
INTRODUCTION
신뢰도(Reliability)란 평가(assessment)에서 나온 점수나 결정(decisions)의 일관성(consistency)을 의미한다 (Lord & Novick, 1968). 우리는 흔히 신뢰도를 일상적인 의미에서 이해한다. 즉, 일상 활동에서의 행동이 일관되거나 의존할 수 있는 것(consistency or dependability)이라는 뜻이다. 예를 들어, 친구나 자동차가 믿을 만하다고 할 때, 우리는 그들을 신뢰할 수 있기 때문에 그렇게 말한다. 평가 신뢰도(assessment reliability)도 이와 유사한 방식으로 개념화된다.
한 학습자가 어떤 평가에서 합격(pass)을 했다면, 재시험(retest)에서도 동일한 "합격(pass)" 결정이 재현되기를 기대할 수 있다. 즉, 점수의 신뢰도가 높다면 평가 결과에 자신감(confidence)과 신뢰성(trustworthiness)을 부여한다. 그러나 만약 학습자가 재시험에서 불합격(fail)을 한다면, 그 평가는 신뢰롭지 않을 수 있다.
점수의 재현 가능성(reproducibility) 혹은 의존 가능성(dependability)은 평가 신뢰도의 핵심적 특성이다. 이러한 개념화에 따르면, 신뢰도는 다양한 방식으로 포착될 수 있다. 즉, 시점 간(occasions), 문항 간(items), 평가자 간(raters), 혹은 스테이션 간(stations)의 일관성을 의미할 수 있다. 따라서 신뢰도는 맥락에 따라 서로 다르게 측정될 수 있으며, 이는 교육자와 연구자에게 다양한 신뢰도 통계치(reliability statistics)를 제공한다.
이 장에서는 보건의료전문교육(Health Professions Education, HPE)에서의 신뢰도 이론과 실제적 적용을 설명한다. 우리는 신뢰도 통계 간의 차이를 논의한다. 각 신뢰도 지수(reliability index)는 (1) 기초 개념(foundational concepts), (2) 예시(illustrative examples), (3) HPE에 대한 함의(implications)와 함께 설명된다. 우리는 일반적으로 사용되는 신뢰도 추정 접근법과 이를 뒷받침하는 심리측정학적 추론(psychometric inferences)에 초점을 맞춘다.
우리는 고전검사이론(Classical Test Theory, CTT)으로 시작한다. 이는 측정과 오차를 뒷받침하는 이론적 기반과 가정을 제공하며, 신뢰도 추정의 기초가 된다. CTT를 활용해 흔히 사용되는 시험 기반 신뢰도 지수(test-based reliability indices)를 설명한다:
- 재검사 신뢰도(test-retest reliability)
- 반분 신뢰도(split-half reliability)
- 내적 합치도 신뢰도(internal-consistency reliability, Cronbach’s alpha)
또한, 평가자 간 신뢰도(inter-rater reliability) 통계는 다음과 같이 제시된다:
- 정확 합치도(exact agreement)
- 카파(kappa)
- 급내 상관계수(intraclass correlations, ICCs)
우리는 이러한 신뢰도 지수 간의 유사점과 차이점을 논의하며, 언제 어떤 통계치를 사용해야 하는지, 그리고 그것이 평가 점수의 타당도(validity)에 어떤 정보를 주는지를 설명한다. 더 나아가, 여러 평가의 신뢰도 지수를 결합한 합성 점수 신뢰도(composite score reliability)도 제시한다.
신뢰도(Reliability)는 교육 측정(educational measurement)과 사회과학 연구(social science research)에서 중심적인 역할을 한다. 신뢰로운 데이터(reliable data)는 효과적인 평가 실천의 토대이며, 타당도(validity)의 필수적 요소를 구성한다. 신뢰도와 타당도는 종종 구분된, 별개의 데이터 품질 지표로 다뤄지지만, 실제로는 불가분의 관계에 있다. 이 관계를 가장 간명하게 설명하는 표현은 “신뢰도는 타당도의 필요조건(necessary condition)이지만 충분조건(insufficient condition)은 아니다”라는 관찰이다 (Feldt & Brennan, 1989).
즉, 평가 점수가 일관적(consistent, reliable)일 수는 있으나, 정확(valid)하지 않을 수 있다. 예를 들어, 평가자들이 높은 합치도를 보이지만 지나치게 관대하여 실제 수행(performance)이 부족한 학습자에게도 모두 높은 합격 점수를 준다면, 그 점수는 신뢰도는 있을지언정 타당도는 결여된다. 따라서 점수가 신뢰롭지 않다면, 그것을 해석하는 데 필요한 타당성도 결여된다.
이 장에서는 독자가 신뢰도(reliability)에 관한 정보를 이해하고, 평가하며, 실제로 적용할 수 있는 의미 있는 방법을 제공한다.
THEORETICAL FRAMEWORK FOR RELIABILITY
신뢰도(Reliability)는 평가 점수(test scores)와 평가 데이터(assessment data)가 재현(replicated)되거나 재생산(reproduced)될 수 있는 정도를 의미한다. 모든 교육 측정(educational measurements)은 어느 정도의 측정 오차(measurement error)를 포함한다. 특히 보건의료전문교육(Health Professions Education, HPE)과 더 넓게는 사회과학(social sciences)에서 사용하는 평가 유형들은 측정 오차에 취약하다.
An Analogy (비유)
오차(error)의 개념을 설명하기 위해 다음 상황을 생각해 보자. 당신이 친구와 인터넷을 통해 화상 회의를 하고 있다.
전달되는 음성(sound)의 품질에는 여러 요인이 영향을 미친다—당신의 컴퓨터 속도, 인터넷 속도와 대역폭의 변동(fluctuation in Internet speed and bandwidth), 그리고 사무실의 배경 소음(background noise) 등이 그 요인이다. 이 모든 것이 친구와 나누는 대화의 질에 기여한다.
이 회의 중에 들리는 소리들은 두 가지로 분류될 수 있다:
- 산만하게 만드는 요소(distractors) (무작위 배경 소음이나 불안정한 인터넷 연결)와
- 친구의 말(friend’s words) (의미 있는 소리, 정보).
당신이 친구의 발언을 듣고 해석할 수 있는 정도는 0에서 1.0까지의 범위로 나타낼 수 있다. 0은 인터넷 연결이 너무 약해 의미 있는 대화가 전혀 불가능한 경우이고, 1.0은 전달된 모든 단어를 명확하게 이해한 경우이다. 이 값이 1.0에 가까울수록, 당신이 그 대화를 신뢰할 수 있고(reliable) 믿을 만하게(trustworthy) 재현할 수 있다.
평가 데이터(assessment data)도 이와 유사하다. 데이터에는 두 가지 변동 요인이 존재한다:
- 무작위 오차(random error, noise)와 체계적 정보(systematic information).
- 평가 데이터에 포함된 무작위 오차가 적을수록, 신뢰도는 높아진다.
CLASSICAL TEST THEORY (CTT)
신뢰도(Reliability)는 고전검사이론(Classical Test Theory, CTT)이라는 기본 가정에 기반한다 (Lord & Novick, 1968). 이 간단한 공식(formula)은 관찰된 점수(observed score, X)가 잠재적인 참점수(true score, T)와 측정 오차(measurement error, e)의 함수라는 가정을 포함한다. 즉, 측정 오차(noise)는 모든 평가의 불가피한 측면이라는 것이다.
CTT에서 신뢰도는 다음과 같이 정의된다: Reliability = 참분산(True Variance) / 총분산(Total Variance)
이는 Equation (3.2)로 표현된다. 즉, 데이터에서 유용한 정보가 차지하는 비율이 얼마나 되는가?라는 질문을 반영한다.
(3.1)

