 (Consequences of never-skilling beyond medical education)
- 글로벌 건강 형평성과 계층화된 의사 시스템(Global health equity and the tiered physician systems).
- 규제되지 않은 AI 통합(unregulated AI integration)은 임상역량이 AI 인프라에 종속된 의사들을 만들어낼 수 있다. 이러한 의사들은 AI가 신뢰할 수 있는 자원 풍부 환경(well-resourced settings)에서는 잘 수행할 수 있지만, 자원이 제한된 환경(resource-limited settings), 시스템 장애(system failures), 또는 응급 상황(emergency conditions)에서는 어려움을 겪을 수 있다39,40.
- 반면 AI 기술은 의료 형평성(healthcare equity)을 향상시킬 상당한 잠재력도 가지고 있다. 결핵 진단(tuberculosis diagnosis)을 위한 AI 기반 흉부 방사선사진 해석(AI-based chest radiograph interpretation)은 전문 영상의학과 의사(specialist radiologists)가 없는 환경에서 진단 접근성(diagnostic access)을 확대했다. 형평성 논거(equity argument)는 양방향으로 작동한다.
- AI는 서비스가 부족한 환경(underserved settings)에 전문성을 확장함으로써 전 세계적 격차(global disparities)를 줄일 수 있다.
- 동시에 AI가 풍부한 훈련 환경(AI-rich training environments)에서 졸업한 사람들이 AI 없이 진료할 수 없다면 격차를 만들 수도 있다.
- 순효과(net effect)는 실행(implementation)에 달려 있다. 필수적 기초 역량 보호장치(mandatory foundational competency safeguards)를 포함하는 AI 통합은 AI가 전 세계적 격차를 악화시키는 것이 아니라 줄이도록 할 수 있다. 그러한 보호장치 없는 AI 통합은 계층화된 의료인력(tiered workforce)을 만들어낼 위험이 있다.
- 거버넌스와 책무성의 공백(Governance and accountability gaps).
- 의학교육에는 AI 통합을 위한 일관된 거버넌스 프레임워크(coherent governance frameworks)가 부족하다. 규제기관(regulatory bodies)은 역량 보호장치(competency safeguards)를 집행할 수 있는 메커니즘이 제한적이다41. 상업적 AI 공급자(commercial AI vendors)는 장기적 교육성과(long-term educational outcomes)에 대해 책임을 지지 않는다. 미국 식품의약국(US Food and Drug Administration)은 임상의사결정지원(clinical decision support)에 대한 감독에서 교육용 애플리케이션(educational applications)을 명시적으로 제외한다42.
- 현재의 역량 프레임워크(competency frameworks)는 AI가 존재하는 상황에서 임상역량(clinical competence)을 어떻게 입증해야 하는지를 아직 명시하지 않는다. 임상 훈련에서 AI와 무관한 독립적 역량(AI-independent competency)에 대한 명시적 기준이 없다는 점은, 임상 학습환경(clinical learning environments)에서 AI 사용이 확대됨에 따라 선제적 주의(proactive attention)가 필요한 공백을 만든다.
- 의료인력 계획과 리더십 파이프라인(Healthcare workforce planning and leadership pipeline).
- AI 의존 의사(AI-dependent physicians) 집단은 의료인력 계획(workforce planning)의 재구성을 요구할 것이다. 지속적인 AI 인프라를 필요로 하는 의사는 AI 가용성이 덜 일관적인 곳에서 더 많은 감독을 필요로 할 수 있으며, 이는 단순 인원수 지표(headcount metrics)로는 포착되지 않는 인력 부족(workforce shortfalls)을 만들 수 있다.
- 학문의학(academic medicine)에 대한 함의는 추정적(speculative)이며 입증하기 어렵다. 한 세대 훈련생의 기초 역량 감소가 다음 세대의 감독(supervision)과 교육(teaching)의 질에 영향을 미칠 수 있다는 가능성은, 이 인과 사슬(causal chain)이 입증되지 않았음을 인정하면서도, 하류 우려(downstream concern)로 언급할 가치가 있다.
- 전 세계 의사 이동성과 자격 인정(Global physician mobility and credential recognition).
- 의사 면허(medical licensure)는 전이 가능한 역량(transferable competency)을 전제로 한다. 만약 역량이 AI 인프라에 종속된다면, 자격의 이동성(credential portability)이 영향을 받을 수 있다. 의사 면허기관(medical licensing bodies)은 언젠가 AI 보조 조건(AI-assisted conditions)에서 검증된 자격과 AI 비의존 조건(AI-independent conditions)에서 검증된 자격을 구분해야 할 수도 있다. 이는 분야가 지금부터 예상하기 시작해야 하는 미래의 우려이다.
책임 있는 AI 통합을 위한 프레임워크 (A framework for responsible AI integration)
AI 임상도구(AI clinical tools)는 실제적이고 근거 기반의 이점(genuine, evidence-based benefits)을 제공한다. 적절하게 훈련된 임상의가 사용할 때, AI는 진단 정확도(diagnostic accuracy)를 높이고, 오류(errors)를 줄이며, 효율성(efficiency)을 향상시키고, 서비스가 부족한 환경(underserved settings)에 전문성을 확장할 수 있다. 이 프레임워크의 목적은 AI 사용을 제한하는 것이 아니다. 목적은 임상의가 먼저 효과적이고 비판적인 AI 사용(effective, critical AI use)을 가능하게 하는 기초 역량(foundational competencies)을 발달시키도록 보장하는 것이다.