(3.2)

Illustrative Example (예시)
다음과 같은 가상의 예를 생각해 보자. 당신이 학생들에게 퀴즈를 시행했을 때 기술 통계(descriptive statistics)는 다음과 같았다:
- 평균(Mean) = 65
- 표준편차(Standard Deviation, SD) = 5
여기서 표준편차는 Equation (3.2)의 σ(X)에 해당한다. 총분산(total variance)을 구하기 위해 이 값을 제곱하면, σ²(X) = 25가 된다. 즉, 평균 = 65, 분산 = 25가 된다 (표준편차 5를 제곱하여 산출). CTT에 따르면, 참분산(True Variance)은 총분산 25의 일부다. 가령, 어떤 통계적 접근을 통해 오차분산(Error Variance)을 10이라고 추정했다고 가정하자. 그러면 Equation (3.3)에 따라 참분산은 15가 된다 (= 총분산 25 – 오차분산 10). 따라서 신뢰도는 다음과 같이 계산된다:
Reliability = 참분산(15) / 총분산(25) = 0.60
즉, 참분산(True Variance)이나 오차분산(Error Variance) 중 하나를 구할 수 있다면, 우리는 신뢰도를 계산할 수 있다. 이것이 바로 CTT의 기본 원리이다. 보건의료 교육자들에게는 특정 상황에서 사용할 수 있는 다양한 신뢰도 추정 공식(reliability estimation formulas)이 있으며, 이들 모두 CTT의 원리를 기반으로 한다.
(3.3)

계산 예시


Implications (함의)
CTT에서는 체계적 변동(systematic variation)이 오직 참점수(true scores)의 차이에만 기인한다고 본다. 그러나 실제로는 평가자(rater)나 측정 편향(measurement bias)과 같은 다른 체계적 변동의 원인이 존재한다. 예를 들어, 어떤 저울이 항상 실제 무게보다 10파운드 더 무겁게 측정된다면, 이는 무작위 오차(random error)가 아니라 체계적 오차(systematic error)이다. 이러한 체계적 측정 오차는 신뢰도 분석(reliability analysis)에서는 탐지되지 않지만, 측정값의 해석 가능성을 저하시켜 결국 타당도(validity)에 부정적인 영향을 미친다.
제2장(Chapter 2)에서는 타당도(validity)와 체계적 오차(systematic error)에 대해 포괄적으로 논의한다. 제7~12장(Chapters 7–12)에서는 다양한 시험 형식(testing formats)에서 체계적 오차를 줄이는 방법에 대한 권고 사항을 제시한다.
이후 섹션에서는 두 가지 유형의 흔히 사용되는 신뢰도 통계(reliability statistics)를 검토한다:
- 시험 자체(test-based methods)에 기인한 오차분산(error variance)을 살펴보는 방법 (예: 문항 수나 문항 특성에 따른 영향)
- 평가자(rater)나 채점자(person scoring the exam)와 관련된 오차분산을 다루는 방법
RELIABILITY INDICES: TEST-BASED METHODS
시험 기반 방법(test-based methods)을 통한 세 가지 신뢰도 통계를 소개한다:
- 재검사 신뢰도(test-retest reliability)
- 반분 신뢰도(split-half reliability)
- 내적 합치도 신뢰도(internal-consistency reliability)
이 중, 재검사 신뢰도와 반분 신뢰도는 보건의료전문교육(HPE)에서 드물게 사용된다. 그러나 이 두 방법은 내적 합치도 신뢰도(internal-consistency reliability)의 기초를 제공하며, 이는 널리 사용된다. 각 신뢰도 통계는 (1) 개념적 정의(conceptual definition), (2) 예시(illustrative example), (3) 신뢰도 해석에 대한 함의(implications for reliability interpretation)와 함께 제시된다.
1. Test-Retest Reliability (재검사 신뢰도)
개념적 기반(Conceptual Basis for Test-Retest Reliability)
재검사 신뢰도(test-retest reliability)는 점수와 결정의 재현성(replication)을 고려할 때 가장 기본적인 개념이다. 즉, 동일한 시험을 여러 차례 실시했을 때, 다른 요인이 개입하지 않았다고 가정하면 동일한 점수를 얻을 수 있는가?라는 질문이다. 재검사 신뢰도는 두 시점(Time 1, Time 2)에서 동일한 시험을 시행할 때 발생하는 오차(error)를 평가한다.
개념적으로는 단순하다:
- Time 1에 시험을 시행한다.
- 동일한 시험을 Time 2에 시행한다.
- 두 점수 간의 상관관계(correlation, r)를 계산한다.
재검사 신뢰도가 CTT와 어떻게 연결될까? 앞서 설명했듯이, 신뢰도는 참점수 분산(true score variance)과 총분산(total variance)의 비율로 개념화된다 (Equation [3.2] 참조). 수학적으로, 상관관계(correlation)의 공식은 두 점수 간 공유되는 변동성(covariance)을 두 점수의 표준편차(product of standard deviations, SD)의 곱으로 나눈 값이다 (Equation [3.4] 참조). 이때 공유되는 변동성(shared variability)이 곧 참분산(true variance)으로 간주된다.

예시(Illustrative Example: Test-Retest Reliability)
Figure 3.2는 이 예시를 보여준다. 10명의 학습자의 점수를 Time 1과 Time 2에 걸쳐 제시하고, 이 두 시점의 점수 간 상관관계를 계산하면 신뢰도를 얻을 수 있다.