우리는 이를 정책 명령(policy mandate)이 아니라 가설 기반의 예방적 프레임워크(hypothesis-driven, precautionary framework)로 제시한다. 그 효과는 경험적으로 검증되지 않았다. 보편적 기준(universal standard)이 아니라 엄격한 평가(rigorous evaluation)를 포함한 일련의 파일럿 연구(pilot studies)로 실행되어야 한다.
제안하는 세 단계 프레임워크 (Proposed three-phase framework)
- 1단계: 기초 역량, AI 없는 방식(Phase 1: Foundational competency, AI-free mode).
- 대부분의 관할권(jurisdictions)에서 공식 면허시험(formal licensing examinations)은 이미 AI에 의존하지 않는 임상추론(AI-independent clinical reasoning)을 요구한다. 이 단계가 다루는 우려는 공식 시험이 아니라, 사례 기반 학습(case-based learning), 병동 회진(ward rounds), 문제해결 연습(problem-solving exercises) 중 AI 도구가 점점 더 존재하는 더 넓은 임상 훈련 환경(broader clinical training environment)이다.
- 1단계는 초기 임상훈련(early clinical training)에 AI 없는 문제기반학습(AI-free problem-based learning)의 명시적으로 구조화된 기간(explicitly structured periods)이 포함되어야 한다고 제안한다. 이것은 모든 교육활동에서 AI를 금지한다는 의미가 아니다. AI는 학습 보조도구(study aid), 연습문항 생성기(practice question generator), 또는 모의환자(simulated patient)로 기능할 수 있다. 단, 임상추론을 대체해서는 안 된다. 핵심 구분은 AI가 훈련생이 구성해야 하는 답을 제공하는 경우와, 훈련생이 독립적으로 개발하고 있는 추론의 연습을 AI가 촉진하는 경우 사이에 있다.
- 오늘날 AI 없는 학습환경(AI-free learning environments)을 구현하는 데는 실제적 어려움이 있다. 의과대학생들은 LLM에 접근할 수 있는 스마트폰을 가지고 있으며, AI 사용을 감시하는 것은 가능하지 않다. 가능한 것은 AI 비의존 역량(AI-independent competency)을 드러내는 평가과제(assessment tasks)를 설계하는 것이다. 여기에는 구술시험(oral examinations), 관찰된 임상 만남(observed clinical encounters), 그리고 최종 답(final answers)의 제시보다 추론 설명(reasoning explanation)을 요구하는 구조화 사례(structured cases)가 포함된다. 이러한 접근은 이미 의학교육에 존재한다. 이 프레임워크는 AI 통합 훈련(AI-integrated training)으로 진입하기 전에 AI 비의존 역량 입증(AI-independent competency demonstration)을 명시적이고 문서화된 이정표(explicit and documented milestone)로 만들 것을 제안한다.
- 자동조종 시스템(autopilot systems)의 사용과 함께 수동 비행 숙련도(manual flight proficiency)를 입증해야 하는 항공훈련(aviation training)과 비유할 수 있다31. 이 비교가 완전히 정확한 것은 아니지만, 더 넓은 원칙을 보여준다. 기술적 지원에 의존하기 전에 기초 역량(foundational competence)이 선행되어야 한다.
- 2단계: 지도된 통합, 학습 방식(Phase 2: Guided integration, learning mode).
- 기초 역량(baseline competency)이 확립되면, 2단계는 보정(calibration), 즉 언제 AI 산출물을 신뢰하고, 질문하고, 또는 무시/재정의할지(override)를 아는 것을 중심으로 구조화된 교수법(pedagogy)을 통해 AI를 도입한다. 핵심 접근은 적대적(adversarial)이다. 학생들은 의도적 오류(deliberate errors)를 포함한 AI 생성 임상추론(AI-generated clinical reasoning)을 접하고, 이를 탐지하고(detect), 설명하며(explain), 수정하는(correct) 능력으로 평가받는다. 경쟁하는 임상 관점(competing clinical perspectives)을 모의하는 다중 에이전트 구조(multi-agentic architectures)는 학생들이 접하는 오류 유형(error types)의 범위를 넓힐 수 있다43. 삽입된 오류(embedded errors)는 앵커링 편향(anchoring bias), 금기사항을 표시하지 못함(failure to flag contraindications), 맥락 속 검사실 수치의 오해(misinterpretation of laboratory values in context)를 포함하여 해당 임상 영역에 특이적인 문서화된 AI 실패 양식(documented AI failure modes)을 반영해야 한다. 임상 전문가(clinical experts)에 의한 검증(validation)과 반복적 파일럿 테스트(iterative pilot testing)는 교육과정으로 배치되기 전에 필요한 전제조건이다.
- 인정해야 할 한계는 명확하게 표시된 모의 오류(clearly labeled, simulated errors)에 대한 훈련이 실제 임상 환경(real clinical settings)으로 전이되지 않을 수 있다는 것이다. 실제 환경에서 AI 실패는 종종 미묘하고(subtle), 표시되어 있지 않으며(unlabeled), 그럴듯한 추론(otherwise plausible reasoning) 속에 내재되어 있기 때문이다. 이 한계를 다루려면 현실적인 적대적 사례(realistic adversarial cases)를 의도적으로 설계해야 한다. AI 개발자와 임상 전문가는 오류가 겉으로는 일관된 임상 논증(otherwise coherent clinical arguments) 전반에 분산되어 실제에서 마주치는 모호성(ambiguity)을 모방하는 시나리오를 공동으로 구성해야 한다. 목표는 훈련생에게 단순히 부정확한 산출물을 거부하도록 가르치는 것이 아니라, AI 추론을 심문하고(interrogate AI reasoning), 불확실성의 지점(points of uncertainty)을 식별하며, 그 권고를 언제 수용하고(accepted), 수정하고(modified), 또는 무시/재정의해야 하는지(overridden)를 정당화하는 능력을 기르는 것이다.
- 따라서 적대적 세션(adversarial sessions)은 학생들이 AI 도움을 받아 또는 받지 않고 짝지어진 임상 과제(matched clinical tasks)를 수행한 뒤 결과를 비교하는 보정 연습(calibration exercises)과 짝을 이루어야 한다. 이러한 성찰적 순환(reflective cycles)은 반사적 신뢰(reflexive trust)나 반사적 회의(reflexive skepticism)가 아니라 보정된 의존(calibrated reliance)이 발달하는 제안된 기제이다. 학습목표는 AI가 진정한 진단적 가치(genuine diagnostic value)를 더하는 위치를 식별하고, AI가 오류를 도입하는 위치를 인식하며, 임상 영역 전반에서 AI와 비교한 자신의 수행에 대한 정확한 모델(accurate model)을 구축하는 것을 포함한다.
- 감독 수준(supervisory level)에서 DEFT-AI 프레임워크(Diagnosis, Evidence, Feedback, Teaching, and recommendation for AI use)는 교육자에게 우발적 AI 접촉(incidental AI encounters)을 의도적 교수 순간(deliberate teaching moments)으로 전환할 수 있는 실제적 구조를 제공한다7. 이 프레임워크는 교육자가 학습자의 AI 사용을 관찰할 때 순차적 대화를 안내한다. 어떤 AI가 어떻게 사용되었는지(diagnosis/discussion/discourse)를 확인하고, 산출물이 어떻게 검증되었는지(evidence)를 탐색하며, 학습자가 자신의 AI 참여(AI engagement)를 성찰하도록 촉진하고(feedback), 적절한 사용에 대한 초점화된 교육(teaching)을 제공하며, 이후 상호작용을 위한 학습자 맞춤형 지침(recommendation for AI engagement)을 제공한다.
- 3단계: 통합된 실천, 협력 방식(Phase 3: Integrated practice, collaboration mode).
- 3단계는 주로 전공의 훈련(residency training)에 적용된다. 이 단계에서는 위임가능 전문직 활동(entrustable professional activities, EPAs)이 AI 통합 과업 평가(AI-integrated task evaluation)를 통합할 수 있는 기존 역량기반 프레임워크(competency-based framework)를 제공한다. 단계 진전(progression)은 1단계에서 확립된 AI 비의존 수준(AI-independent level)의 문서화된 역량과 2단계에서 개발된 보정 수준(calibration level)의 문서화된 역량을 모두 요구해야 한다(Fig. 2).
- 3단계의 목표는 AI를 감독하는 것이 아니다. 훈련생이 AI와 함께 일할 때 더하는 임상적 가치(clinical value)는 AI 산출물 점검(checking AI outputs)에 있지 않을 수 있다. 그것은 AI가 접근할 수 없는 맥락적 추론(contextual reasoning)에 기여하는 데 있다. 즉 환자가 보고한 병력(patient-reported history), 신체진찰 소견(physical examination findings), 그리고 개별 환자의 가치(individual patient values)가 여기에 해당한다. 따라서 3단계는 AI가 제공하는 것 이상으로 임상의가 가치를 기여하는 구체적 기술(specific skills)을 개발해야 한다. 여기에는
- 언제 AI를 무시/재정의할지(override),
- 언제 AI에 따를지(defer to it), 그리고
- 언제 협력이 독립적 판단(independent judgment)에 비해 가치를 더하거나 빼는지(adds versus subtracts value)를 인식하는 것이 포함된다.
- 3단계에는 프롬프트 구성(prompt construction) 훈련도 포함되어야 한다. LLM 산출물의 질은 그것을 생성하는 프롬프트(prompt)의 질에 상당히 좌우된다7. 모호하거나 유도적인 프롬프트(vague or leading prompts)는 덜 정확하고 잠재적으로 아첨적(sycophantic)인 응답을 만들어내며, 질문자의 선행 믿음(prior beliefs)을 반영할 뿐 독립적 임상평가(independent clinical evaluation)를 제공하지 못할 수 있다. 산출물을 수용하기 전에 AI에게 자신의 추론을 설명하도록 요구하는 것은 가르칠 수 있는 기술(teachable skill)이다. 이는 수동적 수용(passive acceptance)을 능동적 평가(active appraisal)로 전환하며, 안전한 임상 AI 사용(safe clinical AI use)에 직접 적용된다.