함의(Implications: Test-Retest Reliability)
역사적으로, 시점 간 일관성(consistency across occasions) 개념은 신뢰도를 측정하려는 최초의 시도였다. 그러나 HPE에서 재검사 신뢰도의 사용은 제한적이다. 왜냐하면 학습자의 수행(performance)은 검사 간 간격이 길든 짧든 시간에 따라 변하기 때문이다. 이를 성숙 효과(maturation effect)라고 한다.
추가적인 오차 요인으로는, 수행의 무작위 변동(random fluctuations), 통제되지 않은 시험 조건(uncontrolled testing conditions), 점수의 질을 왜곡할 수 있는 내부 요인(internal factors) 등이 있다 (반응 과정 타당도 증거(response process validity evidence), 제2장 참조). 또한 동일한 피험자에게 반복 시험을 시행해야 한다는 물리적·운영상의 어려움도 존재한다.
이 접근법이 정확한 추정을 제공하기 위해서는 피험자가 이전 시험에서의 정보를 기억하지 않는다는 비현실적 가정에 의존해야 한다. 따라서 재검사 신뢰도는 주로 이론적·개념적 관심에 머무른다. 그럼에도 불구하고, 재검사 신뢰도는 다른 신뢰도 추정 방법들을 이해하는 데 중요한 개념적 토대(conceptual foundation)를 제공한다.
이후 섹션에서는 단일 시험(single test administration)으로부터 신뢰도를 추정하는 방법, 즉 반분 신뢰도(split-half reliability)와 내적 합치도 신뢰도(internal-consistency reliability)를 제시한다.
2. Split-Half Reliability (반분 신뢰도)
개념적 기반(Conceptual Basis for Split-Half Reliability)
반분 신뢰도(split-half reliability)는 단일 시험(single test administration)으로 신뢰도를 추정하려는 동기에서 출발한다. 즉, 하나의 시험을 절반으로 나누어 평행(parallel)하거나 동등한(equivalent) 형태의 시험으로 간주할 수 있는가? 예를 들어, 10문항으로 구성된 시험이 있다면, 앞의 절반(문항 1–5)과 뒤의 절반(문항 6–10)을 각각 별도의 시험으로 보고, 두 점수 간 상관관계를 계산한다. 이는 재검사 신뢰도와 유사한 방식이다.
예시(Illustrative Example: Split-Half Reliability)
Figure 3.3은 이 예시를 보여준다. 값 “0”은 오답(incorrect), “1”은 정답(correct)을 의미한다. 첫 다섯 문항(A1–A5)에서 얻은 점수를 계산하고, 마지막 다섯 문항(B1–B5)의 점수와 상관관계를 구하면 반분 신뢰도(split-half reliability) = 0.48이 된다.

함의(Implications: Split-Half Reliability)
반분 신뢰도의 핵심 질문은 시험을 어떻게 의미 있는 절반으로 나눌 것인가?이다.
- 한 가지 방법은 Figure 3.3처럼 앞 절반 vs. 뒤 절반(first half vs. last half)으로 나누는 것이다.
- 또 다른 방법은 홀수 문항 vs. 짝수 문항(odd vs. even numbered items)으로 나누는 것이다.
- 혹은 내용 영역(domains of content)에 기반하여 문항 집단을 나누는 방법도 있다.
그러나 HPE에서는 평가 내용이 복잡하기 때문에, 의미 있는 절반을 구성하기가 쉽지 않다. 따라서 반분 신뢰도 역시 HPE에서 잘 사용되지 않는다. 이와 같은 어려움 때문에 심리측정학자(psychometricians)들은 동일한 질문과 씨름해왔다: “어떻게 단일 시험으로부터 신뢰도를 계산하면서도 의미 있는 추정치를 얻을 수 있을까?”
그 해답 중 하나는 시험을 가능한 모든 방식으로 절반으로 나누고, 각각의 신뢰도 추정치를 계산한 뒤, 그것들을 의미 있는 방식으로 집계(aggregate)하는 것이다. 이것이 바로 다음 방법인 내적 합치도 신뢰도(internal-consistency reliability)의 기초가 된다.
3. Internal-Consistency Reliability: Cronbach’s Alpha
내적 합치도 신뢰도(Internal-consistency reliability)는 단일 시험(single test)을 가능한 모든 방식으로 절반으로 나누었을 때의 평균 상관관계(average correlation)를 계산하는 아이디어에 기반한다. 가장 널리 사용되는 내적 합치도 신뢰도 통계치는 알파 계수(coefficient alpha), 흔히 Cronbach’s alpha라고 불린다. 다른 신뢰도 측정치와 마찬가지로, Cronbach’s alpha는 총 시험 점수 분산(total test score variance) 중 체계적 분산(systematic variance) 또는 참점수 분산(true score variance)이 차지하는 비율을 나타낸다.
시험의 각 문항(item)은 생화학 지식(biochemistry knowledge)과 같은 잠재 능력(underlying ability or construct)을 측정하려는 시도로 볼 수 있다. Cronbach’s alpha는 시험 문항들에 대한 응답이 피험자의 생화학 능력(examinee ability in biochemistry)에 얼마나 강하게 의존하는지를 반영한다. 문항들 간 공유된 분산(shared variance)이나 상관관계(correlations)가 클수록, Cronbach’s alpha 값은 더 높아진다. 이는 곧 공통된 잠재 구성 개념(underlying construct)을 중심으로 문항들이 더 긴밀히 정렬되어 있음을 의미한다 (Traub, 1997).
Cronbach’s alpha는 참분산(true variance) = 총분산(total variance) – 오차분산(error variance)이라는 아이디어에 기초한다. 여기서 오차분산(error variance)은 문항들 간 변동(item variability)에 기인한다. Equation (3.5)는 CTT와 Cronbach’s alpha 간의 관계를 보여준다.
또한 Equation (3.5)에는 시험 문항 수(number of items)를 통제하는 보정 인자(correction factor)가 포함되어 있다.

Illustrative Example: Internal-Consistency Reliability
Figure 3.4에 제시된 예시를 살펴보자. 12개 문항이 학습자들에게 시행되었다. 값 “0”은 오답(incorrect), “1”은 정답(correct)을 의미한다.