Fig. 2 | AI를 의학교육에 책임 있게 통합하기 위한 세 단계 프레임워크
(A three-phase framework for the responsible integration of AI into medical education)

- 단계 간 진전(progression)이 이전 수준의 문서화된 역량(documented competency)을 요구하는 순차적 프레임워크(sequential framework)를 제안한다. 핵심 은유(key metaphor)는 전제조건 논리(prerequisite logic)를 반영한다. 각 단계는 정의된 역량 기준(competency threshold)이 충족될 때에만 다음 단계를 열어 준다.
- 1단계는 구조화된 문제기반학습(structured problem-based learning), 관찰된 임상 만남(observed clinical encounters), 그리고 최종 답이 아니라 명시적 추론(explicit reasoning)을 요구하는 평가과제를 통해 AI 비의존 임상추론(AI-independent clinical reasoning)을 확립한다. 이 단계에서는 정답 제공 방식(answer-delivery mode)의 AI 보조가 허용되지 않는다.
- 2단계는 의도적 오류(deliberate errors)를 포함한 AI 생성 임상추론(AI-generated clinical reasoning)을 학생들이 접하고, 이를 탐지하고 설명하며 수정하는 능력으로 평가받는 적대적 교수법(adversarial pedagogy)을 통해 AI를 도입한다. AI가 있는 과제와 없는 과제(matched tasks completed with and without AI)는 보정된 의존(calibrated reliance)을 발달시킨다. DEFT-AI 감독 프레임워크(supervisory framework)는 교육자에게 우발적 AI 사용(incidental AI use)을 의도적 교수 순간(deliberate teaching moments)으로 전환할 수 있는 구조화 도구(structured tool)를 제공한다7.
- 3단계는 주로 전공의 훈련(residency training)에 적용되며, 효과적인 인간-AI 협력(human–AI collaboration)에 필요한 구체적 역량을 개발한다. 여기에는 EPA 통합 과업 평가(EPA-integrated task evaluation), AI가 접근할 수 없는 맥락적 임상추론(contextual clinical reasoning)의 기여, 프롬프트 구성(prompt construction), 그리고 적응적 전략 선택(adaptive strategy selection)이 포함된다. 각 단계는 확립된 개입(established intervention)이 아니라 전향적 평가(prospective evaluation)가 필요한 가설(hypothesis)이다.
프레임워크 실행의 도전과제 (Framework implementation challenges)
이 프레임워크는 모든 실행 프로그램이 다루어야 할 네 가지 실제적 장벽(practical barriers)에 직면한다.
- 장벽 1: 분절화(Fragmentation).
- 의과대학(medical schools), 면허시험기관(licensing boards), 인증기구(accreditation bodies), 전문과목 자격인증 조직(specialty certification organizations)은 각각 AI 비의존 역량(AI-independent competency)을 공식 기준(formal standard)으로 인정해야 할 것이다. 현재 그러한 조정(coordination)은 존재하지 않는다. 이를 확립하려면 서로 다른 거버넌스 구조(governance structures), 일정(timelines), 유인체계(incentive frameworks)를 가진 기관들 간의 다자간 합의(multilateral agreement)가 필요하다.
- 장벽 2: 교수 역량(Faculty capacity).
- 의과대학 교수진 중 약 9%만이 AI 전문성(AI expertise)을 보고한다15. 적대적 교수법(adversarial pedagogy)과 보정 훈련(calibration training)은 임상적으로 그럴듯한 AI 오류 사례(clinically plausible AI error cases)를 설계하고, 추론 중심 디브리핑(reasoning-focused debriefs)을 촉진하며, 진료 현장(point of care)에서 DEFT-AI와 같은 감독 프레임워크(supervisory frameworks)를 적용할 수 있는 교육자를 필요로 한다. 이는 전담 개발 프로그램(dedicated development programs)을 필요로 하는 기술이며, 그 자체로 자원 집약적(resource intensive)이다.
- 장벽 3: 자원 불평등(Resource inequity).
- 네 가지 AI 접근 수준(AI-access levels)에 걸친 역량 프로파일링(competency profiling)은 기술 인프라(technical infrastructure)를 필요로 하며, 이는 IT 지원이 제한된 기관에서 불균형적으로 구현하기 어려울 수 있다. 형평성 지원(equity provisions) 없이 의무 요건(mandatory requirements)이 도입되면, 역량 보호장치의 혜택을 가장 크게 받아야 할 자원 제한 기관(resource-limited institutions)과 학생 집단(student populations)을 오히려 불리하게 만들 위험이 있다.
- 장벽 4: 역량 탐지(Competency detection).
- AI 보조 훈련(AI-assisted training)은 AI가 활성화된 조건(AI-enabled conditions)에서 초기 역량 기준(initial competency thresholds)을 충족하는 졸업생을 만들어낼 수 있지만, AI가 철회되었을 때 더 가파른 수행 저하(steeper performance decline)를 보일 수 있다. 단일 시점(single time point)에 실시되는 표준 평가(standard assessments)는 이러한 취약성(fragility)을 탐지할 수 없다. 이를 식별하려면 훈련 중과 훈련 후에 AI 가용성(AI availability)이 다양한 조건에서 종단 추적(longitudinal tracking)이 필요하다.
이 장벽들은 상당하지만 극복 불가능한 것은 아니며, 이 프레임워크에만 고유한 것도 아니다. 역량기반 의학교육(competency-based medical education, CBME)은 수십 년의 개혁 과정에서 유사한 실행 도전과제(implementation challenges)에 직면해 왔다44. 적절한 대응은 문제가 해결될 때까지 행동을 연기하는 것이 아니다. 적절한 대응은 내재된 평가(embedded evaluation)를 포함한 연구 프로그램(research program)으로 프레임워크를 파일럿 운영하여, 근거가 축적됨에 따라 반복적으로 개선(iterative refinement)하는 것이다.
연구 의제 (Research agenda)
이 프레임워크는 어떤 구성요소도 표준 실천(standard practice)으로 권고되기 전에 경험적으로 검증되어야 하는 가설들에 기반을 둔다. 여기서 네 가지 연구 우선순위(research priorities)가 도출되며, 대략 번역·확산의 순서(translational in sequence)를 따른다(Fig. 3).
- 의제 1: 기초 연구(Agenda 1: Foundational research).
- 기초 질문은 발달 시점(developmental timing)과 영역 특이성(domain specificity)에 관한 것이다. 지속 가능한 AI 비의존 역량(durable unaided competency)을 위해 필요한 AI 없는 문제기반학습(AI-free problem-based learning)의 최소 기간은 얼마인가? 임상추론의 어떤 구성요소가 AI 대체(AI substitution)에 가장 취약한가? 전통적으로 가르쳐 온 어떤 기술이 합리적 위임(rational delegation)의 후보가 아니라 실제로 독립적 숙달(independent mastery)을 필요로 하는가? 이러한 질문은 여러 시점에서 AI 비의존 역량 측정(AI-independent competency measures)을 사용하여 AI 네이티브 학습자(AI-native learners)와 전통적으로 훈련받은 학습자(traditionally trained learners)를 비교하는 전향적 코호트 연구(prospective cohort studies)를 필요로 한다.
- Never-skilling 가설의 엄격한 검증은 구조화된 AI 없는 교육과정(structured AI-free curriculum)과 정의된 수준의 AI 보조 학습(AI-assisted learning)을 비교하는 종단 무작위 연구(longitudinal randomized study)를 필요로 하며, 각 군(arm)의 교육과정은 명확하게 지정되어야 한다. 학생들은 문제기반학습과 임상추론 과제에서 서로 다른 정도의 AI 지원을 받는 구조화된 교육과정에 배정될 수 있다. 결과지표(outcomes)는 AI 비의존 추론 수행(AI-independent reasoning performance)과 AI가 활성화된 환경(AI-enabled environments)에서의 수행을 모두 포함해야 하며, 졸업 시점과 훈련 후 추적기간 중 평가되어야 한다. 교육적·윤리적 함의(educational and ethical implications)를 고려할 때, 이러한 연구는 사전에 설정된 한계값(prespecified margins), 역량 유지(competency retention)에 대한 종단 평가, 그리고 중간 모니터링 안전장치(interim monitoring safeguards)를 갖춘 동등성 또는 비열등성 시험(equivalence or non-inferiority trial)으로 설계되는 것이 가장 적절할 것이다
- 의제 2: 교육과정 개발(Agenda 2: Curriculum development).
- 교육과정 개발 의제는 기초 연구 결과를 검증된 도구(validated tools)로 번역한다. 여기에는 Table 3의 네 가지 역량 수준을 모두 포괄하는 평가(assessments), 문서화된 AI 실패 양식(documented AI failure modes)을 반영하는 임상적으로 대표성 있는 적대적 사례(clinically representative adversarial cases)의 라이브러리, 그리고 기존 근거기반의학(evidence-based medicine) 과정에 AI 훈련을 통합하는 교육과정 프레임워크(curriculum frameworks)가 포함된다. 각 도구는 배치 전에 임상 전문가의 검증(validation by clinical experts)을 필요로 한다.
- 의제 3: 실행 및 평가(Agenda 3: Implement and evaluate).
- 실행 시험(implementation trials)은 훈련 종료 시점의 AI 비의존 수행(AI-independent performance)과 6~12개월 시점의 역량 지속성(competency durability)을 주요 평가변수(primary endpoints)로 하여, 단계적 통합(phased integration)과 비구조적 AI 통합(unstructured AI integration)을 비교해야 한다. 이차 평가변수(secondary endpoints)는 보정 지표(calibration metrics), 새로운 사례로의 전이(transfer to novel cases), 그리고 AI 가용성이 다양한 환경에서의 직무수행 지표(workplace performance indicators)를 포함해야 한다.
- 의제 4: 번역과 정책(Agenda 4: Translation and policy).