Cronbach’s alpha를 계산하기 위해서는 먼저 학생별 총점(total scores)의 분산을 구해야 한다. Figure 3.4의 “Total” 열에 제시된 값으로, 이는 5.64이다. 다음으로 각 문항별 분산(item variance)을 계산해야 한다. 예를 들어, 문항 1의 분산은 0.08이다. 모든 문항의 분산을 합산한 값은 2.35이다. 이 값들이 Cronbach’s alpha 계산에 필요한 요소들이다.
대부분의 통계 소프트웨어는 Cronbach’s alpha를 손쉽게 계산할 수 있도록 지원한다. 예를 들어, Cronbach’s alpha = 0.64라는 것은 총점에서 관찰된 변동(observed variation) 중 64%는 피험자의 능력 차이(true score variation)에 기인하고, 반대로 36%는 피험자 능력이 아니라 무작위 오차(random error)에 기인한다는 의미이다. 이 예시에서 무작위 오차는 주로 문항 변동(item variation)에서 비롯된다.
제4장(Generalizability Theory)에서는, 오차의 원인이 평가자(raters), 문항(items), 스테이션(stations) 등 여러 요인에 동시에 기인하는 상황—예를 들어 객관구조화진료시험(Objective Structured Clinical Examination, OSCE)과 같은 경우—을 다룬다.
Implications: Internal-Consistency Reliability
아주 짧은 시험(short tests or quizzes)에서는 신뢰도 계수(reliability coefficients)가 0.50 이하가 되는 것이 드물지 않다. 그러나 이러한 alpha 값이 충분한 신뢰도를 의미하는지는 시험이 사용되는 목적에 달려 있다.
Downing (2004)과 Nunnally (1978)는 교육 측정 전문가들의 일반적인 해석 지침을 다음과 같이 제시한다:
- 0.90 이상: 매우 높은 stakes의 시험 (예: 면허시험 licensure, 자격시험 certification exams)
- 0.80–0.89: 중간 정도 stakes의 시험 (예: 의과대학 학년말 총괄시험 end-of-year summative exams, 교과 종료 시험 end-of-course exams)
- 0.70–0.79: 낮은 stakes의 평가 (예: 수업 내 형성평가 formative assessments, 교수자가 제작·시행하는 시험)
많은 교과 내(in-course) 혹은 교실 기반(classroom-type) 평가들은 0.70 미만의 신뢰도 추정치를 가지지만, 그렇다고 해서 무의미하지는 않다. 예를 들어, 신뢰도 계수가 0.70 미만인 시험 점수도 전체 합성 점수(composite score)의 한 요소로 사용된다면 여전히 유용할 수 있다.
Equation (3.5)에서 보듯이, 문항 수(number of items)는 Cronbach’s alpha 산출에서 중요한 역할을 한다. 이는 신뢰도의 핵심 개념 중 하나이다:
- 일반적으로, 문항 수를 늘리면 신뢰도가 증가한다.
- 이와 유사하게, 평가자 수를 늘리거나(add raters)
- 여러 평가의 점수를 결합(composite scores)하면 총점의 신뢰도가 강화된다 (Park, Lineberry, Hyderi, Bordage, Xing, & Yudkowsky, 2016).
이러한 개념들은 본 장의 후반부에서 다시 논의된다.
RELIABILITY INDICES: RATERS
지금까지는 정답(1) 혹은 오답(0)으로 객관적으로 채점(objectively scored)할 수 있는 평가 도구에 초점을 맞추었다. 그러나 보건의료전문교육(HPE)의 많은 교육 평가들은 구조화된 관찰(structured observations)과 수행(performance)의 평정(rating)을 통해 이루어진다 (Chapter 9 참조). 이 절에서는 HPE에서 흔히 사용되는 평가자 간 신뢰도(inter-rater reliability) 통계를 다룬다:
- 정확 합치도(% exact agreement)
- 카파(kappa)
- 급내 상관계수(intraclass correlation, ICC)
(Park, Hyderi, Bordage, Xing, & Yudkowsky, 2016)
Conceptual Basis for Inter-Rater Reliability (개념적 기반)
HPE에서 대부분의 평가자 간 신뢰도 추정치는 합치도(agreement) 개념에 기반한다—즉, 한 평가자가 부여한 점수가 다른 평가자가 부여한 점수와 얼마나 일치하는가?
이와 관련하여 세 가지 주요한 통계치가 있다 (Park, Hyderi et al., 2016):
- Exact agreement: 평가자 간 일치 비율(proportion of agreement between raters)
- Kappa: 단순한 일치뿐 아니라 우연적 합치(chance agreement)를 보정한 일치 비율
- ICC (Intraclass Correlation): 우연적 합치를 보정하는 것에 더해, 평가자 간 점수 변동의 크기(magnitude of variability)까지 고려한 합치도
Exact agreement는 단순히 평가자 간 합치의 비율을 계산한다. 예: 10개 평정 중 7개에서 평가자들이 동일하게 채점했다면, 정확 합치도는 70%이다.
그러나 만약 평정 도구가 4점 척도(four-point rating scale)라면, 우연적 합치 확률(chance agreement)이 25% 존재한다. Kappa는 이러한 우연적 합치를 보정한다.
ICC는 한 단계 더 나아가 평가자 점수 간의 차이의 크기(degree of difference)까지 반영한다.
예: 평가자 1이 “3”을, 평가자 2가 “4”를 준 경우 차이는 1점이다. 반면 평가자 1이 “1”을, 평가자 2가 “4”를 준 경우 차이는 3점이다. ICC는 이러한 차이를 고려한다. 반면 Exact agreement와 Kappa는 주로 절대적 합치(absolute agreement)에 초점을 둔다.
Illustrative Example: Inter-Rater Reliability (예시)
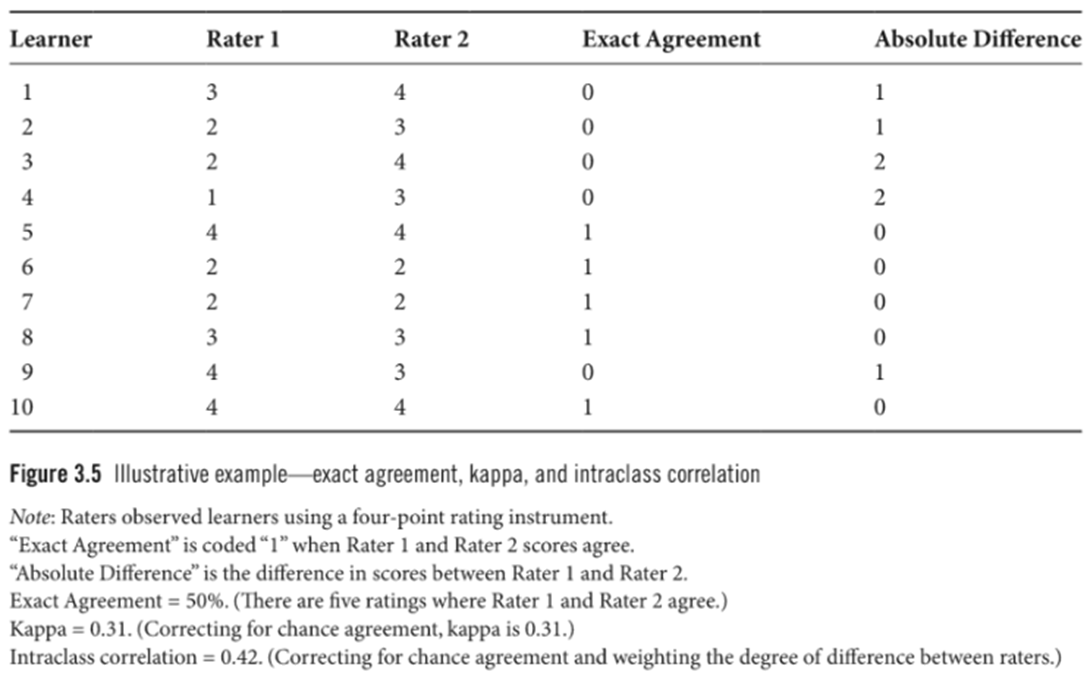
Figure 3.5는 두 명의 교수 평가자가 10명의 학습자를 4점 글로벌 평정 척도(four-point global rating scale)로 평가한 예시를 보여준다.
- Exact Agreement 열은 두 평가자가 합치하면 “1”, 불일치하면 “0”으로 표시된다.
- 10개 중 5개 관찰에서 합치했으므로, 정확 합치도(exact agreement) = 50%
- Kappa = 0.31 (우연적 합치를 보정한 값)
- ICC = 0.42
대부분의 통계 소프트웨어 패키지에서 이러한 통계치를 손쉽게 계산할 수 있다.
Implications: Inter-Rater Reliability (함의)
내적 합치도 신뢰도(internal-consistency reliability) 추정치와 마찬가지로, 평가자 간 신뢰도가 어느 범위에서 수용 가능한지를 규정하는 명확한 규칙은 없다. 특히, 정확 합치도(exact agreement)는 평정 범주(category) 수가 많아질수록 더 복잡해진다. 예: 9점 척도(milestones scale)에서 높은 합치를 얻는 것은 이분 척도(binary yes/no scale)에서 합치를 얻는 것보다 훨씬 어렵다. 따라서 평정 범주의 수가 서로 다른 경우 정확 합치도 수치를 단순 비교해서는 안 된다.
Kappa에 대해서, Landis와 Koch (1977)는 다음과 같은 해석 지침을 제시한다:
- < 0: 일치 없음(no agreement)
- 0–0.20: 미약한 일치(slight)
- 0.21–0.40: 보통 이하(fair)
- 0.41–0.60: 보통(moderate)
- 0.61–0.80: 상당한 일치(substantial)
- 0.81–1.00: 거의 완전한 일치(almost perfect agreement)
ICC에 대해서, Fleiss, Levin, and Paik (2004)는 다음과 같은 기준을 제시한다:
- < 0.40: 낮음(poor)
- 0.40–0.75: 보통~좋음(fair to good)
- > 0.75: 매우 우수(excellent)
연구자들은 이러한 지침이 다소 임의적(arbitrary)이라고 주장하기도 하지만, 실제 실무(practice)에서는 유용한 가이드라인을 제공한다. 특히 ICC는 평가자 오차(rater error)의 다양한 원인을 추정할 수 있는 가능성을 열었으며, 이는 이후 일반화가능도 이론(Generalizability Theory, Chapter 4)의 토대가 되었다.
마지막으로 중요한 점은 채점 정확도(scoring accuracy)와 채점 일관성(scoring consistency)을 구분하는 것이다. 평가자들이 일관적(consistency)일 수는 있으나, 반드시 정확(accuracy)하지는 않을 수 있다. 즉, 두 평가자가 모두 부정확하더라도 높은 합치를 보일 수 있으며, 반대로 두 평가자가 정확하더라도 서로 불일치할 수 있다. 따라서 이 차이를 구분하는 것이 중요하다.
STANDARD ERROR OF MEASUREMENT (SEM)
평가의 신뢰도(reliability)를 더 잘 이해하기 위해, 측정 표준 오차(Standard Error of Measurement, SEM)를 계산하고, 얻어진 점수에 대해 신뢰구간(confidence intervals)을 형성할 수 있다 (해석에 대한 더 자세한 논의는 Chapter 5의 시험 통계 부분 참조). SEM은 Equation (3.6)의 공식을 사용해 도출할 수 있다.