- 정책 번역 의제(policy translation agenda)는 근거를 실행 가능한 기준(actionable standards)으로 전환한다. 연구 결과는 면허시험(licensing examinations)을 위한 최소 역량 기준(minimum competency thresholds)을 알려야 하며, 의학 훈련에서 AI 리터러시(AI literacy)를 규율하는 인증 요건(accreditation requirements)의 근거 기반을 제공해야 한다. 실행과학 방법(implementation science methods)은 기관 맥락(institutional contexts) 전반에서 도입 장벽(adoption barriers)을 식별하고, AI 능력과 교육 근거가 함께 진화함에 따라 반복적 개선(iterative improvement)을 가능하게 하기 위해 필요하다.
Table 3 | 네 수준 역량 프레임워크 (Four-level competency framework)a
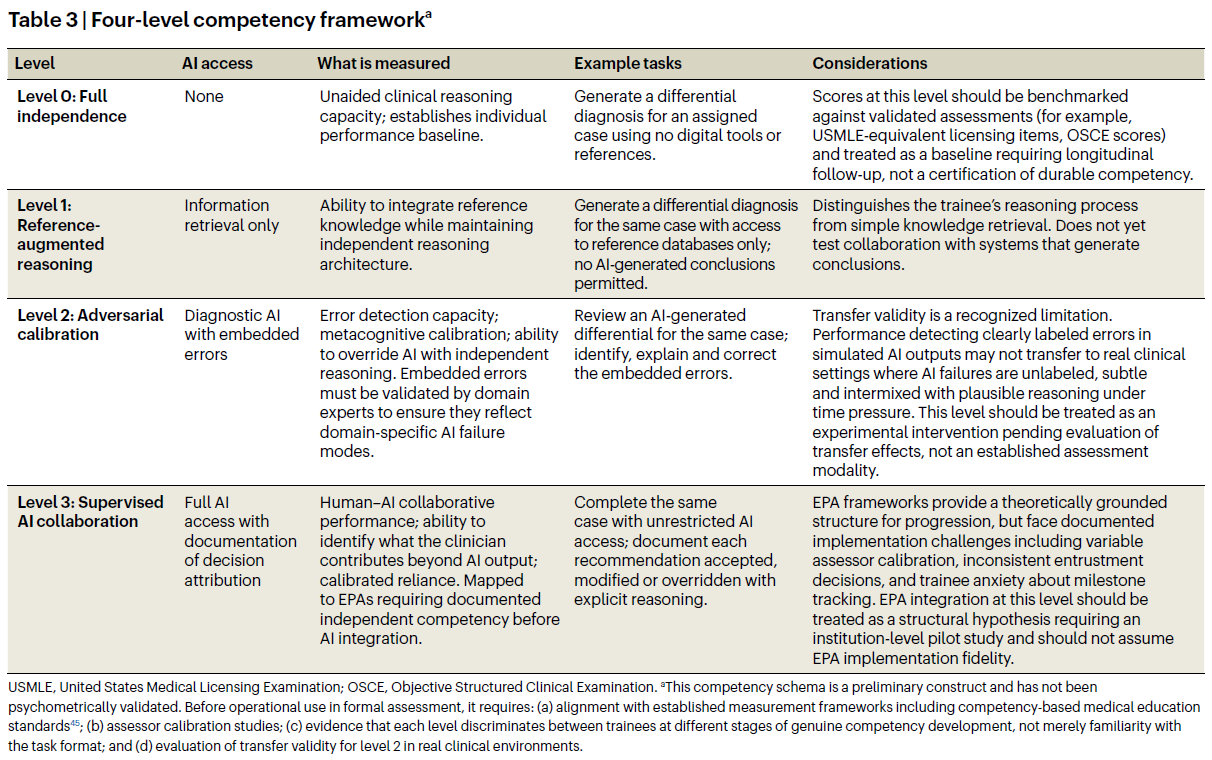
| 수준(Level) | AI 접근(AI access) | 측정되는 것(What is measured) | 예시 과제(Example tasks) | 고려사항(Considerations) |
| Level 0: 완전한 독립성(Full independence) | 없음(None) | 도움 없는 임상추론 역량(unaided clinical reasoning capacity). 개인 수행 기준선(individual performance baseline)을 확립한다. | 디지털 도구나 참고자료 없이 배정된 사례에 대한 감별진단(differential diagnosis)을 생성한다. | 이 수준의 점수는 검증된 평가(validated assessments), 예컨대 USMLE 동등 면허 문항(USMLE-equivalent licensing items) 또는 OSCE 점수(OSCE scores)에 맞춰 벤치마킹되어야 하며, 지속 가능한 역량의 인증(certification)이 아니라 종단 추적(longitudinal follow-up)이 필요한 기준선(baseline)으로 다루어져야 한다. |
| Level 1: 참고자료 증강 추론(Reference-augmented reasoning) | 정보 검색만 허용(Information retrieval only) | 독립적 추론 구조(independent reasoning architecture)를 유지하면서 참고 지식(reference knowledge)을 통합하는 능력. | 동일 사례에 대해 참고 데이터베이스(reference databases)에만 접근하여 감별진단을 생성한다. AI 생성 결론(AI-generated conclusions)은 허용되지 않는다. | 훈련생의 추론 과정(reasoning process)을 단순한 지식 검색(simple knowledge retrieval)과 구분한다. 결론을 생성하는 시스템과의 협업(collaboration with systems that generate conclusions)은 아직 평가하지 않는다. |
| Level 2: 적대적 보정(Adversarial calibration) | 삽입된 오류(embedded errors)가 있는 진단 AI(Diagnostic AI) | 오류 탐지 능력(error detection capacity), 메타인지적 보정(metacognitive calibration), 독립적 추론으로 AI를 무시/재정의하는 능력(ability to override AI with independent reasoning). 삽입된 오류는 영역 특이적 AI 실패 양식(domain-specific AI failure modes)을 반영하도록 해당 분야 전문가(domain experts)가 검증해야 한다. | 동일 사례에 대한 AI 생성 감별진단(AI-generated differential)을 검토하고, 삽입된 오류를 식별하고 설명하며 수정한다. | 전이 타당도(transfer validity)는 인정되는 한계이다. 모의 AI 산출물에서 명확히 표시된 오류(clearly labeled errors)를 탐지하는 수행이 실제 임상 환경으로 전이되지 않을 수 있다. 실제에서는 AI 실패가 표시되어 있지 않고, 미묘하며, 시간 압박하에서 그럴듯한 추론과 뒤섞여 있다. 이 수준은 전이 효과(transfer effects) 평가가 완료되기 전까지 확립된 평가 방식(established assessment modality)이 아니라 실험적 개입(experimental intervention)으로 다루어야 한다. |