SEM은 평가 점수의 정밀성(precision)을 제공하는데, 이는 평가 점수 ± SEM (Assessment Score ± SEM) 형태의 신뢰구간을 구축함으로써 이루어진다.
Illustrative Example (예시)
두 명의 응시자가 서로 다른 점수를 받았다고 가정해보자:
- 학습자 A: 81%
- 학습자 B: 83%
전체 학급 평균은 80%였으며, 표준편차(Standard Deviation, SD)는 5%였다. Cronbach’s alpha에 기반한 시험의 신뢰도는 0.85였다. 이러한 결과에 기반해, 승진위원회(promotions committees)는 학습자 B를 학습자 A보다 더 우대하는 high-stakes 결정을 내려야 할까? 이 질문에 답하는 데 SEM이 도움이 될 수 있다.

우리는 학습자 A와 학습자 B의 신뢰구간을 다음과 같이 구축할 수 있다:
- Learner A: 81% ± 1.94 → (79.1, 82.9)
- Learner B: 83% ± 1.94 → (81.1, 84.9)
두 학습자의 점수 범위가 겹치므로(overlap), 측정 오차 범위 내에서는 그들의 점수가 다르지 않다고 해석할 수 있다.
Implications (함의)
SEM은 1.96을 곱하면 95% 신뢰구간, 1.65를 곱하면 90% 신뢰구간을 얻을 수 있다. 그러나 실제 교육 실무에서는 ±1 SEM을 사용하여 68% 신뢰구간을 설정하는 경우가 많다. 이는 교육 맥락에서 보다 실용적인 신뢰구간을 제공하기 때문이다. 더 큰 신뢰구간을 사용하면 점수 비교가 훨씬 더 어려워진다.
여기서 SEM (standard error of measurement)은 표준오차(standard error of the mean)와 혼동해서는 안 된다. 두 통계치는 서로 다른 개념이다. Standard error of the mean은 측정 오차가 없다고 가정할 때 신뢰구간을 설명하는 데 사용된다.
- 예를 들어, 주요 도시의 자동차 대수를 보고할 때는 단순히 자동차 수를 세는 것(counting cars)이므로 측정 오차가 존재하지 않는다. 따라서 이 경우는 standard error of the mean을 사용해야 한다.
- 반면, 평가(assessments)나 심리적 구성(psychological constructs)은 잠재적 개념(latent constructs)을 다루며, 본질적으로 측정 오차(measurement error)를 포함한다. 이것이 고전검사이론(CTT)의 핵심 가정이다.
|
HOW TO INCREASE RELIABILITY
교육자와 실무자들이 평가의 신뢰도(reliability)를 높일 수 있는 방법은 크게 세 가지다:
- 문항(test items), 평가자(raters), 스테이션(stations) 또는 다른 평가 요소를 추가한다.
- 문항분석(item analysis)을 수행하고 잘 작동하지 않는 문항을 제거·수정·교체한다 (Chapter 5 참조). 이는 전체 문항의 질을 향상시킨다.
- 여러 평가 점수를 결합해 합성 점수(composite scores)를 만든다.
이 절에서는 Spearman-Brown 공식(Spearman-Brown formula)을 적용해 문항 수를 추가하는 방법에 초점을 맞춘다. 또한 점수를 결합하여 합성 점수를 형성하는 방법도 논의한다 (Park, Lineberry et al., 2016; Kane & Case, 2004).
PROJECTIONS IN RELIABILITY: SPEARMAN-BROWN FORMULA
어떤 평가의 신뢰도가 낮을 경우, 한 가지 방법은 시험 문항 수를 늘리는 것이다. Spearman-Brown 공식을 사용하면 시험을 길게 했을 때 신뢰도가 어떻게 변할지를 추정할 수 있다 (Chapter 5 참조).
- Equation (3.7)은 Spearman-Brown 공식을 보여준다.

- Equation (3.8)은 그 공식을 변형한 형태이다.

값의 의미는 다음과 같다:
- N: 시험 길이를 늘리거나 줄이는 정도 (factor of increase/decrease)
- r: 원래 시험의 신뢰도 (reliability of original test)
- r*: Spearman-Brown으로 예측된 신뢰도 (predicted reliability)
Illustrative Example (예시)
문항 수가 30개이고 재검사 신뢰도(test-retest reliability)가 0.65인 시험이 있다고 하자. 이를 90문항으로 (즉, 세 배로) 늘린다.
- 여기서 N = 3, r = 0.65, 그리고 r*는 예측된 신뢰도이다.
- Spearman-Brown 공식을 적용하면, 시험 문항을 30개에서 90개로 늘릴 경우 신뢰도는 0.85가 된다.
- 반대로, 현재 신뢰도가 0.65일 때 신뢰도를 0.85로 높이고자 한다면, 문항 수를 몇 배 늘려야 하는지를 알고자 할 수 있다. 이 경우 Equation (3.8)을 사용하면, 필요한 증가 배수가 3임을 알 수 있다.

Implications (함의)
Spearman-Brown 공식은 예상되는 신뢰도를 추정(projections of reliability estimates)하는 데 유용한 도구이다. 그러나 이 공식은 시험의 특성이 일정하게 유지된다(test characteristics remain consistent)는 가정을 전제로 한다. 예를 들어, 시험 문항 수를 세 배로 늘리면 신뢰도가 높아진다고 해서, 단순히 질 낮은 문항(poor-quality items)을 추가하는 것을 의미하지는 않는다. 문항을 추가하거나 수정할 때는 반드시 타당도(validity)를 고려해야 하며 (Chapter 2 참조), 이는 가장 중요한 원칙이다.
COMPOSITE SCORES AND COMPOSITE SCORE RELIABILITY
보건의료전문교육(Health Professions Education, HPE)에서는, 교수자들이 여러 다양한 측정치(measures)를 바탕으로 합성 점수(composite scores)를 산출해야 하는 경우가 많다. 예를 들어, 한 과목의 최종 성적(course grade)은 지식 성취(knowledge achievement)를 평가하는 필기시험 점수와 임상 수행(clinical performance) 평정 점수를 합산하여 산출될 수 있다. 최종 성적은 대개 과목에서 부여되는 가장 중요하고 중대한 점수이므로, 그 신뢰도를 정확히 평가하는 것이 필요하다. 합성 점수 신뢰도(composite score reliability)는 특별한 주제이며, 이를 분석하기 위해서는 전용 소프트웨어(specialized software)가 필요할 수 있다 (Park, Lineberry et al., 2016; Kane & Case, 2004). 부록(Appendix)에서는 공식(formulas)과 함께 구체적인 예시를 제시하므로, 관심 있는 독자는 해당 부분을 참고하길 권한다.
Illustrative Example (예시)
세 가지 평가가 있고, 전문가 교수진의 판단에 따라 가중치(weights)를 부여해 합산한다고 가정하자 (Figure 3.6 참조).