| Level 3: 감독하 AI 협력(Supervised AI collaboration) | 의사결정 귀속(decision attribution)의 문서화를 동반한 완전한 AI 접근(Full AI access with documentation of decision attribution) | 인간-AI 협력 수행(human–AI collaborative performance), 임상의가 AI 산출물 이상으로 무엇을 기여하는지 식별하는 능력, 보정된 의존(calibrated reliance). AI 통합 전 문서화된 독립 역량(documented independent competency)을 요구하는 EPA에 매핑된다. | 제한 없는 AI 접근(unrestricted AI access)으로 동일 사례를 완료하고, 수용·수정·무시/재정의한 각 권고(recommendation accepted, modified or overridden)를 명시적 추론(explicit reasoning)과 함께 문서화한다. | EPA 프레임워크는 단계 진전(progression)을 위한 이론적으로 근거 있는 구조를 제공하지만, 평가자 보정(assessor calibration)의 변이, 일관되지 않은 위임 결정(entrustment decisions), 이정표 추적(milestone tracking)에 대한 훈련생 불안 등 문서화된 실행 문제(implementation challenges)에 직면한다. 이 수준에서의 EPA 통합은 기관 수준 파일럿 연구(institution-level pilot study)를 요구하는 구조적 가설(structural hypothesis)로 다루어져야 하며, EPA 실행 충실도(implementation fidelity)를 가정해서는 안 된다. |
- USMLE, United States Medical Licensing Examination; OSCE, Objective Structured Clinical Examination.
- a 이 역량 도식(competency schema)은 예비 구성개념(preliminary construct)이며 심리측정적으로 검증(psychometrically validated)되지 않았다. 공식 평가(formal assessment)에 운영적으로 사용되기 전에 다음이 필요하다. (a) 역량기반 의학교육 표준(competency-based medical education standards)을 포함한 확립된 측정 프레임워크(established measurement frameworks)와의 정렬45; (b) 평가자 보정 연구(assessor calibration studies); (c) 각 수준이 과제 형식(task format)에 대한 친숙성이 아니라 진정한 역량 발달(genuine competency development)의 서로 다른 단계에 있는 훈련생을 구분한다는 근거; (d) 실제 임상환경(real clinical environments)에서 Level 2의 전이 타당도(transfer validity) 평가.
한계 (Limitations)
이 Perspective에는 중요한 한계가 있다.
- 훈련 중 AI 노출(AI exposure during training)이 의학 훈련생의 역량 실패(competency failure)로 이어진다는 직접적 인과 근거(direct causal evidence)는 존재하지 않는다. 인용된 경험적 근거는 간접적이며 주로 비임상(nonclinical) 맥락에서 나온 것이다. Never-skilling은 확립된 현상(established phenomenon)이 아니라 위험 모델(risk model)로 제시된다.
- AI로 유발된 역량 결손(AI-induced competency deficits)의 유병률(prevalence), 심각도(severity), 가역성(reversibility)은 알려져 있지 않다. 적절하게 발판화된 AI 통합(properly scaffolded AI integration)은 기초 기술 발달(foundational skill development)을 저해하기보다 향상시킬 수 있다. 각각의 결과가 어떤 조건에서 발생하는지는 경험적으로 정의되어야 한다.
- 앞서 설명한 세 단계 프레임워크(three-phase framework)는 검증되지 않았다. 그 효과성(effectiveness), 실행가능성(feasibility), 의도치 않은 결과(unintended consequences)는 평가되지 않았다. 널리 도입되기 전에 엄격한 결과 측정(rigorous outcome measurement)을 포함한 파일럿 실행(pilot implementations)이 선행되어야 한다.
- 권고사항은 확립된 최선의 실천(best practices)이 아니라 조사를 위한 가설(hypotheses for investigation)로 이해되어야 한다. 마지막으로, 이 분석은 집필 당시의 AI와 의학교육의 현재 상태(current state)를 반영한다. 둘 모두 빠르게 진화하고 있다. 구체적 권고사항은 근거가 축적됨에 따라 수정이 필요할 수 있다.
결론 (Conclusion)
임상 훈련생에서 never-skilling의 위험은 아직 확인될 수 없지만, 이론적으로 근거가 있으며 인접 분야(adjacent fields)에서의 초기 경험적 신호와 일치한다. 중요한 것은, 이것이 코호트 규모(cohort scale)로 확립되고 나면 구조적으로 탐지하고 되돌리기 어렵다는 점이다. 따라서 never-skilling의 위험은 해로움에 대한 근거가 결정적이기 전에 주목할 필요가 있다.
이 Perspective는 의학교육에서 AI를 반대하지 않는다. 구조화된 피드백(structured feedback), 발판화된 난이도(scaffolded difficulty), 명시적 추론 요구(explicit reasoning demands)를 갖춘 학습 방식(learning mode)의 AI 도구는 기초 기술 발달(foundational skill development)을 가속화할 수 있다. 우려는 순서(sequencing)에 관한 것이다. 임상추론 스키마(clinical reasoning schemas)가 형성되는 발달 기간(developmental period)에 AI가 정답 제공 방식(answer-delivery mode)으로 도입될 때, AI는 스키마 형성에 필요한 인지적 노력(cognitive effort)을 대체할 수 있다. 목표는 AI를 제한하는 것이 아니다. 목표는 훈련생이 먼저 비판적 AI 사용을 가능하게 하는 독립적 역량(independent competency)을 발달시키도록 보장하는 것이다.
AI 사용 선언 (Declaration of AI usage)
원고 준비 과정에서 저자들은 생성형 AI 도구(ChatGPT-4o, Gemini 3, Claude 4.5)를 오직 언어 다듬기(language refinement)를 위해서만 사용했다. 이러한 도구는 원자료(original data)를 생성하거나 분석하거나, 과학적 결론(scientific conclusions)을 도출하는 데 사용되지 않았다. 모든 AI 보조 내용(AI-assisted content)은 저자들이 주의 깊게 검토하고 검증했으며, 저자들은 원고에 대한 전적인 책임(full responsibility)을 진다.
Fig. 3 | 형성기 훈련 중 AI 사용이 독립적 임상역량을 손상시킨다는 가설을 검증하기 위한 번역 연구 프레임워크 (A translational research framework for testing the hypothesis that AI use during formative training impairs independent clinical competency)
이 그림은 네 가지 순차적 연구 의제(sequential research agendas)를 가로지르는 하나의 조사 흐름(single investigative thread)을 보여주며, 각 의제는 선행 단계에서 생성된 근거 위에 구축된다. 의제 1(기초 연구, foundational research)은 핵심 경험적 질문(primary empirical question)을 제기한다. AI 보조 학습(AI-assisted learning)은 기초 기술(foundational skills)을 어떻게 손상시키는가? 연구설계는 먼저 무엇이 기초적·필수 기술(foundational/must-have skills)로 간주되는지에 대한 전문가 합의(expert consensus)를 얻고, 이어 이러한 기술에서 AI 보조 학생(AI-assisted students)과 AI 없는 학생(AI-free students)을 비교하는 종단 무작위대조시험(longitudinal randomized controlled trial, RCT)을 수행하는 방식이어야 한다. 만약 답이 ’그렇다’라면, 의제 2(교육과정 개발, curriculum development)는 기초 가설(foundational hypothesis)이 지지될 때 탐지 및 예방 도구(detection and prevention tools)를 어떻게 구축하고 검증할 수 있는지 묻는다. 의제 3(실행과 평가, implementation and evaluation)은 단계적 프레임워크(phased framework)를 실행했을 때 필수 역량(must-have competencies)을 보호하는지 검증한다. 이는 단계적 실행 집단(phased-implementation group)과 비구조적 집단(unstructured group)을 비교하는 통제 시험(controlled trials)을 통해 이루어지며, 역량 지속성(competency durability)이 주요 평가변수(primary endpoint)가 된다. 의제 4(번역과 정책, translation and policy)는 시험 근거(trial evidence)를 네 가지 영역의 실행 가능한 기준(actionable standards)으로 전환한다.










'논문 읽기 (with AI)' 카테고리의 다른 글
| 평가 과학과 실천에 대한 다양한 해석에 주의를 기울이기(Teach Learn Med. 2024) (0) | 2026.06.02 |
|---|---|
| 관점주의와 보건의료전문직 평가(Acad Med. 2024) (0) | 2026.06.02 |
| 사고는 글쓰기만이 아니다 (Nature reviews bioengineering, 2026) (0) | 2026.05.17 |
| 배움의 과학: 7가지 학습전략 (J Contin Educ Health Prof.) (0) | 2026.05.12 |
| 우리가 긋는 선: 보건의료전문직 교육의 기준설정에서 변화하는 인식론적 체제 (Adv Health Sci Educ Theory Pract. 2026) (0) | 2026.05.12 |