이 예시에서, Rotation 평가 점수(rotation evaluation scores), 필기시험 점수(written assessment scores), 객관구조화진료시험(OSCE, Objective Structured Clinical Examination) 점수에 각각 37%, 30%, 33%의 가중치를 부여했다.
각 평가의 신뢰도 추정치는 0.50~0.60 범위에 있으며, 평가 간 상관관계(inter-assessment correlations)는 0.40~0.65 범위였다. Figure 3.6의 하단 도표는 Rotation 평가 점수의 가중치를 다르게 부여했을 때의 합성 점수 신뢰도 범위를 보여준다.
- 예: Rotation 평가에 50% 가중치를 두고, 나머지 OSCE = 25%, 필기시험 = 25%로 분배하면, 합성 점수 신뢰도는 0.75가 된다.
- Rotation 평가의 가중치를 35%로 조정하고, OSCE와 필기시험을 각각 32.5%로 동일하게 배분하면, 최적 신뢰도(optimal reliability)인 0.77이 된다.
- 그러나 Rotation 평가의 가중치를 35% 이상으로 높이면 오히려 합성 점수 신뢰도는 낮아진다.
Implications (함의)
점수를 결합하는 과정에서는 교육적 근거(educational rationale)가 필요하며, 이는 각 평가 요소에 적용되는 가중치의 크기를 결정하는 데 사용된다. 이 요인들은 신뢰도뿐 아니라 타당도(validity)에도 중요한 영향을 주며, 특히 결과적 타당도(consequential validity)에 영향을 미친다.
합성 점수 신뢰도를 극대화하기 위해 가중치를 최적화하는 여러 접근법이 존재한다. 본 장에서는 Kane의 접근법을 사용했으며, 다변량 일반화가능도 이론(multivariate generalizability theory) 역시 널리 사용되는 방법이다 (자세한 내용은 Chapter 4 참조).
SUMMARY
이 장에서는 신뢰도(reliability)의 개념과 그것이 다양한 맥락에서 어떻게 사용되는지를 설명하였고, 신뢰도가 평가 데이터의 적절성과 타당성을 판단하는 데 어떤 도움을 주는지를 보여주었다. 우리는 먼저 신뢰도와 분산(variance)의 관계에 대한 개념적 논의를 제시한 뒤, 고전검사이론(Classical Test Theory, CTT)의 맥락에서 신뢰도의 보다 정밀한 정의를 다루었다. 각 개념은 HPE에서의 예시와 함께 제시되었다.
평가 점수(assessment scores)는 대체로 피험자의 능력이나 수행을 정확히 측정하는 데 방해가 되는 오차(error, noise)를 포함한다. 신뢰도 분석(reliability analysis)은 교육자들이 이러한 오차를 수량화하고, 무작위 측정 오차(random measurement error)를 포함한 점수를 올바르게 해석하고 활용할 수 있도록 돕는다.
신뢰도 분석의 개념적 틀을 제공하기 위해, CTT가 도입되었으며, 이는 총점 분산(total test score variance)을 (1) 참점수(true score), (2) 오차(error) 두 가지 요소로 구분하는 방법을 제시한다. 재현성(replication) 개념이 신뢰도를 설명하는 핵심 틀이라는 점을 강조하였다.
신뢰도의 응용은 측정 오차와 관련해 논의되었다. 측정 오차는 점수가 얼마나 정밀한지를 다루며, 신뢰도가 낮은 평가 점수는 측정 오차가 더 크고, 따라서 점수는 덜 정밀하다. 신뢰도를 향상시키기 위한 전략으로는 문항 추가(adding more items)가 논의되었다.
우리는 신뢰도를 추정하는 다양한 방법을 예시와 함께 검토하였다. 또한, 시험 기반 신뢰도 통계(test-based reliability statistics)와 평가자 간 신뢰도 통계(inter-rater reliability statistics)의 사용에 대한 지침과 함의를 제공하였다. 추가적으로, Spearman-Brown 공식과 합성 점수(composite scores)를 기반으로 한 신뢰도 향상 방법도 제시하였다.
앞서 언급했듯이, 신뢰도(reliability)는 타당도(validity) 논증의 한 요소이다. 따라서 평가의 신뢰도는 총괄적 의사결정(summative decisions)을 내리기 위해 평가 점수를 어떻게 활용하고 해석할 것인지(Chapter 5, Statistics of Testing), 그리고 학습에 어떤 영향을 미칠 것인지(Chapter 17, Assessment Affecting Learning)를 결정할 때 반드시 고려되어야 한다.
APPENDIX
Supplement—Composite Scores and Composite Score Reliability
가정: 어떤 기관에서 세 가지 평가(three assessments) 점수를 미리 정해진 가중치(predetermined weights)를 사용하여 합산한다고 하자.
- Working group process (WGP) evaluation: 최종 성적의 37%
- HPI written exam: 최종 성적의 30%
- Standardized patient (SP) exam: 최종 성적의 33%
OBJECTIVE
과목 책임자(course director)는 다음과 같은 질문을 던진다:
- 합성 점수(composite score)의 신뢰도는 얼마인가?
- 학생들의 합성 점수를 어떻게 계산해야 하는가?
WHAT WE KNOW
Reliability of three assessments (세 가지 평가의 신뢰도).
우리는 세 가지 시험의 신뢰도가 다음과 같음을 알고 있다:
- WGP evaluation: 0.58
- HPI written exam: 0.80
- SP exam: 0.50
Correlations between assessments (평가 간 상관관계).
학생 수행 데이터(performance data)를 이용해 평가 간의 연관성(association)을 상관관계(correlations)로 계산하였다:
- WGP evaluation과 HPI written exam: 0.40
- WGP evaluation과 SP exam: 0.50
- HPI written exam과 SP exam: 0.65
Sample student scores (예시 학생 점수).
예시로, 세 명의 “가상(fake)” 학생 점수를 아래에 제시하여 합성 점수 계산을 시연한다.
| Student | WGP Evaluation (37%) | HPI Exam (30%) | SP Exam (33%) |
| 1 | 96.0 | 78.0 | 82.0 |
| 2 | 80.0 | 72.0 | 86.5 |
| 3 | 96.0 | 52.0 | 71.8 |
Note: 괄호 안의 값은 평가별 가중치(assessment specific weight)를 나타냄.
이 문서는 세 학생의 합성 점수(composite scores)와 합성 점수 신뢰도(composite score reliability)를 계산하는 단계별(step-by-step) 가이드를 제공한다. 이 예시에서 사용된 계산은 다음 참고문헌을 기반으로 한다: Kane, M., & Case, S.M. (2004). The reliability and validity of weighted composite scores. Applied Measurement in Education, 17(3), 221–240.
I. CALCULATING THE COMPOSITE SCORE RELIABILITY
세 가지 평가의 신뢰도(reliabilities)는 0.50에서 0.80 사이이다. 일반적으로, 여러 평가를 결합(combining assessments)하면 합성 점수(composite score)의 신뢰도가 높아진다.

Step 1: 각 평가에 할당된 가중치의 제곱합(squared sum of the weights)을 계산한다.
가중치의 제곱을 사용하는 이유는, 우리가 합산하는 것이 가중 분산(weighted variances)이기 때문이다. 분산은 본질적으로 제곱의 성질을 가지므로, 이를 수학적으로 반영해야 한다.
Step 2: 상관관계의 가중합(weighted sum of the correlations)을 계산한다.
Step 3: Step 1과 Step 2의 합을 구한다.
이는 합성 점수의 총분산(total variance)이다.
=Step 1+Step 2=0.335+0.340=0.675
Step 4: 각 평가의 신뢰도와 가중치 제곱을 곱한 뒤, 이를 합한다.
Step 5: Step 4의 결과와 Step 2의 결과를 합한다.
이는 합성 점수의 참분산(true variance)이다.
=Step 4+Step 2=0.205+0.340=0.545
Step 6: Step 5의 결과를 Step 3의 결과로 나눈다.
신뢰도의 정의에 따르면, 신뢰도는 총분산(total variance) 중 참분산(true variance)이 차지하는 비율이다.
Reliability=true score variancetotal score variance=0.5450.675=0.807≈0.81
결론
이 계산에 기반하여, 세 가지 평가의 합성 점수 신뢰도(composite score reliability)는 0.81이다.
이는 세 평가를 결합했을 때, 충분한 신뢰도를 가진다는 것을 의미한다.
II. CALCULATING THE COMPOSITE SCORES OF THE THREE EXEMPLAR STUDENTS
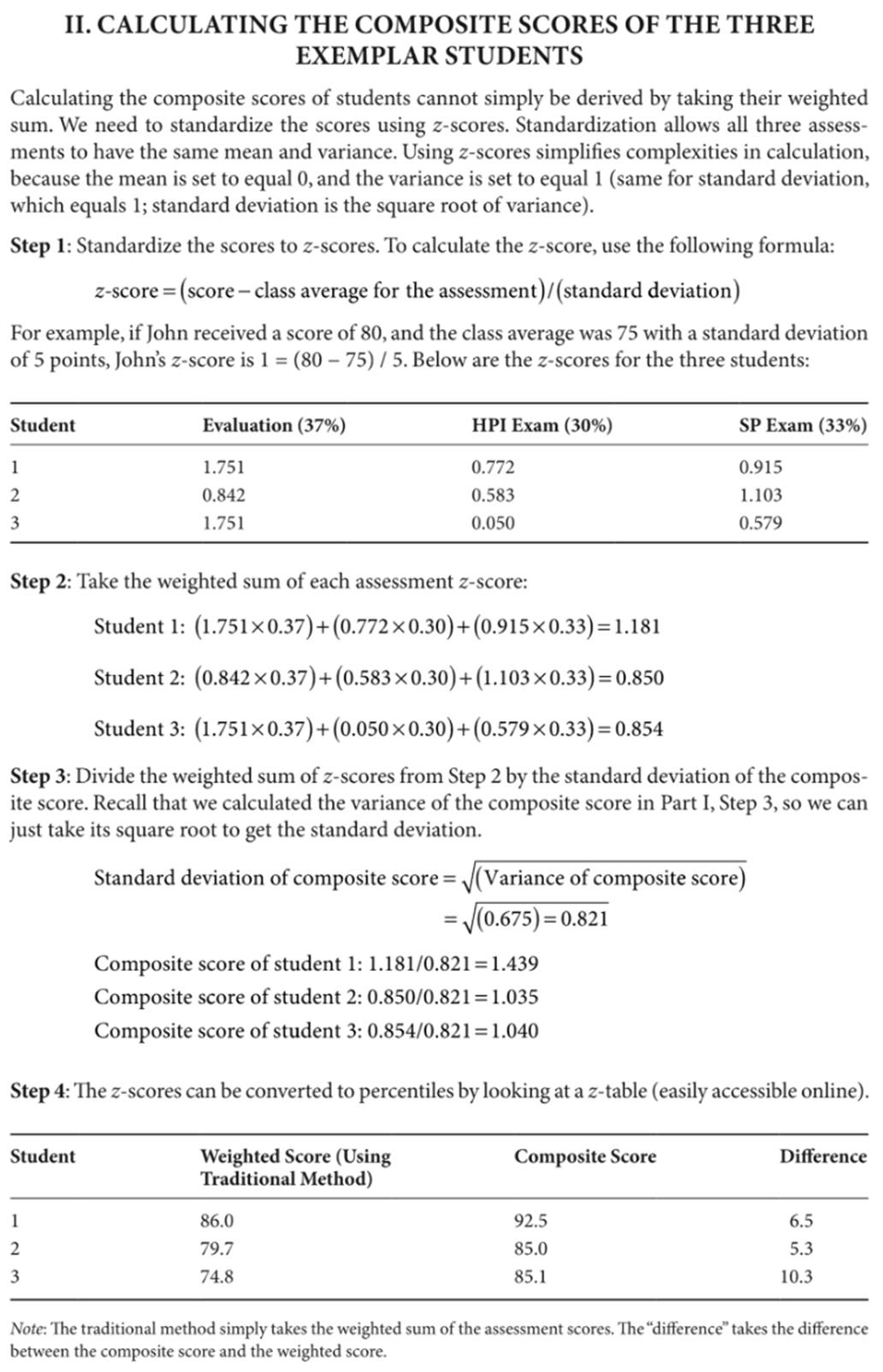
세 명의 학생의 합성 점수(composite scores)를 계산할 때, 단순히 가중합(weighted sum)만으로는 정확하지 않다. 따라서 점수를 z-score(표준점수)로 표준화해야 한다. 표준화를 통해 세 가지 평가 모두 동일한 평균(mean)과 분산(variance)을 갖도록 만들 수 있다. z-score를 사용하면 계산의 복잡성이 줄어든다. 왜냐하면 평균은 0으로 맞추고, 분산은 1로 맞추기 때문이다. (표준편차는 분산의 제곱근이므로 역시 1이 된다.)
점수 표준화의 필요성학생의 학업 성취도를 평가할 때, 여러 과목의 점수를 합산하여 합성 점수(composite score)를 만듭니다. 예를 들어, A 학생이 수학 90점, 과학 80점, 영어 70점을 받았고, B 학생이 수학 80점, 과학 90점, 영어 70점을 받았다고 가정해 봅시다.만약 모든 과목의 만점이 100점이라면 단순 합산 시 두 학생의 총점은 240점으로 같습니다. 하지만 실제로는 각 과목의 평균 점수와 **점수 분포(분산)**가 다릅니다. 예를 들어, 수학 시험이 매우 어려워 평균이 60점이었고, 과학 시험은 쉬워서 평균이 90점이었다면, 수학 80점은 과학 90점보다 훨씬 높은 성취도를 의미합니다.
|
Step 1: 점수를 z-score로 표준화한다.
z-score 계산 공식은 다음과 같다: 예: John이 80점을 받고, 반 평균이 75점, 표준편차가 5라면,
세 학생의 z-score는 아래와 같다:
| Student | Evaluation (37%) | HPI Exam (30%) | SP Exam (33%) |
| 1 | 1.751 | 0.772 | 0.915 |
| 2 | 0.842 | 0.583 | 1.103 |
| 3 | 1.751 | 0.050 | 0.579 |
Step 2: 각 평가의 z-score에 가중치를 곱해 합산한다.
- Student 1: (1.751×0.37) + (0.772×0.30) + (0.915×0.33) = 1.181
- Student 2: (0.842×0.37) + (0.583×0.30) + (1.103×0.33) = 0.850
- Student 3: (1.751×0.37) + (0.050×0.30) + (0.579×0.33) = 0.854
Step 3: Step 2의 z-score 가중합을 합성 점수의 표준편차(standard deviation)로 나눈다.
앞서 I장에서 계산한 합성 점수 분산(variance of composite score = 0.675)을 사용해 제곱근을 취한다.
따라서,
- Student 1: 1.181 / 0.821 = 1.439
- Student 2: 0.850 / 0.821 = 1.035
- Student 3: 0.854 / 0.821 = 1.040
Step 4: z-score를 백분위(percentile)로 변환할 수 있다. (z-table 참조)
| Student | Weighted Score (전통적 방식) | Composite Score (z-score 방식) | Difference |
| 1 | 86.0 | 92.5 | 6.5 |
| 2 | 79.7 | 85.0 | 5.3 |
| 3 | 74.8 | 85.1 | 10.3 |
Note: 전통적 방식(traditional method)은 단순히 가중합을 계산한 것이다. Difference는 합성 점수와 전통적 방식 점수 간 차이를 나타낸다.
해석 (Results)
이 예시에서는 합성 점수(composite score)와 전통적 가중 점수(traditionally weighted score) 간에 차이가 있음을 보여준다. 이러한 차이는 학생들에게 보고되는 점수에 기반한 의사결정(decisions)에 영향을 미칠 수도 있다.
'논문 읽기 (with AI)' 카테고리의 다른 글
| [AHPE] 5장 검사의 통계(STATISTICS OF TESTING) (0) | 2025.09.16 |
|---|---|
| [AHPE] 4 일반화가능도 이론 (Generalizability Theory) (0) | 2025.09.15 |
| [AHPE] 2 타당도와 평가의 질 (VALIDITY AND QUALITY) (0) | 2025.09.09 |
| [AHPE] 1 의학교육에서의 평가 소개 (INTRODUCTION TO ASSESSMENT IN THE HEALTH PROFESSIONS) (0) | 2025.09.09 |
| 서사적 정책 프레임워크: 틀릴 만큼 명확할 수 있는가? ( Policy Studies Journal, 2010) (4) | 2025.08.14 |